Basic Info
- 论文全称: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 相关链接:
Introduction
Vision Language Pre-training近些年有不错的进展,但是以往的VLP的预训练任务要么是vision-language understanding,要么是vision-language generation。BLIP在设计预训练任务时,综合考虑了这两方面的预训练任务。BLIP另一大亮点就是对数据的处理,vision-language领域的数据集,人工标注且效果好的数据不多,所以作者提出了一种CapFilt的Bootstrapping方法来过滤掉不好的标注,扩充image-text pair数据。论文主要有两大贡献:
- Multimodal mixture of Encoder-Decoder(MED),一种新的预训练框架,综合考虑了understanding任务和generation任务
- Captioning and Filtering(CapFilt),一种数据集自举的方法,微调预训练的MED,并分为两个子模块,captioner用来将web获取的图片标注,filter用来将noisy的image text pair去除
Model Architecture
模型的主题架构如下:
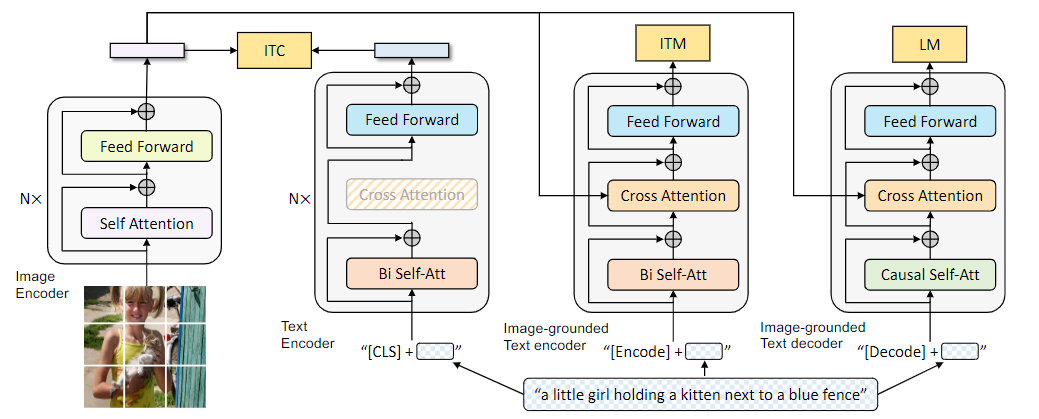
作者设计了三种不同的子架构:
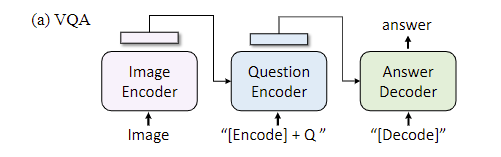
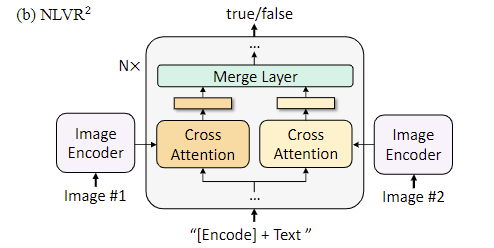
- unimodal encoder: 上图左侧的两个架构,针对单一的text或者image的encoder,对于text而言就是BERT的encoder,对于image而言就是ViT的encoder,同样用<cls>特殊编码来表示sentence的全局信息
- image-grounded text encoder: 上图中间的架构,针对text而言,不同之处是加上了image encoder后的cross attention,所以是image-grounded。text的开头加上特殊字符<encode>,代表image-text pair的多模态表示
- image-grounded text decoder: 上图最右侧的架构,除了和image encoder的cross-attention外,还用causal self-attention替换了bidirectional self-attention,causal attention具体是什么,可以去看causal attention for vision-language tasks这篇论文。特殊字符<decode>用来表示序列的开始,除了self-attention层外,和image-grounded text encoder共享参数
MED这种架构的主要作用就是服务于预训练任务:
- image-text contrastive loss(ITC): 应该和CLIP的任务类似,对齐特征空间中的image编码表示和text编码表示,属于vision-language understanding任务
- image-text matching loss(ITM): 判断vision和language是否匹配,二分类任务,属于vision-language understanding任务
- language modeling loss(LM): vision-language生成任务,自回归,给定序列的开头和图片的编码,输出完整的caption
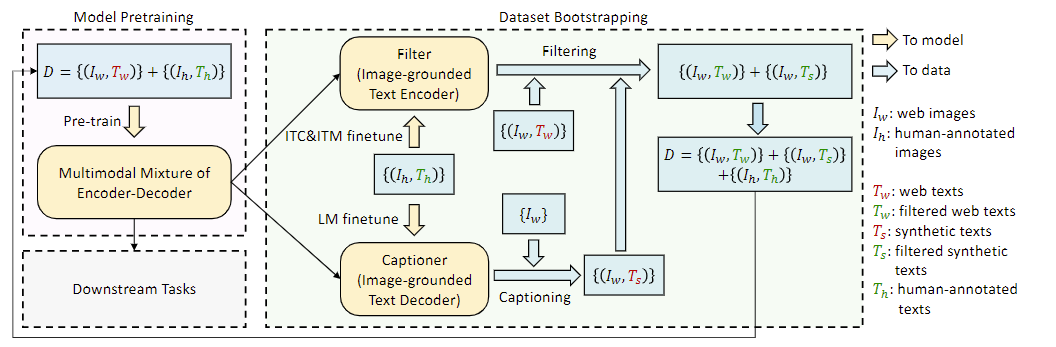
CapFilt
正如前文所介绍,CapFilt的主要目的是筛除noisy的pair,因为从web上爬取的image-text pair质量太低。CaoFilt利用预训练的MED架构,抽取出两个子模块Captioner和Filter,Captioner就是MED的image-grounded text decoder部分,用来对web的图片进行标注,然后我们就获得了新的pair。Filter就是MED的image-grounded text encoder部分,原本那部分的预训练任务是ITM,用来当作过滤器很合适,这样就可以筛除noisy的pair,从而达到扩充数据集且数据集质量高的效果,下图清晰的介绍了这个过程:
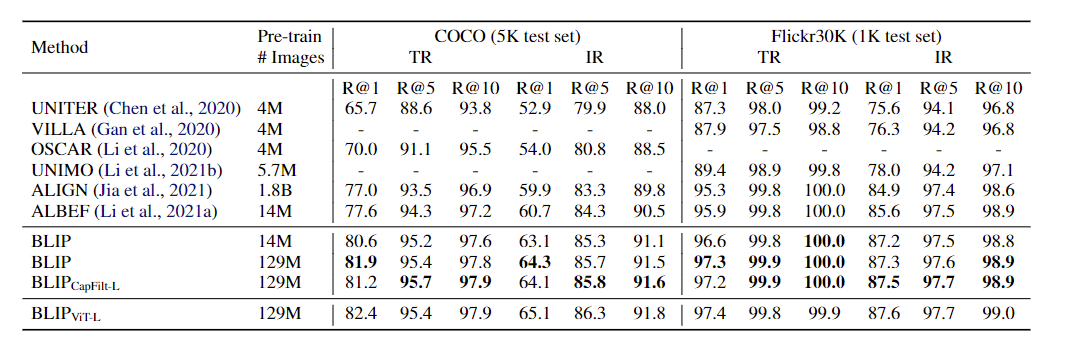
Experiments and datasets
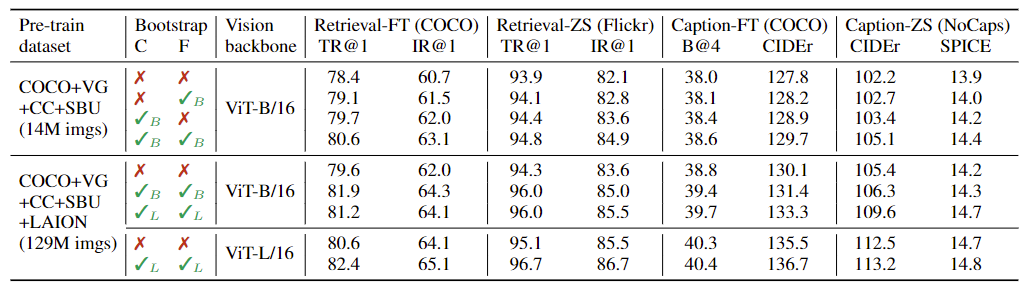
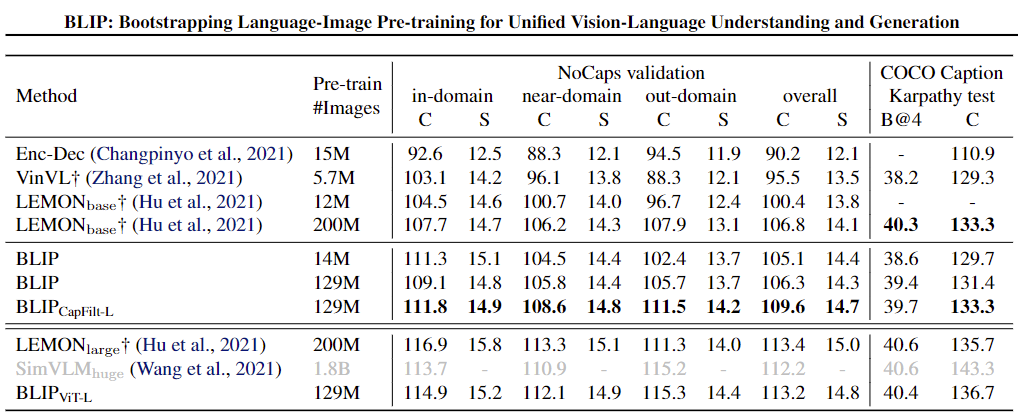
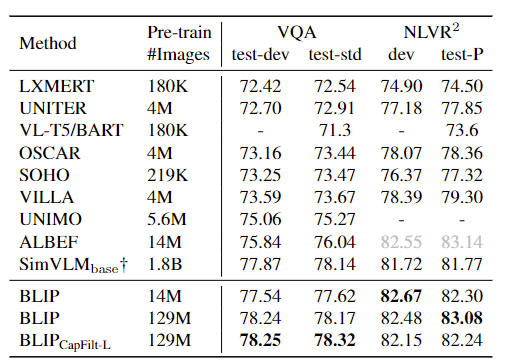
CapFilt的效果:
数据集:
- 两个人工标注数据集: COCO和VG(Visual Genome)
- 三个从web爬取的数据集: CC(Conceptual Captions), SBU, LAION
生成caption的方法:
- nucleus... read more


Comments