0. 简介
- 《动手学深度学习》的笔记
- 各种链接:
- 这本书笼统的介绍了深度学习所需要的各种知识,从线性神经网络开始讲起,然后到CNN,最后到RNN,介绍了CV和NLP领域的较新的网络结构。同时这本书不止有理论内容,每一小节都有代码实践内容,可以边写代码边了解知识,同时bilibili上有李沐老师的网课配合学习,很适合初学者进行学习。
1. 预备知识
这一章主要介绍了深度学习的一些前置知识,这里对比较重要的点做备注
- 张量(Tensor)包含了一维张量(向量)和二维张量(矩阵)
- torch中A*B是哈达玛积,表示矩阵元素按元素相乘
- torch.dot()是点积
- torch.cat(…, dim=0)表示在行上延伸,比如(3, 4)和(3, 4)变成(6, 4)
- A.sum(axis=0)表示把每一列的数据都相加,比如(5, 4)变成(4)
- 范数是norm,L1范数为每个元素的绝对值相加,L2范数为元素的平方和开根号,torch中默认L2范数,一般也是L2范数用的最多
- 梯度: 连接多元函数的所有偏导数:
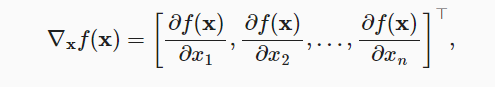
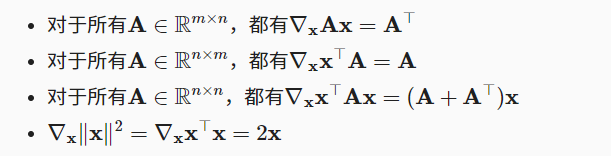
- torch中自动求导的步骤:
- 第一步 为x分配内存空间: x.requires_grad_(True)
- 第二步 链式反向传播,希望求哪个函数的梯度,就对那个函数反向传播,比如y.backward()
- 第三步 求x的梯度,x.grad,如果我们需要重新求梯度,需要清零梯度,x.grad.zero_()
- 注意torch中只能对标量输出求梯度,所以常见操作是sum
- 标量对向量的偏导是向量,向量对向量的偏导是矩阵
- 贝叶斯公式: P(A|B)P(B)=P(B|A)P(A)
2. 线性神经网络
本章主要介绍了线性回归网络和softmax回归网络,接下来是一些笔记
- 随机梯度下降和梯度下降的区别: 梯度下降一般而言是针对所有的样本而言,而随机梯度下降是针对单个样本而言,同样地,小批量随机梯度下降是针对一个批量的样本而言
- 可以调整但是在训练过程中不更新的参数叫做超参数
- 极大似然法: $\theta$是需要估计的值,在写似然函数时只需要把$\theta$看成参数,最大化似然函数即$\theta$的估计值
- 每个输入与每个输出相连的层成为全连接层
- with torch.no_grad()的作用是让输出结果之后不构建计算图
- 本章的训练过程: 计算y的预测值->计算损失函数->累加loss并反向传播(记得每个批量在梯度更新前需要清零梯度并反向传播loss)->更新参数
- 训练过程中重要的组成部分: 数据迭代器、损失函数、优化器(updater/trainer)、网络(记得初始化参数)
- softmax为分类服务,softmax本质上是将输出规范成概率数值,方便选取预测概率最大的类作为预测类:

- 分类的标签可以用独热编码定义
- 网络模型用nn.sequential()定义
- softmax回归的损失函数可以用极大似然法推出,普通的极大似然法是最大化似然函数,但是在这里我们加上-log就变成了最小化损失函数
- softmax回归的损失函数是交叉熵损失:
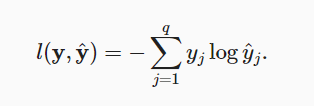
3. 多层感知机
本小节主要介绍了多层感知机的实现以及面对各种问题的解决方法,比如解决过拟合的权重衰退(weight decay)和暂退法(dropout),解决梯度爆炸与消失的Xavier初始化。
- 激活函数的作用是将线性网络变成非线性,常见的有ReLU、Sigmoid、tanh
- ReLU: max(x, 0)
- Sigmoid: $\frac{1}{1+e^{-x}}$
- tanh: $\frac{1-e^{-2x}}{1+e^{-2x}}$
- 在torch中可以用@来简单表示矩阵乘法
- 用nn.Sequential()来实例化网络时,nn.ReLU()单独算一层
- 过拟合问题可以用正则化技术解决,比如权重衰退
- 权重衰退就是L2正则化,它在计算损失函数时增加了权重的惩罚项,比如L($\omega$, b)+$\frac{\lambda}{2}$||$\omega$||,其中$\lambda$是超参数
- torch框架中把权重衰退放在优化器的实例化中(torch.optim),只需要将weight_decay的超参数输入即可
- 暂退法(Dropout): 在前向传播中,计算每一内部层的同时注入噪音,就好像在训练过程中丢弃了一些神经元
- 中间层活性值:
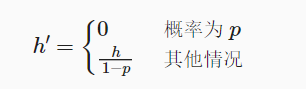
- 只有在训练过程中才有权重衰退和暂退法
- 在torch中简单实现dropout的方法: 在构建net时将nn.Dropout(dropout)加入nn.Sequential(),其中dropout作为丢弃概率输入Dropout中
- 网络架构顺序: linear->relu->dropout
- torch中实现tensor对tensor求梯度的方法是在backward()里面加入torch.ones_like()
- 不正常的参数初始化可能会导致梯度爆炸和梯度消失
- Xavier初始化是解决梯度爆炸和消失的好手段
5. 卷积神经网络
这章主要介绍了CNN的基础知识,包括卷积计算以及汇聚层和简单的卷积神经网络LeNet
- 卷积运算即互相关运算,卷积核函数沿着输入矩阵滑动计算,一般的卷积层除了核运算外,还需要加上偏置
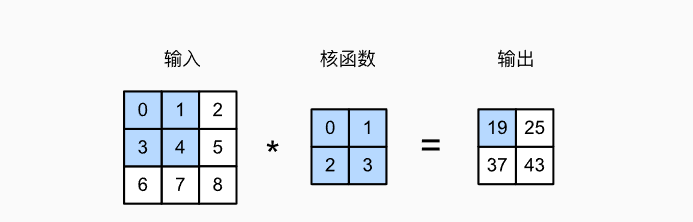
- 二维卷积层的输入格式: (批量大小, 通道数, 高, 宽),卷积层又被称为特征映射(feature map)
- 感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小,也就是一个像素点对应的上一层图像的区域大小
- 填充(padding)与步幅(stride):
- 填充的作用是在输入图像的边界填充元素(通常为0),添加$p_h$行与$p_w$列,基本是一半在左一半在右
- 一般在定义卷积层nn.Convd()时可以加上填充与步幅
- 步幅包括垂直步幅$S_h$与水平步幅$S_w$
- 在经过卷积层后,二维图像变成了$[(n_h - k_h + p_h + 1)/S_h, (n_w - k_w + p_w + 1)/S_w]$
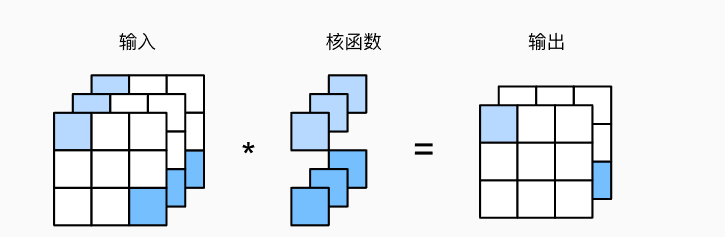
- 多通道输入,只需把各通道输出结果加起来即可
- 多通道输出,为每个输出通道创建一个卷积核函数$(c_i, k_h, k_w)$,假设输入通道个数$c_i$,输出通道个数为$c_o$,那么卷积核形状为$(c_o, c_i, k_h, k_w)$
- torch.stack(): 沿一个新维度对输入张量进行连接
- 汇聚层(pooling)包括最大汇聚层和平均汇聚层,汇聚层是直接返回输入图像的一个小窗口的最大值或者平均值
- 汇聚层没有可学习的参数
- 汇聚层同样有填充与步幅,默认情况下步幅与窗口大小相同,nn.MaxPool2d()
- 每个卷积块的基本单元是: 卷积层->激活函数->汇聚层
- nn.Conv2d(1, 6, kernel_size=5)其中1表示输入通道数,6表示输出通道数
- 在CNN的最后都需要连接全连接层来变成预测类别
- 在训练过程中如果想好好利用GPU,那么需要将网络的参数与数据集数据传入GPU,具体方法是net.to(device)、X,y.to(device)
- 多输入多输出通道的图片示例:
6. 现代卷积神经网络
这一节主要介绍了CNN的各种网络的发展历程,LeNet之后,于2012年出现深度CNN网络AlexNet,之后出现了NiN与VGG,然后是GoogleNet,之后有很大进步的网络是ResNet,直到现在,ResNet用的也很多,残差思想也持续影响后续模型的搭建
- 促进CV有更深的网络的两大关键因素: 数据与硬件(主要是GPU)
- AlexNet(深度卷积网络)于2012年ImageNet挑战赛上夺冠,第一次学习到的特征超越了手工设计的特征
- 相比于LeNet而言,AlexNet更深、激活函数用ReLU、对训练数据进行了增广
- VGG(使用块的网络): VGG块由一系列卷积层(包含ReLU)+汇聚层组成,VGG网络由VGG块组成
- NiN(网络中的网络): NiN块结构是卷积层(含ReLU)+两个1x1卷积层(相当于全连接层),NiN网络结构是: NiN块+汇聚层+NiN块+汇聚层+…+平均汇聚层
- GoogleNet(含并行连结的网络)是google花费了很多money实验出的网络,特点是参数值特殊,参数以及网络结构都是经过了很多实验得出的结果
- GoogleNet中基本的卷积块被称为Inception块,Inception块的架构如下图所示:
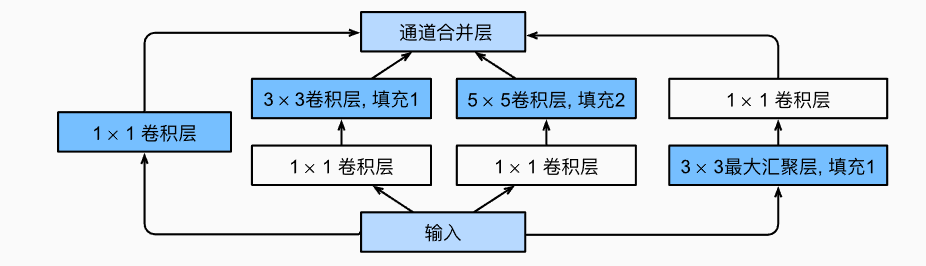
- GoogleNet架构: 卷积块+Inception块+最大汇聚层+Inception块+最大汇聚层+Inception块+平均汇聚层+全连接层
- 批量规范化(Batch Normalization)是一种trick,可加速深层网络的收敛速度
- 正则化在深度学习中非常重要
- 对于一个批量来说,首先规范化输入(减去其均值并除以标准差),再应用比例系数与比例偏移,就是对当前批量进行了批量规范化
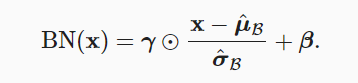
上述式子中x是输入,$\hat{\mu}_B$是这个批量的均值,$\hat{\sigma}_B$是批量的标准差,$\gamma$是比例系数,$\beta$是比例偏移,$\gamma$与$\beta$与x的形状相同,是需要学习的参数
- 应用于全连接层的BN: $h=\Phi(BN(Wx+b))$
- 应用于卷积层的BN: 在每个输出通道的m*p*q个元素上同时执行BN
- 可以发现,BN的作用位置为权重层后,激活函数前
- BN在训练和预测时有所不同,在预测时,直接使用模型传入的移动平均所得的均值与方差
- 用pytorch架构简单实现BN: nn.BatchNorm2d(通道数)
- 直观地说,BN可以使优化更加平滑
- 残差网络ResNet于2015年在ImageNet上夺冠
- 残差思想: 每个附加层都应该更容易地包含原始函数作为其元素之一,残差块不是为了学习输出f(x),而是学习输出与输入的差别f(x)-x
- 残差块的架构:
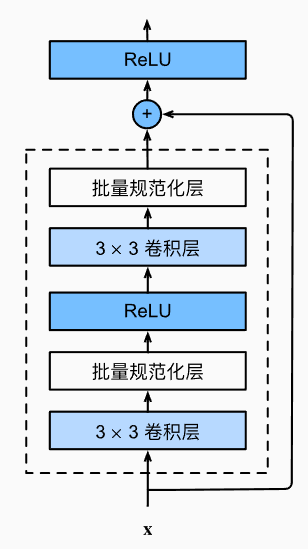
- ResNet的架构: 和GoogleNet很像,就是Inception变成了残差块,同时多了BN
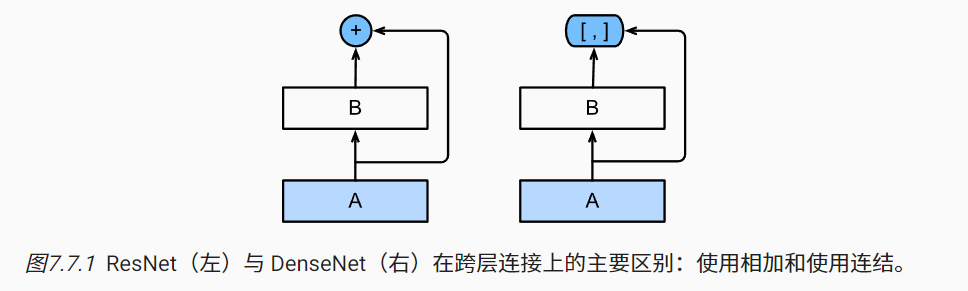
- 稠密链接网络DenseNet: 是ResNet的继承,DenseNet的输出是连结,而不是如ResNet那样的简单相加
7. 循环神经网络
这小节主要介绍了文本数据集如何制作,RNN的网络结构与实现
- 序列数据就是与时间相关的数据
- 马尔可夫模型: 用定时间跨度的观测序列预测$x_t$
- $P(x_1,…,x_T)=\prod_{t=1}^TP(x_t|x_{t-1},…,x_{t-\tau})$
- 一些名词: 文本序列、词元(token)、词表(vocabulary)、语料(corpus)
- 文本预处理过程: 读取数据集成列表->将列表词元化,变成包含多行的词元列表->构建词表(词表将词元与数字对应)
- 文本预处理中的词元可以是单词,也可以是字符,这里采用字符
- 语言模型(language model)的目标是估计联合概率$P(x_1,…,x_T)$
- 涉及一个、两个、三个变量的概率公式分别被称为一元语法、二元语法、三元语法
- zip()的作用是将可迭代对象打包成一个个元组,然后返回元组组成的列表
- 构建文本序列数据集的两种方法:
- 随机采样: 随机选取,特征是原始序列,标签是原始序列右移一位
- 顺序分区: 保证每个批量中子序列再原语料中相邻
- 相比与马尔可夫模型,隐变量模型更能体现过往序列的影响:
$P(x_t|x_{t-1},…,x_1)=P(x_t|h_{t-1})$
- RNN的示意图以及推导公式:
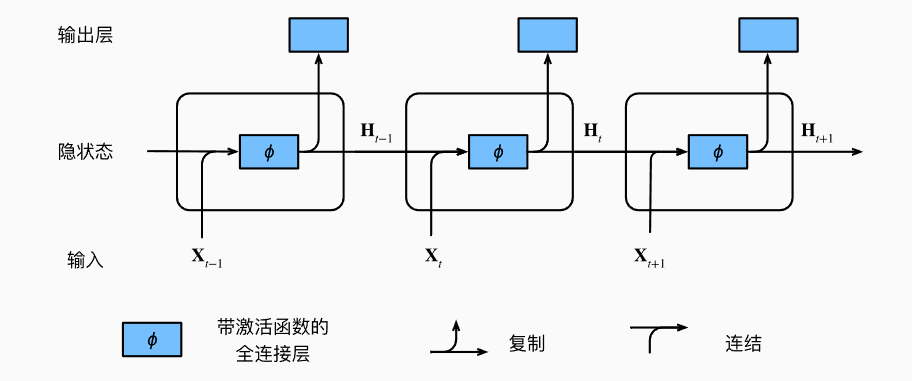
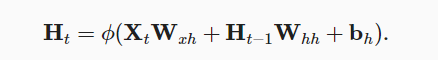
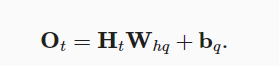
- 循环神经网络中循环的是H(Hidden state)
- 度量语言模型的质量的性能度量是困惑度(perplexity): 一个序列中n个词元的交叉熵损失来衡量语言模型的质量
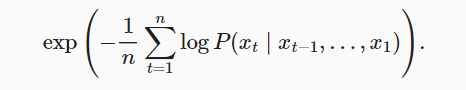
- 最好的情况下,困惑度为1,最差的情况下,困惑度为无穷大
- 独热编码将(批量大小, 时间步数)转变成(批量大小, 时间步数, 词表大小),但为了方便计算,最终转变成(时间步数, 批量大小, 词表大小)
- 梯度裁剪的作用是保证梯度不会爆炸
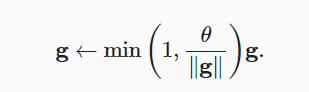
- RNN的网络结构与之前差别不大,只是在更新梯度前需要进行梯度裁剪
- 隐藏状态形状: (隐藏层个数, 批量大小, 隐层参数个数)
- nn.RNN()返回的Y为隐层参数个数,需要再加上全连接层
8. 现代循环神经网络
这一章介绍了拥有记忆单元的LSTM模型,以及后续新的NLP任务机器翻译,介绍了数据集处理过程和编码器解码器结构的网络seq2seq,用来处理序列转换任务
- 长短期记忆网络LSTM(long short term memory)
- LSTM相较于普通的RNN多了很多元素,最主要的设计是记忆单元,它可以影响下一步的隐藏状态:
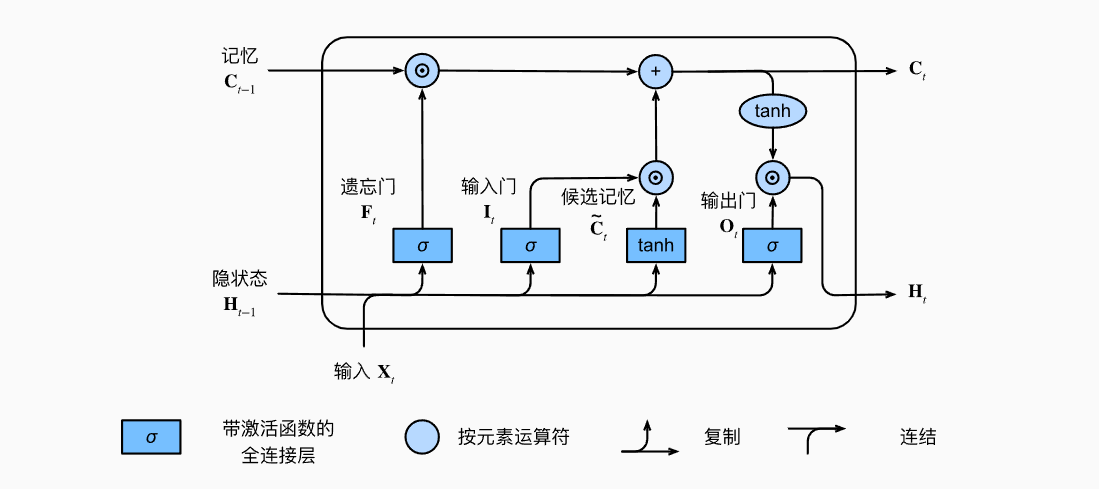
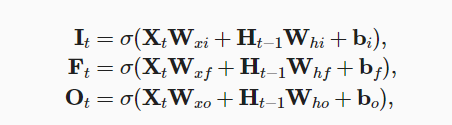
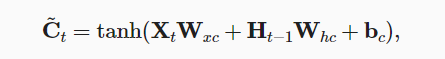
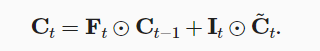
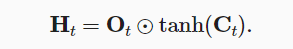
- 输入、输出、遗忘门均与$H_{t-1}$和$X_t$有关
- 记忆单元C类似于隐状态,时时更新
- 总的来说,LSTM中$H_t$与$H_{t-1}$、$X_t$、$C_t$都有关
- RNN的延伸: 多层与双向RNN,其中多层很好理解,就是把单向隐藏层的神经网络变成多层,双向的作用是让序列用到上下文信息,在预测下一个词元的任务中
双向RNN表现不佳,但是在NER中表现很好
- nn.LSTM(num_inputs, num_hiddens, num_layers)
- 接下来的内容变成了机器翻译任务(序列转换)
- 机器翻译中使用单词级词元化
- 机器翻译数据集处理过程: 读取数据集->词元化列表->将数据集分割成source(源语言)与target(目标语言)->序列末端加上<eos>,同时针对长短不一的序列填充<pad>与截断
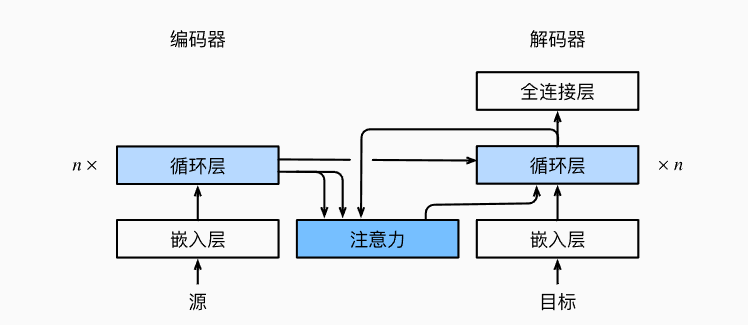
- 处理序列转换任务可以用编码器-解码器结构
- 编码器的作用是将长短可变序列变成固定形状的状态,解码器的作用是将固定形状的状态变成长度可变序列
- 编码器为解码器输入一个状态,在seq2seq中是编码器编码过程中的隐状态,这个隐状态既作为解码器的初始state,在每个时间步中也作为上下文变量和输入concatenate之后一起输入解码器
- 采用嵌入层将词元进行向量化,嵌入层是一个矩阵,(词表大小,特征向量维度)
- 编码器与解码器是两个GRU
- permute()可以改变张量维度的位置
- rnn()的输入形状一般为(num_steps, batch_size, embed_size)
- 解码器的最后同样需要一个全连接层输出
- 解码器的第一个输入为<bos>
- 由于序列存在很多<pad>,计算损失时不能计算pad那一部分,可以mask这一部分,所以损失函数需要重新改一下
- 在seq2seq训练时,解码器net的输入为cat(<bos>,真实序列少一时间步),这种训练机制叫做强制教学
- 预测的时候解码器net的输入仅为<bos>,用每一步的预测作为下一步的输入
- 机器翻译的性能度量为BLEU(bilingual evaluation understudy),可用来预测输出序列的质量,当预测序列与标签序列完全相同时,BLEU为1,公式如下:
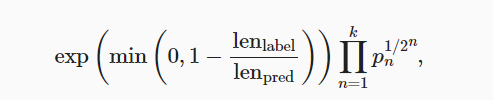
- 编码器的功能主要是为解码器提供上下文变量c和解码器的初始隐状态
9. 注意力机制
这章主要介绍了注意力机制,介绍了注意力机制的组成部分,比如查询、键、值、评分函数,后面又介绍了与RNN结合的Bahdanau注意力以及自注意力和多头注意力,最后介绍了transformer
- 注意力机制的主要成分是查询(query)、键(key)、值(value),q和k交互形成注意力权重,然后与v相乘得到注意力汇聚结果
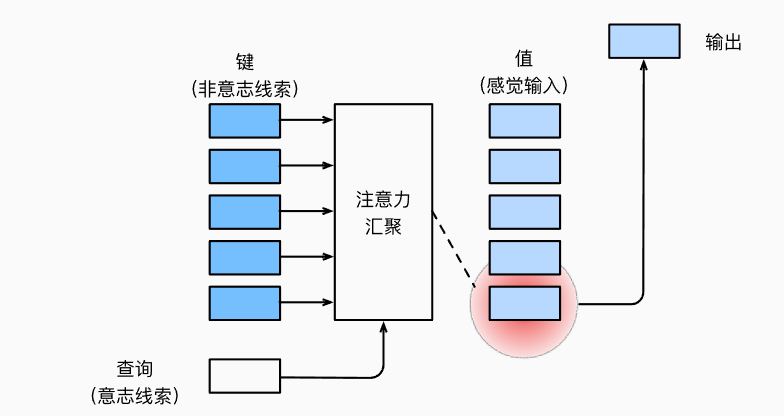
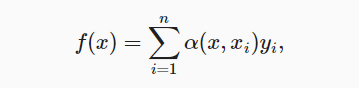
其中x是查询,$x_i$是key,$y_i$是value,$\alpha$的作用是将x与$x_i$之间的关系建模,且权重总和为1,有点像softmax
- unsqueeze()的作用是在指定位置添加一个维度,squeeze()的作用是在指定位置删除一个维度,torch.bmm()是批量矩阵乘法
- 评分函数a同样是对q和k的关系进行建模,q、k、v都可以是向量,而且长度可以不同
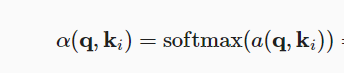
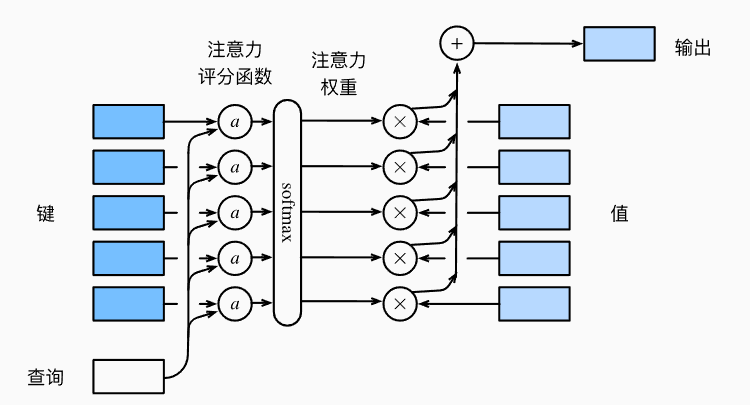
- 这里介绍了两种评分函数: 加性注意力和缩放点积注意力
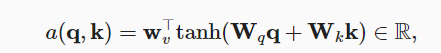
- 缩放点积注意力(计算效率高): 要求q与k长度相同
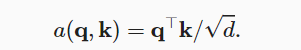
- Bahdanau注意力模型也是编码器解码器结构,与之前的seq2seq不同,这里的上下文变量在解码器的每一步都不相同,上下文变量$c_{t’}$与解码器的上一步隐状态有关,同时在解码器和编码器的输入位置都有嵌入层
- 多头注意力: 对q、k、v使用线性变换并拆分得到h组不同的q-k-v来输入h个注意力汇聚层,得到h个输出,这h个输出concatenate后线性变换得到最终输出
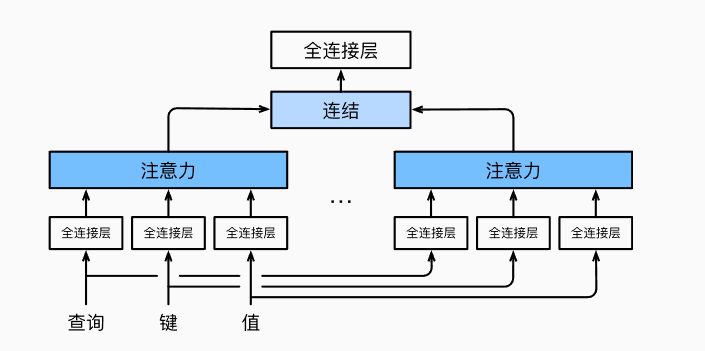
- 自注意力就是q-k-v都是相同的一组元素
- 自注意力无法使用序列的位置信息,可以给输入concatenate一个位置编码,比如X∈$R^{nxd}$表示n个词元的d维嵌入,P∈$R^{nxd}$表示位置嵌入矩阵,那么X+P即输入,位置编码可以基于正弦函数和余弦函数的固定位置编码
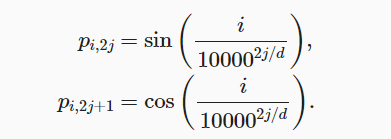
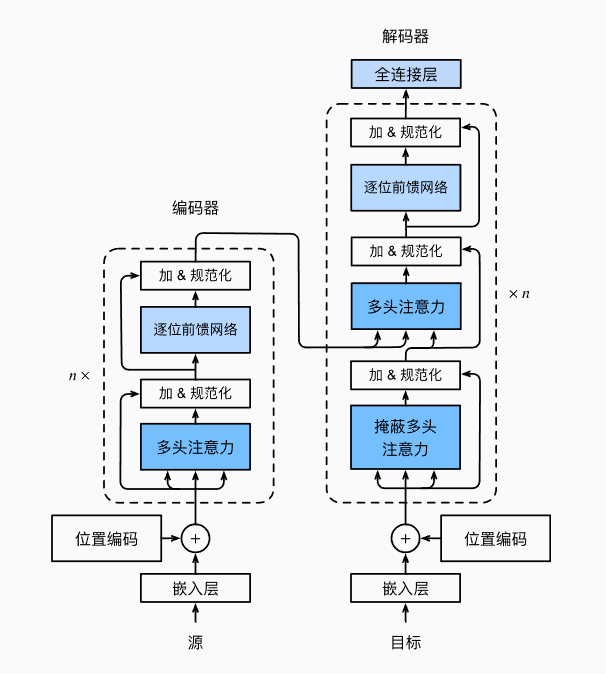
- transformer模型与Bahdanau模型不同,它完全基于注意力机制来构建模型
- transformer每块都由多头注意力和基于位置的前馈神经网络组成,其中还有残差连接,即x+sublayer(x),再层规范化(层规范化和批量规范化类似,都是使得网络中每层输入数据的分布相对稳定,加速模型学习,批量规范化是一组输入数据对一个神经元而言,层规范化是一个输入数据对多个神经元而言)。在解码器的注意力层中,q是上个解码器层的输出,k和v是编码器输出(每个源序列的位置的编码代表一个键值对)。基于位置的前馈神经网络,简称ffn,即两层MLP
12. 计算机视觉
这一章主要介绍了计算机视觉领域的两大任务: 目标检测于语义分割。目标检测从boundingbox讲起,然后介绍如何生成锚框和锚框的标签,然后介绍了SSD、RCNN等实现目标检测的网络,语义分割主要介绍了定义以及网络,最后介绍了风格迁移的一种实现方法
- 就目前的趋势来说,数据集越大,模型的表现效果越好
- 图像增广的作用是扩大数据集的规模,图像增广在对训练图像进行一系列的随机变换后,生成相似但不同的训练样本
- 常见的图像增广的方法有两种:
- 翻转和裁剪: 降低模型对目标位置的敏感性
- 改变颜色(这里指改变RGB): 亮度、饱和度、对比度
- torchvision.transforms.RandomVerticalFlip() 上下翻转
- torchvision.transforms.RandomHorizontalFlip() 左右翻转
- torchvision.transforms.RandomResizedCrop() 裁剪,但最终的图片大小都相同
- torchvision.transforms.ColorJitter()
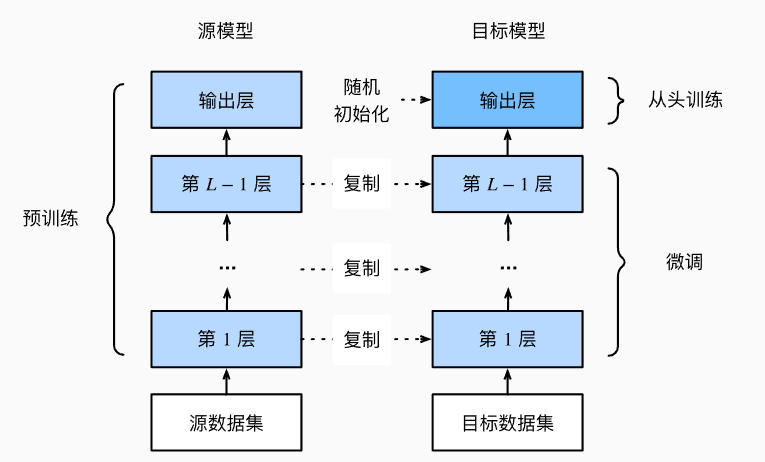
- 微调(fine-tune)约等于迁移学习(transfer learning),从源数据集学到的知识迁移到目标数据集
- 源模型的输出层从头训练,其余层微调,技巧就是让输出层的学习率变大
- torchvision.datasets里包含很多常用的数据集
- torchvision.models里包含很多常用的模型和预训练模型
- 数据集实例化后一般还需要load到内存中变成iterator
- 图像分类只是基础的CV任务,接下来介绍新的CV任务: 目标检测
- 目标检测(object detection/recognition): 不仅想知道类别,还想知道它们在图像中具体位置
- 边界框(bounding box)有两种表示方法:
- 由矩形左上角及右下角的横纵坐标决定(corner表示法)
- 用中心点+高宽表示(center表示法)
- 对于一张图像来说,左上角的点为原点,向右为x轴正方向,向下为y轴正方向
- 锚框(anchor box): 为了预测目标位置,在输入图像中采样大量的区域,然后判断这些区域中是否包含感兴趣的目标,这些区域就是锚框
- 这一节主要关注采样方法,也就是锚框的生成方法,以每个像素为中心,生成多个缩放比和宽高比的boundingbox,这些边界框被称为锚框
- torch.meshgrid()的作用是让输入的两个向量变成网格状矩阵,一个作为x轴坐标,另一个作为y轴坐标
- 交互比IoU: 量化锚框与真实boundingbox的相似性,杰卡德系数的定义如下:
$J(A, B)=\frac{\|A\cap B\|}{\|A\cup B\|}$
对于两个bbox而言,将它们的杰卡德系数称为交互比IoU(intersection over union)
- 如何利用训练集中的标签标注锚框(标注锚框的类别和偏移量): 数据集中含有真实边界框的位置及类别,对于任意生成的锚框而言,可以利用真实边界框的信息去标注锚框,得到锚框的类别和偏移量(offset),其中一种将真实边界框的类别分配给锚框的算法:

简单来说就是先找IoU值最大的一组真实边界框和锚框,然后删除它的行和列,直到真实边界框分配完,然后遍历没有分配的锚框的行,找到IoU最大的真实边界框,然后判断是否大于阈值,只有大于阈值时,才将真实边界框分配给该锚框
- 除了显而易见的锚框的类别,还需要标注锚框的偏移量,偏移量即该锚框与真实边界框的偏移,可以用下面这个式子来表示:
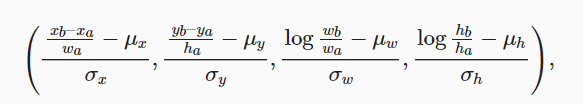
其中$\mu$和$\sigma$都是常量
- 如果一个锚框没有被分配真实边界框,则将它标记为background(即负类锚框)
- 在生成锚框的时候,还会返回掩码,掩码的作用是去掉不关心的负类锚框的偏移量
- 当有许多锚框时,会输出许多相似但有明显重叠的预测边界框,为了简化计算,用非极大值抑制(non-maxmum suppression, NMS)来合并属于同一目标的类似预测边界框。对于一个预测边界框B,目标检测模型会计算每个类别的预测概率。假设最大的预测概率为p,则该概率所对应的类别B即为预测的类别。具体来说,我们将p称为预测边界框B的置信度(confidence)。在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表L。然后我们通过以下步骤操作排序列表L:
- 从L中选取置信度最高的预测边界框$B_1$作为基准,然后将所有与$B_1$的IoU超过预定阈值$\epsilon$的非基准预测边界框从L中移除。这时,L保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。简而言之,那些具有非极大值置信度的边界框被抑制了
- 从L中选取置信度第二高的预测边界框$B_2$作为又一个基准,然后将所有与$B_2$的IoU大于$\epsilon$的非基准预测边界框从L中移除
- 重复上述过程,直到L中的所有预测边界框都曾被用作基准。此时,L中任意一对预测边界框的IoU都小于阈值$\epsilon$;因此,没有一对边界框过于相似
- 输出列表L中的所有预测边界框
- 由于逐个像素生成锚框太多了,可以有针对性地多尺度生成锚框,检测较小物体时,用小锚框,采样更多的区域,检测较大物体时,用大锚框,采样更少的区域
- 目标检测数据集领域里,没有小型数据集,所以李沐团队自行标注了1000张大小角度不同的banana图像,然后在一些背景图片上的随机位置放一张香蕉的图片,然后为这些图像标记边界框和类别
- batch[0]图片(x): (批量大小,通道数,h,w)
- batch[1]标签(y): (批量大小,m,5)
- 上面式子中m表示所有图片中最多可能出现的锚框数,如果一张图片的锚框数少于m个,用非法锚框填充(类别为-1)
- 5表示边界框的信息,分别为类别, $x_min$, $y_min$, $x_max$, $y_max$
- 单发多框检测SSD(single-shot detection)的模型如下图所示:
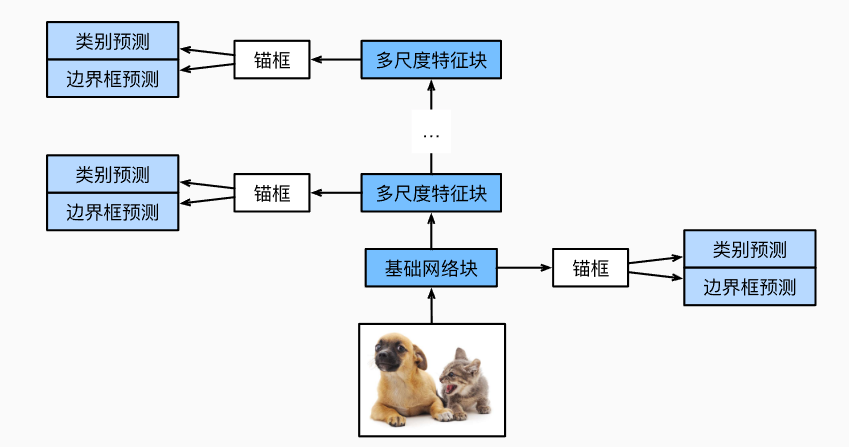
- 模型由基础网络(比如VGG、ResNet等等)和多尺度特征块组成,基础网络的输出将高宽扩大,这样就可以生成更多的锚框(可用于检测尺寸较小的物体),然后后续的多尺度特征块将高宽缩小,这样便可以实现多尺度的目标检测,每一层都预测每个锚框的类别与offset,接下来介绍一下类别预测层和offset预测层
- 类别预测层: 用卷积层的通道来输出类别预测的方法,比如一个特征图像素上有a个锚框,则输出a(q+1)个通道
- offset预测层: 与类别预测层的设计思路类似,但每个锚框预测4个偏移量
- 可以通过合并多个通道的预测来实现不同尺度预测的简化
- 网络记录每个块的前向输出Y,生成的锚框anchors以及类别预测结果cls(Y),offset预测bbox(Y),最后合并不同层的anchors(Y)、cls(Y)、bbox(Y)
- 这个网络的损失函数为: 有关锚框类别的损失(用交叉熵),有关正类偏移量的损失(回归问题,用L1范数损失),掩码变量可以让负类锚框与填充锚框不参与计算
- 训练时,真实值来源于Y的标签信息为每个锚框生成的类别和offset,然后用预测出来的锚框的类别和offset进行损失函数的计算
- 预测阶段,输入x,得到anchors,cls_pred,bbox_pred,然后用NMS来去掉相似的锚框,得到最终的预测结果,output的形状: (批量大小, 锚框个数, 6),6代表类别、概率、bbox的四个坐标
- 接下来介绍目标检测的另一类算法: 区域卷积神经网络R-CNN系列(Region-based CNN),模型如下图所示:
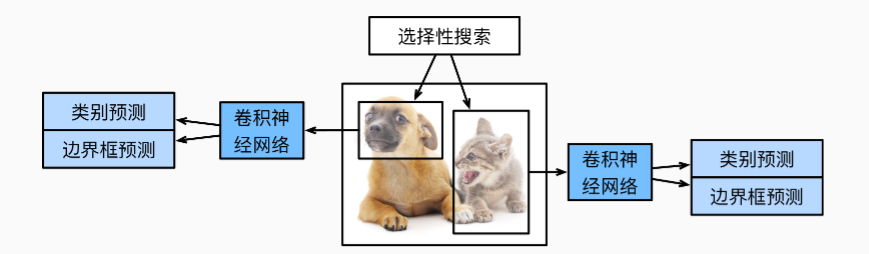
- RCNN的四个步骤:
- 对输入图像选取多个高质量的提议区域,标注其类别和真实bbox
- 选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征
- 将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框
- 庞大的计算量使R-CNN在现实中难以广泛应用,于是出现了Fast R-CNN:
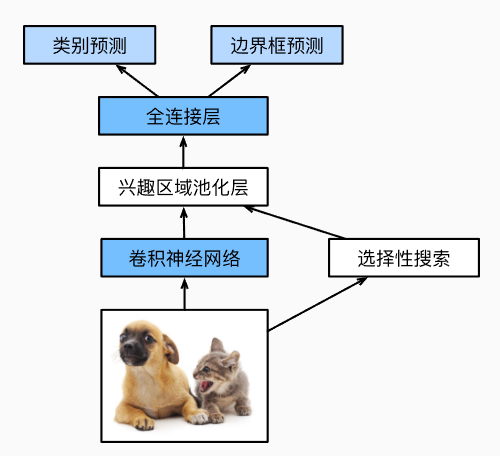
与R-CNN的区别在于,Fast R-CNN在整张图上执行CNN前向传播来抽取特征
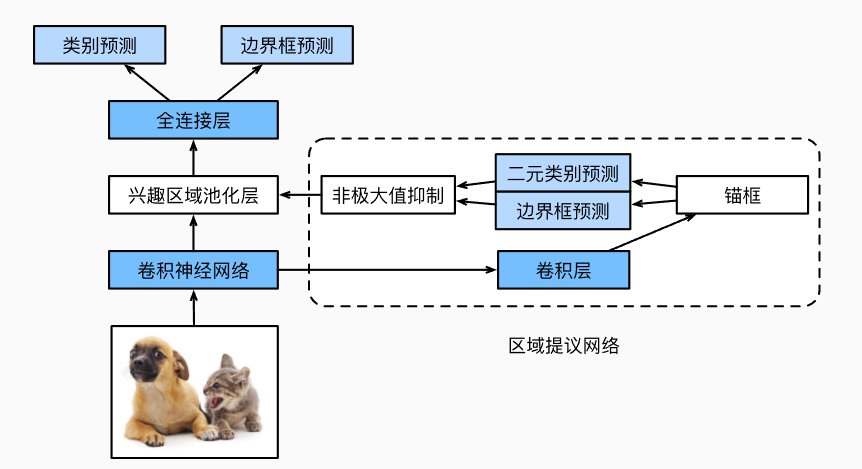
与Fast R-CNN区别在于: 将选择性搜索替换成区域提议网络
- 接下来介绍语义分割任务: 语义分割(semantic segmentation)就是将图像分割成属于不同语义类别的区域(像素级)
- 语义分割数据集: Pascal VOC 2012
- feature x: 图像
- label y: 尺寸与图像相同,但是每个像素的RGB值表示它们所属的类别,类别相同的颜色也相同
- 转置卷积(上采样): 与卷积核运算相反(卷积核运算是用核窗口滑动输入图像)
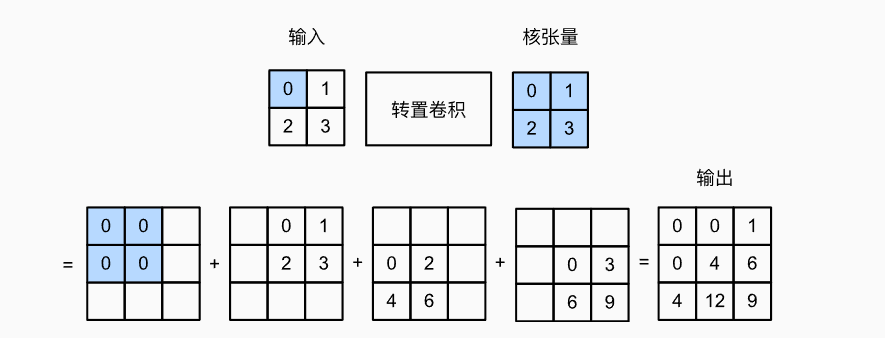
转置卷积是输入图像的每个像素的核函数上滑动,而卷积核运算时用核窗口在输入图像上滑动,转置卷积相当于使图像的高宽变大
- 转置卷积可以通过nn.ConvTranspose2d()简单实现
- 接下来介绍解决语义分割的网络: 全卷积网络(fully convolutional network, FCN)
- 语义分割本质上就是对图像的每个像素进行分类,FCN实现了像素到像素的变换,FCN将中间层特征图的高宽变换回输入图像的尺寸(用转置卷积实现),输出的类别预测与输入图像在像素级别上有一一对应的关系
- FCN模型结构如下图:
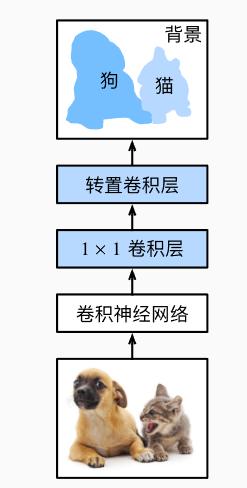
FCN先用卷积神经网络(可以用ResNet)抽取图像特征,然后通过1x1卷积层将通道变换为类别个数,最后通过转置卷积将特征图的高宽变换为输入图像的尺寸
- 转置卷积是一种上采样(upsampling)方法,双线性插值也是上采样方法之一,可以用转置卷积实现双线性插值(通过改变核函数)
- 风格迁移(style transfer): 将一个图像中的风格应用于另一个图像上,即风格迁移,输入是一张内容图像(content)和一张风格图像(style)
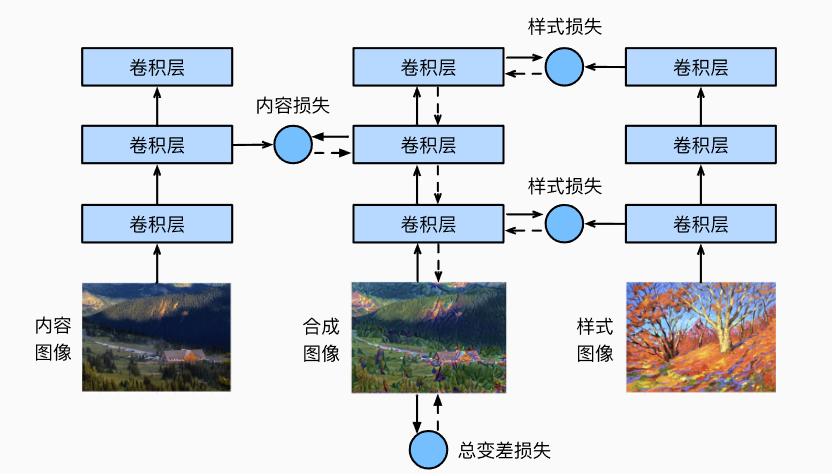
从content中用预训练模型抽取图像的内容特征(不更新参数),从style图像中抽取风格特征,损失函数的设计很有意思
13. 自然语言处理: 预训练
这一章主要介绍了NLP领域的预训练模型,NLP领域的预训练模型都是encoder,即用文本特征来表示词元(一般都是单词),首先介绍了word2vec,然后介绍了全局向量的词嵌入,之后介绍了子词嵌入模型fastText与字节对编码(BPE),之后介绍了BERT(双向Transformer编码器)
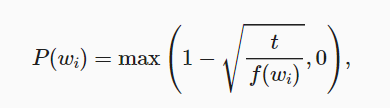
上述式子中f($w_i$)是词在整个语料库中出现的比率,t是超参数。这样高频词就不会太影响模型效果,毕竟不太关注类似a和the与其他词共同出现的概率
- 在下采样与负采样完毕后,一个小批量中第i个样本包括中心词及其$n_i$个上下文词和$m_i$个噪声词,数据集还需要返回mask与label,分别用来遮掩<pad>与标记正例
- word2vec本质上其实是训练一个权重矩阵(词表大小, 嵌入维度),就是一个nn.Embedding()。跳元模型的前向传播就是计算内积矩阵torch.bmm(embed_v, embed_u)
损失函数是带掩码的交叉熵损失
- 跳元模型在预训练完毕后,可以用来找出语义相似的单词,即计算中心词与其余所有词的余弦相似度,计算结果最高的词即为语义最相似的单词
- 无论是word2vec的哪个模型,都着眼于中心词与上下文词的关系
- 全局向量的词嵌入GloVe: word2vec只考虑了局部的上下文词,GloVe则考虑了全局语料库统计来设计模型,训练GloVe是为了降低以下损失函数:
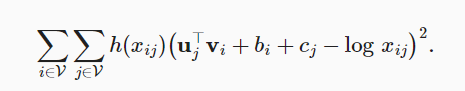
上述式子中,$x_{ij}$是中心词i与上下文词j在一个上下文窗口出现的次数,h($x_{ij}$)是每个损失项的权重,当x小于c时,h(x)=$\frac{x}{c}^\alpha$,当x大于c时h(x)=1,$b_i$与$c_j$是可学习的偏置
- 子词嵌入模型: 对词的内部结构进行研究(比如dog和dogs的关系)
- fastText模型: 每个中心词由其子词的向量之和表示(子词就是单词的某些连续字符)
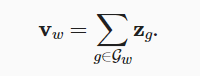
其余部分与跳元模型相同
- 字节对编码(Byte Pair Encoding, BPE): 一种算法,用来提取子词。BPE的本质就是对训练数据集进行统计分析,找出单词的公共符号,这些公共符号将作为划分子词的依据,对于每个单词,都将返回最长的子词划分结果(这样就可以获得任意长度的子词)
- 从大型语料库中训练的词向量可用于下游的自然语言处理任务,预训练的词向量可应用到词的类比性和相似性任务中,比如GloVe和fastText
- torch.topk(k)的作用是返回列表中的最大值(前k个)
- 词相似: 利用余弦相似度
- 词类比: a:b::c:d,比如man:woman::son:daughter,词类比任务就是给出a、b、c,找到d,即让d的词向量尽量靠近vec(c)+vec(b)-vec(a)
- word2vec于GloVe都是上下文无关的,即对于一个词元编码,只需要输入该词元即可
- NLP的六种任务: 情感分析、自然语言推断、语义角色标注、共指消解,NER和QA
- GPT的缺点: 自回归,单向
- BERT使用双向Transformer编码器来编码文本,BERT同样是预训练模型,可以基于双向上下文来表示任意词元
- 针对不同的上下文任务,BERT需要对架构进行微调
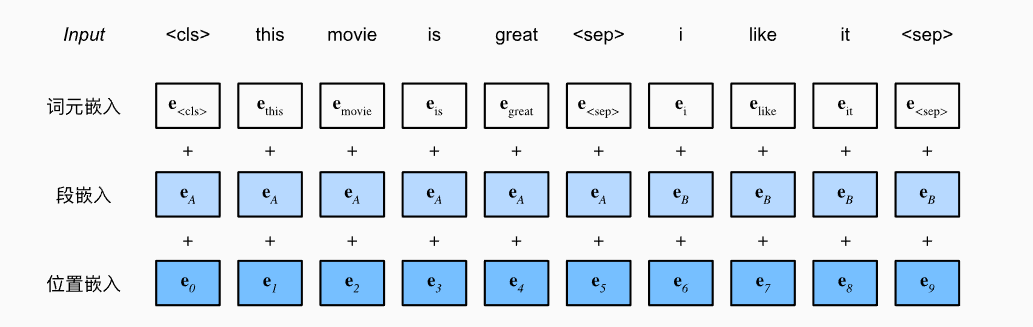
- BERT可输入单个文本,也可以输入文本序列对,当输入单个文本时,BERT的输入序列是<cls>文本<sep>;当输入文本对时,BERT的输入序列是<cls>文本1<sep>文本2<sep>
- 在BERT中,有三个嵌入层,分别是词元嵌入(普通的embedding)、段嵌入(两个片段序列的输入,用来区分不同的句子)和位置嵌入(可学习),之后再把结果输入encoder中
- BERT通过两个预训练任务来优化双向Transformer编码器,分别是掩蔽语言模型(masked language modeling 即填空)和下一句预测(next sentence predicition)
- 掩遮语言模型: 随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。预测阶段使用单隐藏层的MLP来进行预测,输入BERT的编码结果和用于预测词元的位置,然后根据预测词元的位置得到预测词元的编码结果,然后输入mlp中得到预测结果
- 下一句预测: 二分类任务,判断文本序列对是否是连续句子,预测时同样使用MLP,输入编码后的<cls>词元
- 这两个任务在制作数据集的时候都需要加上一些负例或者噪声
- BERT的预训练数据集有很多(针对不同的应用领域,使用不同的数据集进行训练),最开始使用的是图书语料库和wiki
- BERT本质上就是一个双向Transformer编码器
14. 自然语言处理: 应用
这一章主要介绍了如何将自然语言预处理模型应用到下游任务中,首先是传统的GloVe模型和子词嵌入模型,针对这种预训练模型,需要设计特定的网络结构在适配任务,但是BERT的出现,让下游任务应用更简单,有时候只需要加一个全连接层就行,参数也只需要微调,这一章主要介绍了两个下游任务,分别是情感分析和自然语言推断
- 情感分析任务(sentiment analysis): 本质上就是文本序列分类任务,数据集采用Imdb的电影评论集(评论+情感)
- 处理长短不一的序列时,使用截断与填充来预处理数据集,可以将其变成长短一致的序列
- 一般的预训练模型应用于下游任务的方式都是: 预训练模型(词元的文本表示embed)+架构(网络)+应用(各种任务)
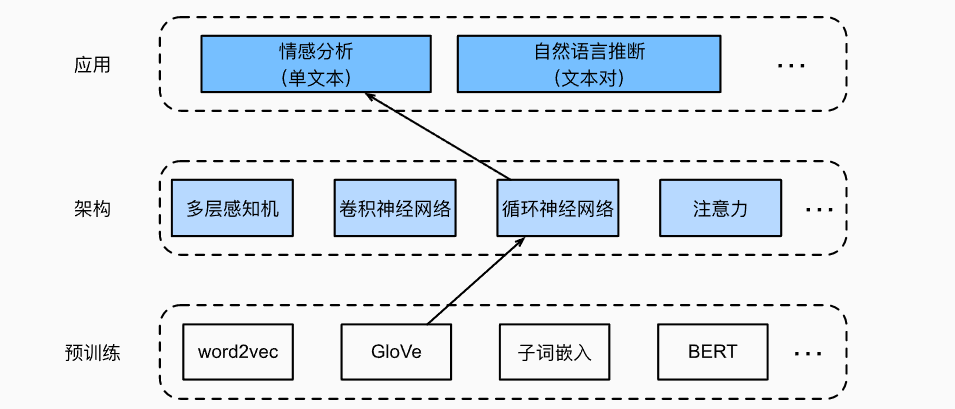
- 这里介绍了两种非BERT的架构,分别是用双向LSTM和CNN来处理情感分析任务:
- 双向LSTM: 双向LSTM的初始与最终步的隐状态连结起来作为文本序列的表示,然后连接一个全连接层,输出
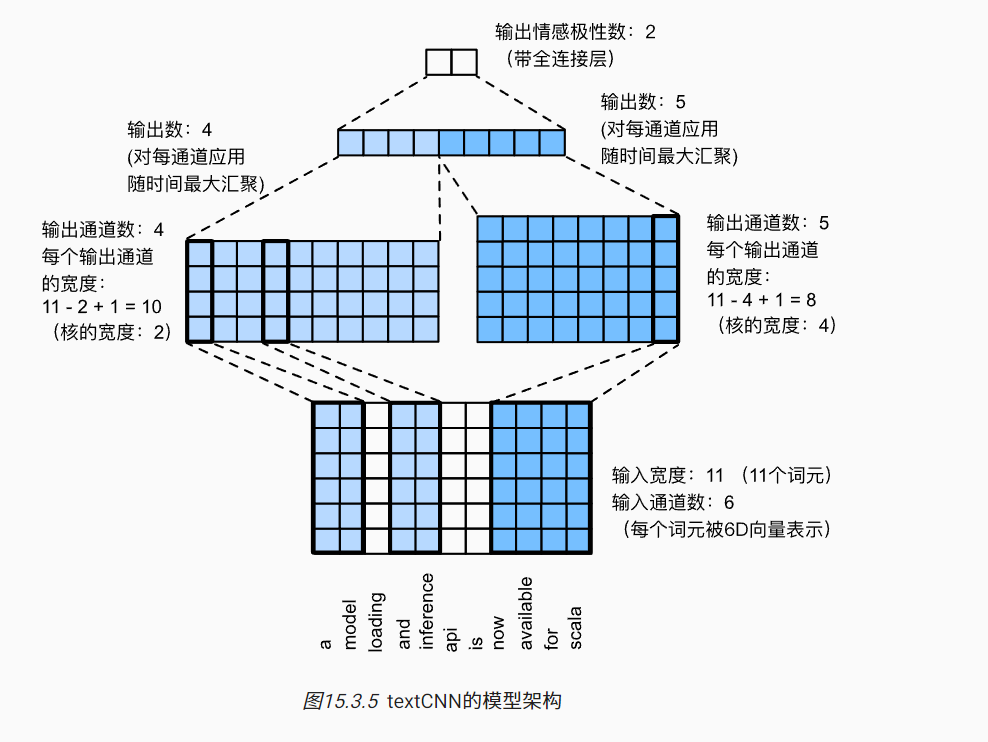
- CNN: 这里使用了一种名为textCNN的网络架构,把文本序列看成一维图像进行处理,采用一维卷积来获得局部特征
- 一维卷积是二维卷积的一个特例,同样是核函数沿着输入滑动。多通道输入的一维互相关等同于单输入通道的二维互相关
- 自然语言推断(nature language inference, NLI)任务是文本对分类任务,对文本对进行判断,决定一个句子能否由另一个句子推断出,即假设(hypothesis)能否由前提(premise)推出
- 两个句子的三种关系:
- 蕴涵(entailment): 假设可以从前提推出
- 矛盾(contradiction): 假设的否定可以从前提推出(我感觉本质上就是假设不能由前提推出)
- 中性(neutral): 所有其他的情况
- NLI使用的数据集是斯坦福自然语言推断数据集(SNLI)
- 接下来介绍两种进行NLI的方法,分别是使用注意力机制(包含MLP)和BERT微调:
- 使用注意力机制: 利用注意力机制将两个文本序列的词元对齐,然后比较、聚合这些信息,那么本质上就是三个步骤:注意、比较、聚合:
- 注意: 与attention机制类似
- 比较: 比较软对齐的hypothesis与premise相比较
- 聚合: 将比较结果concat之后送入mlp
- 这中间涉及到很多mlp层
- 另一种方法就是利用BERT进行微调,后面会具体介绍
- 这种使用非BERT的应用都是将嵌入层的权重替换成预训练模型的权重
- BERT可处理的一些下游任务:
- 单文本分类(比如情感分析、句子在语法上是否可接受)
- 文本对分类/回归(NLI、语义文本相似度)
- 词元级任务: 比如文本标注(每个词元经过相同的全连接层后,返回词性标签)、问答(QA, 使用数据集SQuAD,给定段落与问题后,预测用段落的哪个片段进行回答(也即文本片段的开始与结束位置的预测))
- 加载bert模型时,可以将预训练好的参数直接放到定义好的网络架构中
- 之前很多预训练模型在处理下游任务时,都需要为下游任务设定特定的框架,但是BERT却并不需要设置特定的框架,有时只需要添加一个额外的全连接层即可
- 微调只更新部分参数
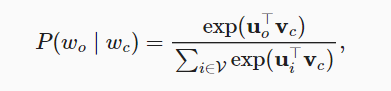
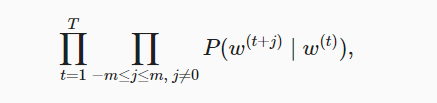
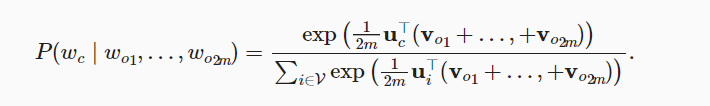
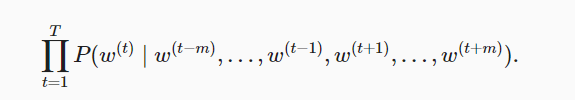
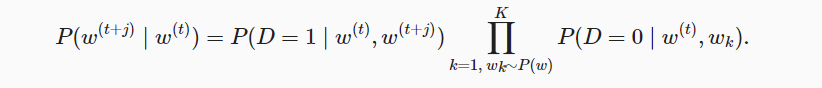

Comments