整理集合
多选题自动生成:
- 定义
输入一篇文章,从这篇文章生成一系列多选题
- 模型结构
待补充
- 工作流程
六大步:
- 输入文章预处理
- 选择句子
- 从句子中选择关键字
- 生成疑问句
- 生成误导选项
- 后期处理
- 主流的研究关注点与现存的问题
- 目前大多数处理文本都不考虑公式、图片和图标等等信息,文本预处理只提取文本信息,今后MCQG的研究需要关注处理嵌入在文本中的信息的能力。
- 现有的MCQ生成方法侧重于从单个句子生成问题,然而,文本可能通过多个句子来生成句子,所以今后的研究应该侧重于从多个句子中生成问题。
- 关键字的选择取决于下游任务或者应用领域,早期的关键字选择依赖于基本的统计和句法信息。最新的研究趋势是使用机器学习或者语义信息作为选择的标准。
- 误导选项的选择同样与应用领域有关,目前的MCQ生成系统中使用的都是简单的误导选项生成,但在实际情况中,误导选项可以是非常多种类的,可以是不同的命名体,数字大小,多个单词的误导选项等等。作者认为文本的深层语义分析或使用基于神经嵌入的方法可能是复杂误导答案生成的一个可能的方向。
一篇关于MCQG的综述
Title
Automatic Multiple Choice Question Generation From Text: A Survey
Author
Dhawaleswar Rao CH and Sujan Kumar Saha


Abstract
MCQ工作20年前已经开始研究,综述将概括目前常见的多选题自动生成的工作流和评估系统。
1.introduction
介绍了MCQ的重要性,是评估知识学习的工具之一,优点是耗时短但是人工出题需要很多时间,所以通过一段文章自动生成问题是人们关注的重点。
2.multiple choice question
介绍了MCQ和MCQ的基本结构,由题干,正确答案和误导答案组成,同时具体介绍了MCQ的优缺点。
| 优点 |
缺点 |
| 快速评估,耗时短 |
涵盖的知识面很小 |
| 可以实现机器阅卷 |
答案有猜测出来的可能 |
3.research motivation and objectives
MCQ的研究动机主要来源于人工出题繁琐且耗时间。
4.review methodology
作者从大量paper中挑选了86篇文章做来做MCQ的综述。
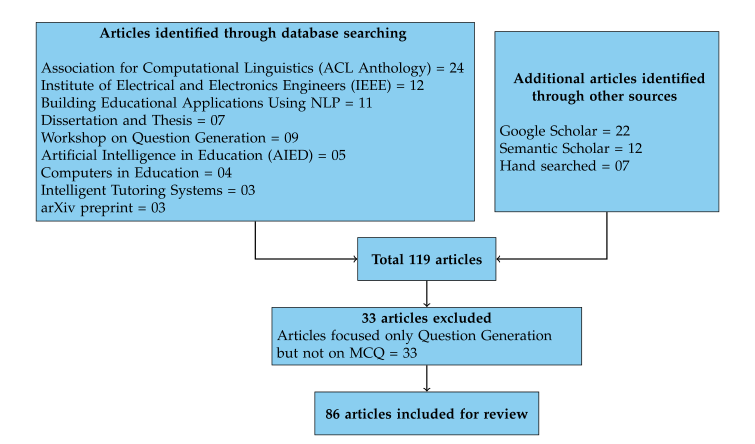
介绍了一下检索文章的步骤
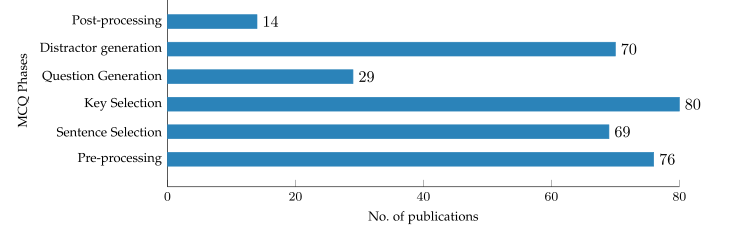
同时介绍了不同的QG的方法分布
5.discussion on the appproaches for MCQ generation
自动生成MCQ和手动生成MCQ的步骤大致相同:
- Pre-processing of Input Text 预处理输入文章
- Sentence Selection 句子选择
- Key Selection 选择答案信息
- Question Formation 问题生成
- Distractor Generation 错误答案生成
- Post-Processing 后期处理
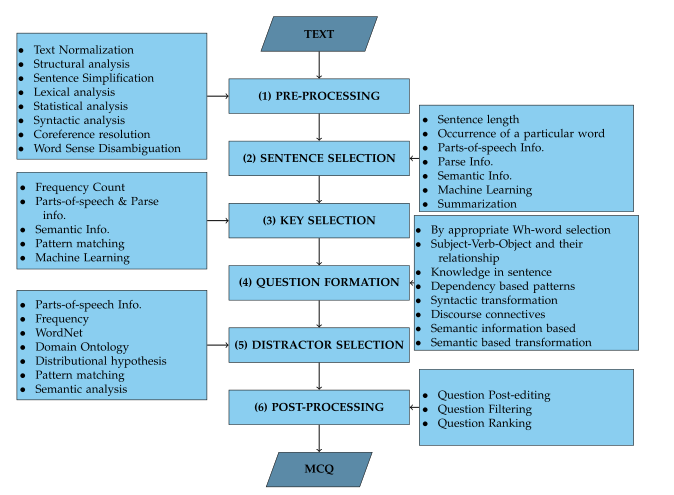
下面从这六个阶段分别分析:
1.Pre-processing of Input Text
- 用到的技巧(每一个技巧都有对应的文献):
- text normalization: 将文本格式变成我们需要的格式,不同的应用领域需要不同的格式化方法
- structure analysis:给出段落结构
- sentence simplification:把长句子变成短句子
- lexical analysis:词汇分析,把文本分隔成单词,符号和数字。同时需要进行词根提取
- statistical analysis:统计分析,包括不同的统计手段,比如词频,n元词频等
- syntactic analysis:语法分析,包括POS,NER,syntactic parsing。
- coreference resolution: 代词通常不作为疑问句的主语,代词解析就是将代词映射到相应的名词。
- word sense disambiguation:消除句子中单词的歧义
作者指出,对于text的预处理主要取决于输入文本的性质和下游任务的需求,比如说从web端爬下的文本会包含很多噪音和没必要的内容,那么文本清理就是必须的,再比如wikipedia文档作为输入时常常是一个长句子,需要把长句子简化变成短句子。
目前大多数处理文本都不考虑公式、图片和图标等等信息,文本预处理只提取文本信息,今后MCQG的研究需要关注处理嵌入在文本中的信息的能力。
2.sentence selection
在对输入文本进行处理之后需要挑选出包含questionable fact的句子,我的理解是那些包含事实的句子。
- 一些技巧:
- sentence length:给出句子中单词的数量,一般来说,很短的句子不能包含足够的信息来生成问题,同样来说,很长的句子通常包含多个事实和关系,这会给生成问题带来困难。
- occurrence of a particular word:查找特殊词汇
- parts-of-speech information: 根据一个句子中出现词汇的词性挑选句子,比如说根据名词-形容词对的出来情况来选择句子。
- parse information: 根据句子结构挑选,比如主谓宾
- semantic information: 文本中包含的语义信息也作为选择句子的标准
- machine learning: 使用机器学习算法,比如支持向量机、神经网络等
- summarization:基于摘要的方法来选择句子
句子的选择同样需要根据任务的不同来选择。现有的MCQ生成方法侧重于从单个句子生成问题,然而,文本可能通过多个句子来生成句子,所以今后的研究应该侧重于从多个句子中生成问题。
3.key Selection
选择好句子后,我们从中挑选出关键词。我们不能将一个句子的全部词汇都作为关键词,因此,关键字的选择是确定句子中要被删除的单词(或者短语、n元词元)
- 一些技巧:
- frequency count: 统计单词的出现频率作为选择标准
- part-of-speech and parse information: 在某些特定的应用领域中,一个特定的词性或者语法可以成为一个潜在的关键字。比如一些研究用动词作为关键字,一些研究用介词作为关键字。
- semantic information: 语义信息。
- pattern matching:模式匹配,从结构相似的句子中提取出常见的句型,这样有助于句子解析结构来寻找关键字
- machine learning:利用机器学习来生成动词或者部分习语或者副词来作为关键字。
关键字的选择同样取决于下游任务或者应用领域,早期的关键字选择依赖于基本的统计和句法信息。最新的研究趋势是使用机器学习或者语义信息作为选择的标准。
选完关键字后,我们下一个任务就是把陈述句转化为疑问句。
- 一些技巧:
- by appropriate wh-word selection: 根据句子的语法结构和关键字来确定使用哪个wh
- subject-verb-object and their relationship:通过主谓宾结构来生成疑问句
- knowledge in sentence:根据句子所包含的知识类型来确定转换规则,例如这个句子是概念,定义,示例等等。
- dependency based patterns: 根据句子的依赖关系树来确定主要动词和将被问及的问题部分
- syntactic transformation:通过句法结构来生成问题。
- discourse connectives:通过不同的关系来转化,比如时间关系,空间关系。
- semantic information based:基于语义来转化。
question generation,问题生成也是一个热门的研究方向,该领域的目标是根据输入文本生成问题。在MCQ中,我们首先选取一个句子,然后选择关键字,最后根据关键字转换成问句形式。
5.distractor generation
错误选项在MCQ中扮演重要的地位,如果错误选项不能很好的迷惑学生,那么这道多选题出的并不好。
- 一些技巧:
- parts-of-speech information:错误选项和关键字在语义上很接近,所以他们的词性也要一样
- frequency:频率也是一个重要的指标,关键字和错误选项的出现频率应该相近。
- wordnet:wordnet是一个词汇数据库,它将单词分组为同义词集并记录这些词集成员的关系。因此可以用wordnet来生成错误选项。
- domain ontology:一些文献用web ontology language来寻找错误答案。
- distributional hypothesis: 分布假设认为相似的词出现在相似的语境中,那么我们可以基于分布相似度来寻找错误答案。
- semantic analysis:基于语义。
错误选项的选择同样与应用领域有关,目前的MCQ生成系统中使用的都是简单的错误选项生成,但在实际情况中,错误选项可以是非常多种类的,可以是不同的命名体,数字大小,多个单词的错误选项等等。作者认为文本的深层语义分析或使用基于神经嵌入的方法可能是复杂错误答案生成的一个可能的方向。
6.post-processing
后期处理是提高生成MCQ质量的阶段,系统生成的MCQ可能存在各种各样的错误。可能是标点符号错误,疑问词不恰当,问句过长等等,后期处理希望消除这些问题。
- 一些技巧:
- question post-editing:有些文献的方法是手动更改, 首先对于问题执行分类,是小问题就更正拼写和标点,如果是大问题就对题干进行重新措辞和替换等等。
- question filtering:有些文献设计了一个过滤器来拒绝不对的问题,有的过滤器主要判断错误选项的质量,有的过滤器基于项目信息来过滤。
- question ranking:对问题进行排名。
6.MCQ system evalutaion
评估MCQ生成好坏,目前大多数系统采用
人工评估的办法。由于MCQ生成包含了很多步骤,那么就产生了不同的度量标准。
-
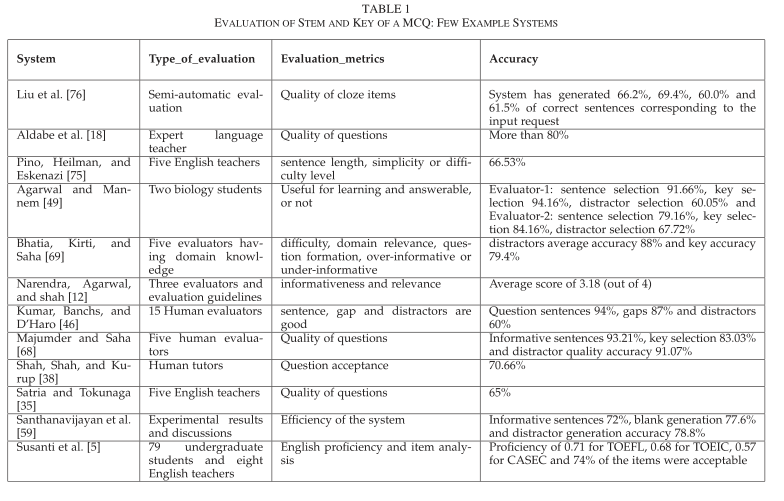
evaluation of the stem and key:
目前还没有标准的公共数据集来评估MCQ,所以一般都是开发人员创建测试数据,下面有一张图展示了MCQ系统的评估过程,从表中可以看出,并没有一个标准的性能度量标准,开发人员采用了各种指标和参数。我们只能比较基于同一套评价体系下的MCQ。
-
evaluation of the distractors:
同样的,错误答案的评估也没有标准的数据集和评估指标。在许多应用领域中,MCQ有大量的干扰因素,所以一个标准的数据集可能无法容纳所有。所以目前还是有相关专家来评估。
7.conclusion
总结了工作流程中的六个阶段,总结了目前的挑战和今后的研究方向,以及评价标准未确立等等。MCQ领域还有很多地方值得深入研究。

Comments