1. AE简介
AutoEncoder,即AE,自编码器,是一类在半监督学习和非监督学习中使用的人工神经网络,其功能是通过将输入信息作为学习目标,对输入信息进行表征学习(representation learning),编码其实就是特征表示
半监督学习(semi-supervised learning)的训练数据一部分是有标签的,另一部分没有标签,而没标签的数量一般大于有标签数据的数量
自编码器的原理如下图所示,encoder首先读取input,将输入转换成高效的内部表示(code),然后再由decoder输出输入数据的类似物
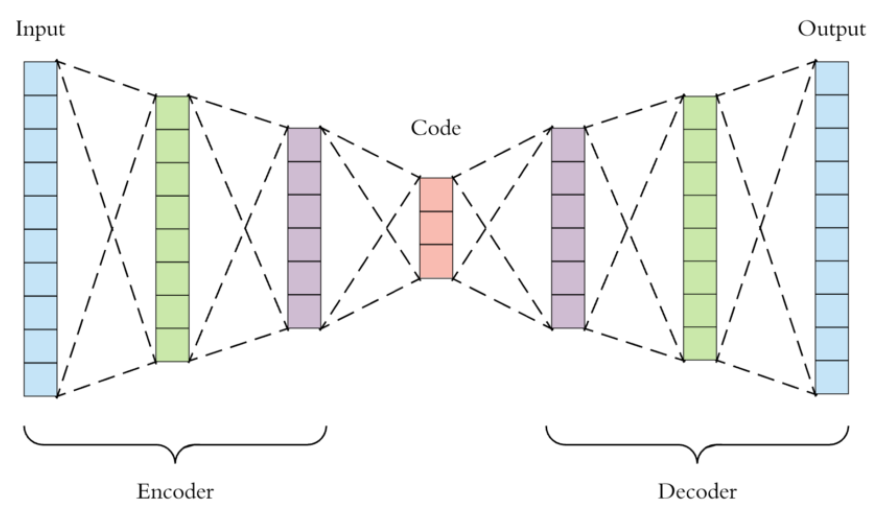
自编码器属于自监督学习的范畴,算法把输入作为监督信号来学习,encoder的作用其实就是对输入向量进行特征降维,常见的降维算法有主成分分析法PCA,但PCA本质上是一种线性变换,提取特征的能力有限
自编码器利用神经网络来学习输入的特征表达,AE利用数据x本身作为监督信号来指导神经网络的训练,即希望神经网络能学到映射$f_\theta$:x->x
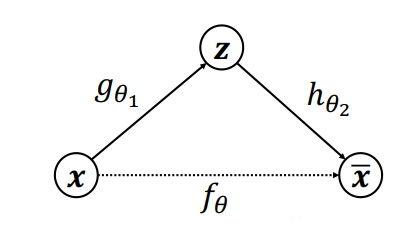
把网络切分为两个部分,前面的子网络尝试学习映射关系$g_{\theta1}:x->z$,后面的子网络尝试学习映射关系$h_{\theta2}:z->x$,即编码器和解码器,编码器和解码器共同完成了输入数据x的编码、解码过程,把整个网络模型叫做AutoEncoder,模型根据输出与输入的距离函数作为损失函数来优化AE,随机梯度下降
假设输入为x,中间层为y,最终输出为z,那么y=s(Wx+b),s是激活函数,z=s(W’y+b’)
接下来我将整理AE家族的一些模型,有DAE、VAE、VQVAE,当然不可能涵盖所有的模型,尽量介绍一些使用较多的模型
2. DAE
通过Auto-Encoder得到的模型往往存在过拟合的风险,为了学习到较鲁棒的特征,可以在网络的输入层引入随机噪声,这种方法称为降噪自编码器(Denoising autoencoder, DAE),为了更了解模型的原理和架构,我去阅读了DAE的论文
作者的想法是让网络从corrputed的输入还原出原始输入,通过这个方法来提高模型的鲁棒性。corrputed的方法: 对于每一个输入x,随机选取$v_d$个元素置零,其他的部分保持不变,那么网络的目标就变成了对这些位置进行填空(fill-in),这和BERT中Masked LM的思想差不多
论文的其他部分着重介绍为什么这种denoising的思想有用以及背后的数学原理
3. VAE
AutoEncoder被指责只能简单地记住数据,在生成数据的能力上很差,于是变分自编码器VAE(Variational auto-encoder)出现了。论文链接
作者提出了一种autoencoding variational bayesian(AEVB)算法,在AEVB算法中,通过使用SGVB(stochastic gradient variational bayes)估计器优化识别模型,使推断和学习更加有效,该识别模型允许我们使用简单的采样来获得非常有效的近似后验分布
3.1. 数学原理
数据集X由独立同分布采样的N个x组成,即$X={x^{(i)}}_{i=1}^N$。我们假设x的生成过程由两部分组成:
- $z^{(i)}$采样自先验分布$p_{\theta*}(z)$
- $x^{(i)}$由似然函数$p_{\theta*}(x|z)$生成
作者说不会对边缘概率分布和后验概率分布做一般的近似假设,所以一些常用的方法可能不行,作者提出用辨别模型$q_\Phi(z|x)$作为真实后验概率$p_\theta(z|x)$的近似,这里的$\Phi$也就是变分参数(variational parameters),variational有两个作用,一个是可以用q(z|x)来近似p(z|x),另一个是优化了lower bound的梯度计算
3.1.1. variational lower bound
通过最大边缘似然函数$p_\theta(x)$来获得参数$\theta$的估计值,对数似然函数log$p_\theta(x)$可写成(x都指$x^{(i)}$):
\begin{equation}
logp_\theta(x^{(i)})=D_{KL}(q_\phi(z\mid x^{(i)})\|p_\theta(z\mid x^{(i)}))+\mathcal{L}(\theta, \phi;x^{(i)})
\end{equation}
推导过程为:
\begin{equation}
\begin{aligned}
logp_\theta(x)&=E_{z\sim q_\phi(z\mid x)}[logp_\theta(x)] \\
&=E_{z\sim q_\phi(z\mid x)}[logq_\phi(z\mid x)-logp_\theta(z\mid x)]+E_{z\sim q_\phi(z\mid x)}[-logq_\phi(z\mid x)-logp_\theta(x, z)] \\
&=D_{KL}(q_\phi(z\mid x)\|p_\theta(z\mid x))+\mathcal{L}(\theta,\phi;x)
\end{aligned}
\end{equation}
等式右边的第一项是KL散度,第二项是Evidence lower bound(ELBO),因为KL散度非负,所以有:
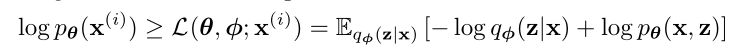
ELBO可以进一步推导,有:
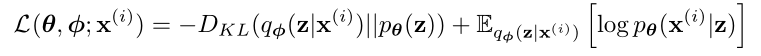
推导和前面类似,省略
我们希望最大化ELBO来获得参数$\Phi$和$\theta$,可以用梯度上升法,然而对ELBO求梯度有点困难,作者提出了SGVB estimator来解决这个问题
3.1.2. SGVB estimator and AEVB algorithm
首先介绍一下蒙特卡洛gradient estimator:

简单来说,蒙特卡洛就是将期望外的梯度符号移到了期望内
接下来我们需要应用一种再参数化(reparameterization)的trick来实现似然函数梯度的计算,具体来说就是服从q(z|x)分布的随机变量z可以写成可微的形式:
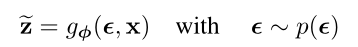
其中$\epsilon$就是噪声,那么再经过一系列的推导,就可以得出似然函数的梯度
AEVB算法:

3.2. VAE模型
VAE是AEVB算法的一个实例,VAE在AEVB算法的基础上做了以下约束:
- 使用encoder来模拟后验分布$q_\Phi(z|x)$,并假设其满足多元混合高斯
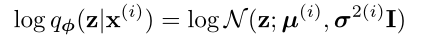
其中$\mu^{(i)}$和$\sigma^{(i)}$是输入$x^{(i)}$经过MLP后得到的结果,模型使用两个网络分别来估计每个样本对应的隐状态$z^{(i)}$的均值和方差
- 假设先验概率$p_\theta(z)$满足多元正态分布模型,即$p_\theta(z)~N(z;0,I)$
- 用decoder来模拟$p_\theta(x|z)$
- 使用重参数的trick来获得z,因为这里假设的是正态分布,所以z可以简单理解成$z=\mu+\sigma * \epsilon$,其中$\epsilon$采样自均值为0,方差为1的正态分布
这样我们就获得了VAE模型
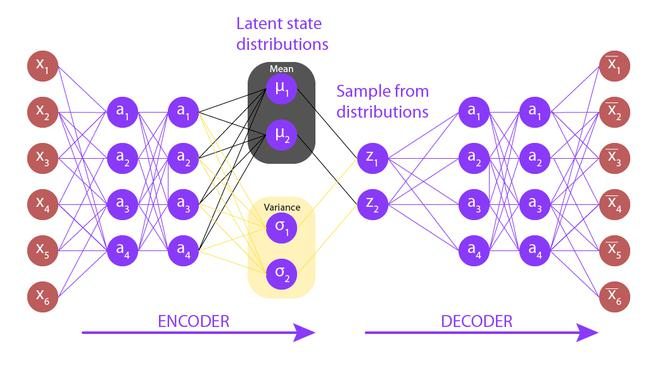
3.3. 总结
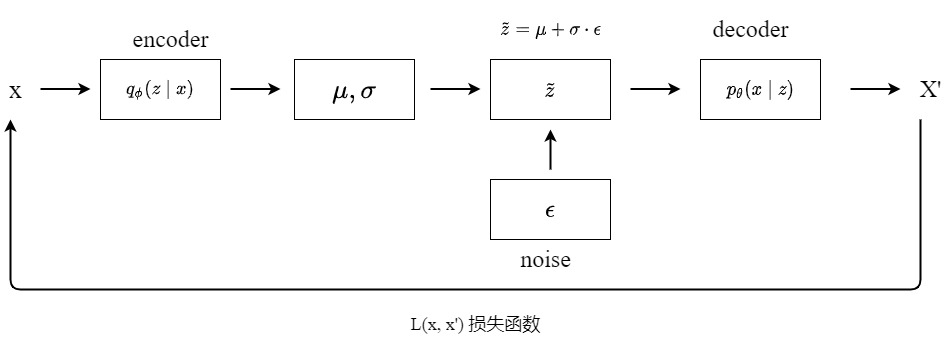
这是我自己画的一张VAE模型图,encoder和decoder可以都是MLP。encoder的目的是从输入数据x中学习到z重参数化需要的变量$\mu$和$\sigma$,之后我们就可以采样噪声来获得z的先验分布,然后经过decoder得到重构的输出x,训练的过程其实就是学习x分布的过程。训练完成后,我们就可以得到生成模型$p_\theta(x|z)p_\theta(z)$,其中$p_\theta(x|z)$就是decoder,先验分布$p_\theta(z)$为正态分布,从先验分布$p_\theta(z)$随机采样一个z送入decoder,就可以得到与训练数据类似的输出,所以VAE是一个生成模型
一篇介绍VAE很详细的博客
4. VQVAE
4.1. 简介
论文链接,VQVAE是DeepMind于2017年提出的一种基于离散隐变量(Discrete Latent variables)的生成模型,相比于VAE,VQVAE有两个重要的区别: 首先VQVAE采用离散隐变量(VAE采用的是连续隐变量),其次VQVAE需要单独训练一个基于自回归的模型(比如PixelCNN)来学习先验概率,而不是像VAE那样采用一个固定的先验分布。VQVAE是一个强大的无监督表征学习模型,它学习的离散编码有很强的表征能力,DALLE第一版就是基于VQVAE的
4.2. VQVAE模型
VQ-VAE的全称是Vector Quantised Variational AutoEncoder,与VAE的主要区别是使用了离散的隐变量和学习出来的prior(非固定)
4.2.1. 离散隐变量
首先定义一个embedding space,记为e$\in R^{K*D}$,K就是embedding space的大小,D就是每个embedding vector的大小,embedding space由K个长度为D的向量组成。
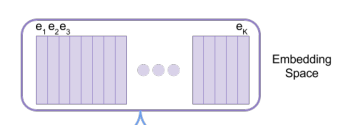
原始输入x经过encoder后变成$z_e(x)$,然后我们需要向量化$z_e(x)$,即把它变成一个向量,这里就需要embedding space发挥作用,我们从embedding space的K个向量中选择一个作为$z_e(x)$向量化的结果,作者的做法是最临近查找(nearest neighbour look-up,即选择欧式距离最小的向量$e_{k}$作为向量化结果),将向量化的结果$z_q(x)$输入decoder:
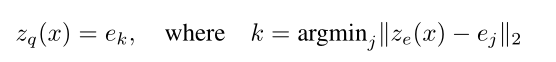
模型在训练过程中需要调整的参数就是encoder的参数、decoder的参数以及embedding space的参数。在训练过程中VQ-VAE其实没有用到先验分布prior,所以后面需要单独训练一个先验模型来生成数据。这里的z对于不同的任务是不同维度的,为了简便,用一维来举例,那么z的后验分布$q(z|x)$可以看成一个多类分布:
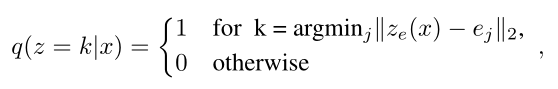
4.2.2. 模型
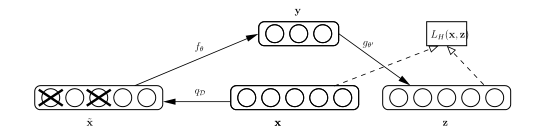
模型如下图所示:
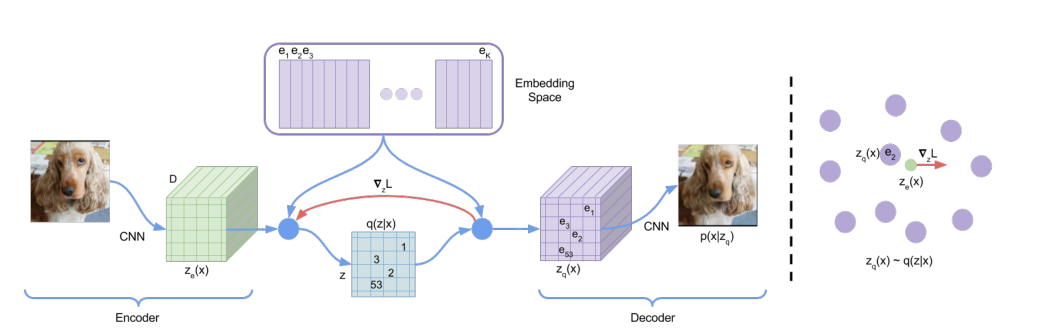
由于上面提到的argmin操作不可导,所以梯度就无法逆传播到encoder,论文采用了一种straight-through estimator的方法来解决这个问题,所谓straight-through estimator其实就是计算梯度时,忽略它而采用上游得到的梯度,在这里,就是用$z_q(x)$的梯度作为$z_e(x)$的梯度。损失函数的定义如下:
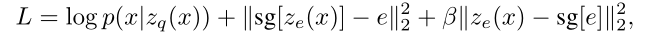
损失函数的第一项是重建误差,它用来优化encoder和decoder的参数,由于在计算梯度时采用了straight-through estimator的方法,所以重建误差不涉及embedding space的参数的更新,为了学习embedding space的参数,用L2误差来移动embedding space的特征向量$e_i$,也就是损失函数的第二项,这里的sg指的时stop gradient的操作,意味着这个L2损失只会更新embedding space的参数,不会传递到encoder。除此之外,论文还额外增加了一个commitment loss(损失函数第三项),其主要目的是约束encoder的输出和embedding space保持一致,$\beta$的取值对算法的效果不会产生很大的影响,论文中取值0.25
关于先验模型prior,在训练VQVAE的主体过程中保持一致,在VQVAE训练完成后,作者为prior训练一个自回归分布p(z),对于z是图片的情况下,用PixelCNN,对于z是音频的情况下,用WaveNet。VQVAE适用于多种模态的数据。embedding space也叫做codebook。
4.2.3. 生成过程
VAE的目的是训练完成后, 丢掉encoder, 在prior上直接采样, 再加上decoder就能做生成。如果我们现在独立地采样HxW个z, 然后查表(codebook)得到维度为HxWxD的$z_q(x)$, 那么生成的图片在空间上的每块区域之间几乎就是独立的。因此我们需要让各个z之间有关系, 因此用PixelCNN, 对这些z建立一个autoregressive model: $p(z_1, z_2, z_3, …)=p(z_1)p(z_2|z_1)p(z_3|z_1, z_2)…$
4.3. VQVAE2
VQVAE2是VQVAE的升级版, 可以生成非常清晰的高分辨率图片. 主要变化就是把VQ-VAE的encoder和decoder进行了分层, bottom层对local feature进行建模, top层对global feature进行建模; 为了让top层能更有效地提取global信息, 在网络中加入了self attention
4.4. 其他
- 知乎上两个讲解很详细的博客:
- VQVAE的特点是可学习的prior和codebook作离散化的设计,影响了很多后续的模型,包括BEiT和DALLE

Comments