短文本自动评估论文阅读整理
- 1. 论文简介
- 2. Automatic Short-Answer Grading via BERT-Based Deep Neural Networks
- 3. Leveraging Semantic Facets for Automatic Assessment of Short Free Text Answers
- 4. Text-to-Text Semantic Similarity for Automatic Short Answer Grading
- 5. Pre-Training Bert on Domain for ASAG
- 6. Imporving Short Answer Grading Using Transformer-Based Pre-training
- 7. Investigating Transformers for Automatic Short Answer Grading
- 8. Superlative model using word cloud for short answers evaluation in eLearning
- 9.Sentence Level or Token Level Features for Automatic Short Answer Grading?: Use Both
- 10. An Experimental Study of Text Preprocessing Techniques for ASAG in Indonesian
- 11. Feature engineering and ensemble-based approach for improving automatic short-answer grading performance
- 12. Machine Learning Approach for Automatic Short Answer Grading: A Systematic Review
- 13. Automatic Short Answer Grading via Multiway Attention Networks
- 14. Automated Short-Answer Grading Using Deep Neural Networks and Item Response Theory
- 15. Comparative Evaluation of Pretrained Transfer Learning Models on Automatic Short Answer Grading
- 16. Going deeper: Automatic short-answer grading by combining student and question models
- 17. Automatic Short Answer Grading With SemSpace Sense Vectors and MaLSTM
- 18. A Semantic Feature-Wise Transformation Relation Network for Automatic Short Answer Grading
- 19. An automatic short-answer grading model for semi-open-ended questions
- 20. Multi-Relational Graph Transformer for Automatic Short Answer Grading
- 21. Automatic Short Answer Grading (ASAG) using Attention-Based Deep Learning MODEL
- 22. Automated Short Answer Grading Using Deep Learning: A Survey
- 23. Survey on Automated Short Answer Grading with Deep Learning: from Word Embeddings to Transformers
- 100. TODO
1. 论文简介
博客主要整理Automatic Short Answer Grading(后续简称ASAG)任务的相关论文,所谓ASAG任务,就是对某个问题的短文本回答进行自动评估,相关论文链接:
- Automatic Short-Answer Grading via BERT-Based Deep Neural Networks
- Leveraging Semantic Facets for Automatic Assessment of Short Free Text Answers
- Text-to-Text Semantic Similarity for Automatic Short Answer Grading
- Pre-Training BERT on Domain Resources for Short Answer Grading
- Improving Short Answer Grading Using Transformer-Based Pre-training
- Investigating Transformers for Automatic Short Answer Grading
- Superlative model using word cloud for short answers evaluation in eLearning
- Sentence Level or Token Level Features for Automatic Short Answer Grading?: Use Both
- An Experimental Study of Text Preprocessing Techniques for Automatic Short Answer Grading in Indonesian
- Feature engineering and ensemble-based approach for improving automatic short-answer grading performance
- Machine Learning Approach for Automatic Short Answer Grading: A Systematic Review
- Automatic Short Answer Grading via Multiway Attention Networks
- Automated Short-Answer Grading Using Deep Neural Networks and Item Response Theory
- Comparative Evaluation of Pretrained Transfer Learning Models on Automatic Short Answer Grading
- Going deeper: Automatic short-answer grading by combining student and question models
- Automatic Short Answer Grading With SemSpace Sense Vectors and MaLSTM
- A Semantic Feature-Wise Transformation Relation Network for Automatic Short Answer Grading
- An automatic short-answer grading model for semi-open-ended questions
- Multi-Relational Graph Transformer for Automatic Short Answer Grading
- Automatic Short Answer Grading (ASAG) using Attention-Based Deep Learning MODEL
- Automated Short Answer Grading Using Deep Learning: A Survey
- Survey on Automated Short Answer Grading with Deep Learning: from Word Embeddings to Transformers
2. Automatic Short-Answer Grading via BERT-Based Deep Neural Networks
2.1. Abstract
Automatic short-answer grading(ASAG),即自动短文本评分任务,是智慧辅导系统的重要组成部分。ASAG目前还存在很多挑战,作者提出了两个主要原因: 1)高精度评分任务需要对answer text有很深的语义理解; 2)ASAG任务的语料一般都很小,不能为深度学习提供足够的训练数据。为了解决这些挑战,作者提出用BERT-based网络来解决ASAG任务的挑战: 1)用预训练模型BERT来encoder答案文本就可以克服语料太小的问题。2)为了生成足够强的语义理解,作者在BERT输出层后加上了一个精炼层(由LSTM和Capsule网络串联组成) 3)作者提出一种triple-hot loss来处理ASAG的回归问题。实验结果表明模型的效果在SemEval-2013和Mohler数据集上表现比SOTA要好。模型在github上开源
2.2. Introduction
考试和评估是智慧辅导系统(intelligent tutoring systems, ITSs)的重要组成部分,可以获得学生们的实时知识认知水平,也能为学生们提供个性化的学习方案。多选题是考试的重要组成部分,但是多选题有两个明显的短板: 1)多选题只提供部分选择 2)有些学生的答案可能是蒙出来的。ASAG可以解决上述问题,学生们为简答题提供一个short text,然后ASAG来评估short text是否正确,具体来说评估结果有五类: Correct、Partically correct、Contradictory、Irrelevant、Nondomain。
以往的研究中,Feature engineering是ASAG的主要解决方法,有很多稀疏特征应用于ASAG: token overlap features、syntax and dependency features、knowledge-based features(WordNet)… 但是这种特征工程为基础的方法存在以下问题: 首先,稀疏特征一般需要很多预处理步骤,这些步骤会产生一定的误差,可能会涉及到误差累积和误差传递的后果。此外,缺乏有效地encode文本句的手段
随着deeplearning的发展,出现了很多deep net,比如LSTM-based model、CNN and LSTM-based model、transformer-based model出现在了ASAG任务中。这些模型都从answer text中挖掘语义信息,然后将answer text转化成word enbedding,所以这些方法都是end-to-end的。但是这些方法存在以下问题: 1)学生的答案非常free,也就是说在句子结构、语言风格、段落长度这些方面可能会有很大的区别,所以作者认为需要用更先进的technique去获得text的语义理解。2)由于数据很难标注,所以ASAG任务的数据集语料很小,可能只有few thousand。所以说主要的挑战就是如何在小语料库上训练一个稳定高效的模型
论文的主要贡献:
- 提出了用预训练模型BERT微调,然后连接一个精炼层的模型表现超过SOTA(在SemEval-2013数据集和Mohler数据集上)
- 精炼层由Bi-LSTM和Capsule network(with position information)串联组成,LSTM来抽取全局的context信息,Capsule来抽取局部context信息
- 用多头注意力层来连接全局和局部context来生成语义表示
- 提出了triple-hot loss策略
2.3. Related Work
2.3.1. Applications of Deep Learning in ASAG Tasks
根据deep learning和训练策略的不同,作者将deeplearning在ASAG的应用分为以下三种:
- Participator: deep learning参与feature-based方法中
- Contractor: deeplearning独立地在ASAG任务中实现end-to-end
- 迁移学习,经典的预训练模型+scaling语料库
接下来分别介绍了利用稀疏特征的方法与Deeplearning来来解决ASAG任务:
- 稀疏特征,也即feature engineering的应用有:
- Marvaniya等人和Saha等人使用预训练的神经网络InferSent对答案文本进行编码,这弥补了标记重叠(token overlap)方法中上下文表示的不足,其中InferSent是使用Bi-LSTM网络的预训练句子嵌入模型
- Tan等人提出了一种将图卷积网络(GCNs)与几种稀疏特征相结合的评分方法。他们首先为答案文本构建了一个无向异构文本图,其中包含句子级节点、单词/bigam级节点和节点之间的边。然后,他们使用两层GCN模型对图结构进行编码,得到图的表示形式。
- Zhang等人使用深度信念网络作为分类器,而不是传统的机器学习,对学生由六个稀疏特征组成的答案表示进行分类
- Deeplearning的方法有:
- Kumar等人提出了ASAG的Bi-LSTM框架。他们的框架由三个级联的神经模块组成:分别应用于参考和学生答案的Siamese Bi-LSTMs,使用earth-mover distance(EMD)与LSTMs的隐状态交互的池化层,以及用于输出分数的回归层
- Uto和Uchida将LSTM网络与项目反应理论(item response theory)相结合进行短文本答案评分
- Tulu等人改进了基于LSTM的评分方法,通过引入感觉向量并将池化层替换为曼哈顿距离
- Riordan等人结合CNN和LSTM网络进行短文本答案评分
- Liu等人在一个大型K-12数据集上提出了一个具有多路注意的模型
上面提到的deeplearning方法需要大语料库支撑的数据集,但是ASAG缺少足够的大语料库,于是出现了用预训练模型来解决ASAG任务,比如ELMo、BERT、GPT、GPT-2,在这些模型中,BERT表现最好
2.3.2. BERT Model and Its Application in Education
BERT吸收了ELMo和GPT的优点,模型如下图所示:
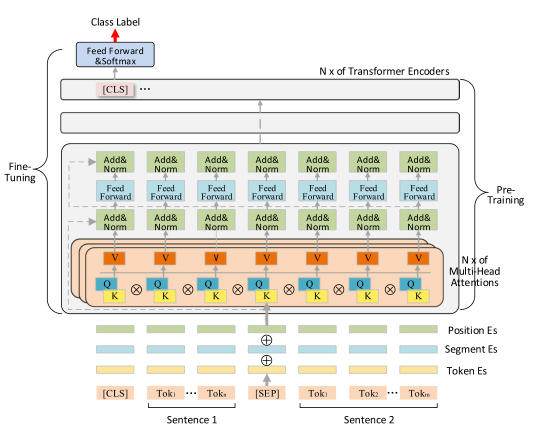
BERTstack了12个transformer块
接下来介绍了BERT在智慧教育领域的应用:
- Wang等人提出了分层课程BERT模型,以更好地捕捉每门课程的课程结构质量和语言特征,预测在线教育中教师的绩效
- Khodeir等人将BERT与多层双向GRU相结合,构建了一个紧急分类模型,用于教师快速挑选和响应大规模开放在线课程(MOOC)论坛中最紧急的学生帖子,该模型在三个Stanford MOOC Post数据集上实现了紧急帖子分类,加权F-score分别为91.9%、91.0%和90.0%
- Sung等人利用BERT构建了一个多标签分类模型,用于快速评估学生在探索热力学的过程中的多模态的表征思维
关于ASAG的应用有:
- Sung等人分析比较了BERT与多种网络结构在short-answer grading的效果
- Leon等人分析比较了BERT、ALBERT、RoBERTa在short-answer grading的效果
2.4. Methodology
2.4.1. Task Definition
ASAG问题有两种形式:
- 回归问题: 连续的分数来评估学生的答案
- 分类问题: 将学生的答案分为五类: Correct、Partically correct、Contradictory、Irrelevant、Nondomain
作者的做法是用分数来对类别进行分类,比如0-0.5属于类别1,所以问题的本质还是分类问题,那么ASAG的预测类别$y^*$可以表示为:
\begin{equation} y^*=\underset{y \in Y}{\operatorname{argmax}}(\operatorname{Pr}(y \mid(q, p))) \end{equation}
其中Y表示类别集,Pr()表示预测的概率分布,q是学生答案,p是参考答案
2.4.2. Model
作者解释为什么既要用BERT,也要用refinement:
- BERT获得word embedding结果,利用了所有词元之间的关系,但是没有考虑顺序和距离,所以需要用Bi-LSTM来生成更精细的全局context,同时弥补BERT时序信息的缺失,然后利用Capsule或者CNN来生成BERT每个隐层的局部信息
- BERT可以获得动态的词嵌入(对比GloVe获得静态的词嵌入),这样可以获得更丰富的general-purpose knowledge,所以BERT即使在小语料库上也能有不错的效果
- 一些研究表明,在BERT上应用经典的神经网络可以在小数据集上获得更好的效果,比如Liao等人结合RoBERTa和CNN来提升情感分析的效果,Yang等人在BERT上应用多头注意力层来添加距离权重在aspect polarity classification上获得更好的效果
主题网络模型如下图所示:
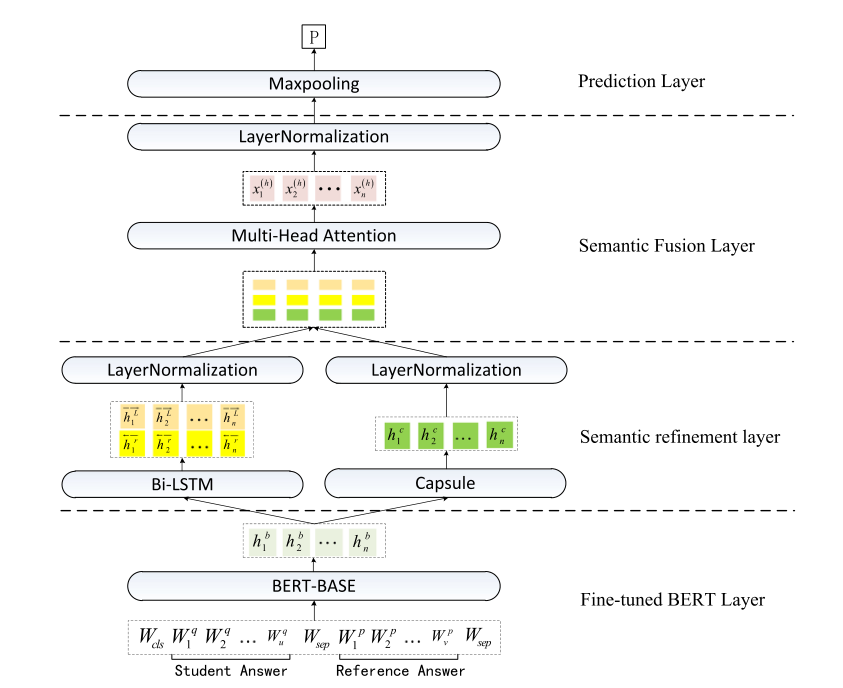
接下来从模型的各个板块来分别介绍:
2.4.2.1. BERT layer
首先BERT layer的参数初始化成BERTbase的参数,微调。BERT layer层的输入是学生和参考答案的token embedding,输出是BERT的隐层
\begin{equation} O_{BERT}=BERT(s)=\left\{h_1^b,h_2^b,...,h_n^b\right\}\in \mathbb{R}^{n\times d_b} \end{equation}
2.4.2.2. Semantic Refinement Layer
Refinement层由Bi-LSTM和Capsule network(with position information)串联组成,输出结果如下所示:
\begin{equation} \begin{aligned} &\overrightarrow{O_{\mathrm{LSTNS}}}=\overrightarrow{\operatorname{LSTMS}}\left(O_{\text {BERT }}\right)=\left\{\overrightarrow{h_1^L}, \overrightarrow{h_2^L}, \ldots, \overrightarrow{h_n^L}\right\} \in \mathbb{R}^{n \times d_L} \\ &\overleftrightarrow{O_{\mathrm{LSTMs}}}=\overleftarrow{\operatorname{LSTMs}}\left(O_{\mathrm{BERT}}\right)=\left\{\overleftrightarrow{h_1^r}, \overleftrightarrow{h_2^r}, \ldots, \overleftrightarrow{h_n^r}\right\} \in \mathbb{R}^{n \times d_L} \\ &O_{\mathrm{Caps}}=\operatorname{Capsules}\left(O_{\text {BERT }}\right)=\left\{h_1^c, h_2^c, \ldots, h_n^c\right\} \in \mathbb{R}^{n \times d_c} \end{aligned} \end{equation}
输出结果后面都跟了一个层归一化(保证数据分布的稳定,加速收敛)
这里提到了Capsule network,我对Capsule network进行一定的补充: Capsule网络主要想解决卷积神经网络(Convolutional Neural Networks)存在的一些缺陷,比如说信息丢失,视角变化等。Capsule网络结构如下图所示:
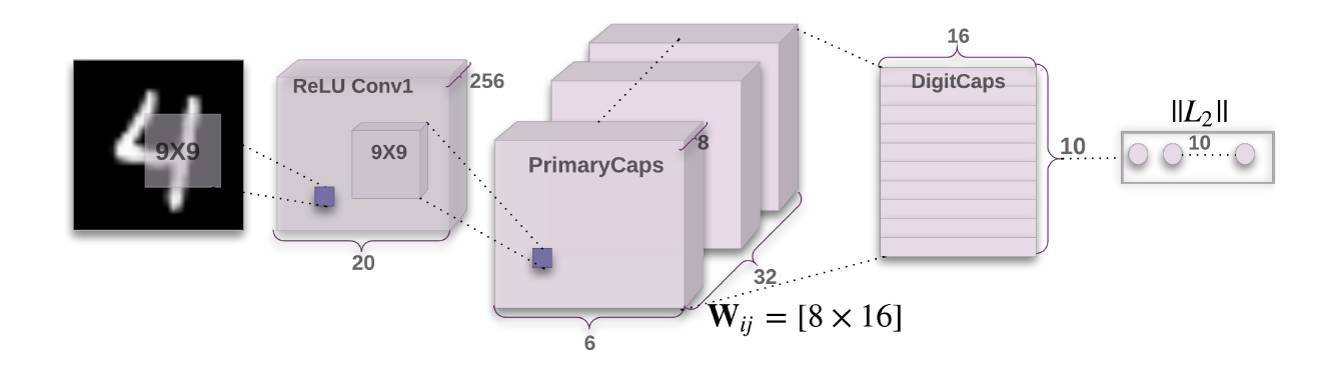
以数字图片分类为例,Capsule一共包含3层,2层卷积层和1层全连接层。与普通网络的区别是输出的每个类别都是一个向量,向量的长度表示实体存在的概率大小,向量在空间中的方向表示实体的实例化参数,Capsule网络和CNN还是比较相似的
2.4.2.3. Semantic Fusion Layer
在refinement层后,需要有一个融合层来融合LSTM和Capsule的结果,先用矩阵来stackLSTM、Capsule的结果:
\begin{equation} X^{(e)}=\{x_1^{(e)}, x_2^{(e)},...,x_n^{(e)}\}\in \mathbb{R}^{n\times d} \end{equation}
其中$x_i^{(e)}=[h_i^L;h_i^r;h_i^c]$,然后再把矩阵X送入多头自注意力层,注意力评分函数是scaled dot-product attention,具体细节如下:
\begin{equation} \begin{aligned} & \text{MultiHead}(Q,K,V)=[\text{head}_1;\text{head}_2;...;\text{head}_h]\omega^R \\ & \text{head}_i=\text{Attention}(Q_i;K_i;V_i)=\text{Attention}(Q\omega ^Q, K\omega ^K, V\omega ^V) \\ & \text{Attention}(Q_i;K_i;V_i)=\text{softmax}(\frac{Q_iK_i^T}{\sqrt{d_K}})V_i \\ X^{(h)}&=\text{MultiHead}(X^{(e)}, X^{(e)}, X^{(e)}) \\ &=\{x_1^{(h)}, x_2^{(h)},..., x_n^{(h)}\} \end{aligned} \end{equation}
为了让全局context和局部context不互相干扰,作者对多头自注意力层做以下约束:
- 让LSTM的输出维度和Capsule的输出维度相同,即$d_c=2d_L$
- head数取2
- 让局部context和全局context不互相干扰(用参数调整),如下图所示:
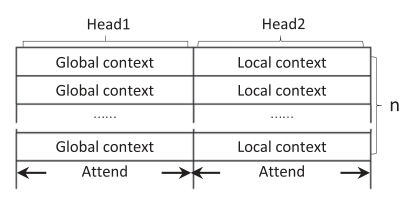
最后再连接一个层归一化
2.4.2.4. Prediction Layer
预测层,首先用最大池化层获得pair(q,p)的语义表示,其实就是在每个头上选择最大的值:
\begin{equation} \begin{aligned} Z &=\text{Maxpooling}(X^{(h)})={z_1,z_2,...,z_d}\in \mathbb{R}^d \\ z_j &=\text{Max}(x_{1j}^{(h)}, x_{2j}^{(h)},..., x_{nj}^{(h)}), j=1,2,...,d \end{aligned} \end{equation}
然后将语义表示Z输入线性层(加上一个dropout防止overfit),然后用softmax表示输出的概率分布:
\begin{equation} \begin{aligned} o &=MZ+b \\ p(y\mid Z)&=\frac{exp(o_y)}{\sum_{i}^{d_y}exp(o_i)} \end{aligned} \end{equation}
2.4.2.5. Loss Function
为了适应两种ASAG tasks,作者提出了两种损失函数的策略:
- 第一种就是常规的交叉熵,分类结果用one-hot编码
\begin{equation} L(\theta)=-\sum_{i=1}^{|\Omega|}\log \left(p\left(y_i \mid Z_i, \theta\right)\right) \end{equation}
- 第二种就是作者提出用triple-hot编码y,就是在y对应位置的左右也置1,那么损失函数为:
\begin{equation} \begin{aligned} L(\theta)=&-\sum_{i=1}^{|\Omega|}\left(\log \left(p\left(y_i^{-1} \mid Z_i, \theta\right)\right)+\log \left(p\left(y_i \mid Z_i, \theta\right)\right)\right.\\ &\left.+\log \left(p\left(y_i^{+1} \mid Z_i, \theta\right)\right)\right) \end{aligned} \end{equation}
2.5. Experiments
2.5.1. Datasets
作者在两个ASAG主流数据集上进行评估,分别是SemEval-2013和Mohler数据集
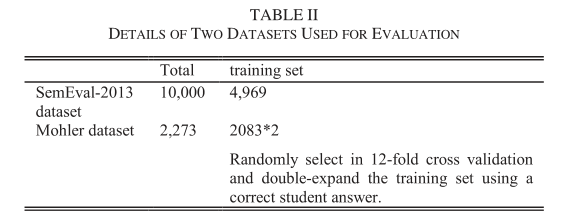
- SemEval-2013: 作者使用SemEval-2013中的SciEntsBank语料,SciEntsBank语料包含15个不同科学领域的197个问题和10000个答案,这个语料库是ASAG分类任务的一个benchmark,他包含三种分类类别,分别是two-way(Correct and Incorrect),three-way (Correct, Contradictory, and Incorrect),five-way (Correct, Partially correct, Contradictory, Irrelevant, and Non-domain),为了提供多方面的evaluation,测试数据集分为了三个子集:
- Unseen Answers(UA): 和训练集有相同的题目和参考答案,但是学生的回答不同
- Unseen Questions(UQ): 和训练集的问题不同,但是属于同一个领域
- Unseen Domains(UD): 和训练集的问题不同,且不属于同一个领域
- 对于这个数据集,作者用三个性能度量(accuracy, weighted-F1, macro-average F1)来评估两个子任务(three-way, five-way)
- Mohler dataset: 数据集开源。数据集由Mohler团队从University of North Texas的一门计算机科学课程的两个考试和十个测试收集整理。它包含80个问题和2273个学生的答案,每个答案都由两名老师打分(0-5, integer),由于是平均而来,所以一共由11种分类结果,Mohler数据集同样是ASAG任务的一个benchmark,作者可以将数据集变成了11个类别的分类数据集。
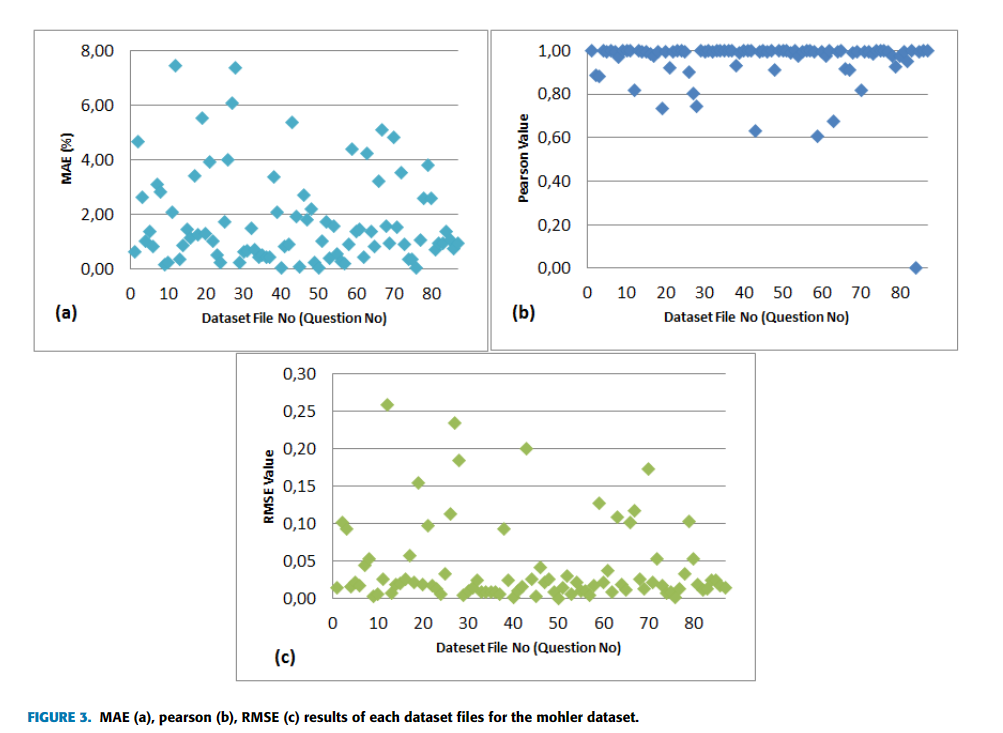
由于数据集只有2273个答案对,太小,所以需要对数据集进行扩充,Kumar等人通过把训练集中正确的学生答案作为额外的参考答案,这样就把数据集的答案-问题对扩充到30000对。作者为了避免过拟合,采取了折中的策略,对每个问题只挑选一个学生的正确答案作为额外的参考答案,这样就把2083个答案对扩充至3300个答案对。针对Mohler数据集,作者采用了12折交叉验证的方法,用来评估的性能度量有Cohen’s kappa coefficient(kappa), Pearson correlation coefficient(Pearson’s r), mean absolute error(MAE), root-mean-square error(RMSE),Mohler的标签只有11类,作者既可以把它当作了回归任务来评估(就是把分类结果用分数表示),也可以把它当作分类任务来评估,其中kappa系数是分类任务的性能度量,其他的性能度量都是回归任务的性能度量
2.5.2. Experimental Settings
BERT采用base版本(12层,768个单元,12个head,110M参数),LSTM的隐层个数设置为200并且在最后一个时间步返回所有的hidden state,Capsule的卷积核个数设置为400,卷积核大小为3,dynamic route设置为3。在融合层,attention head设置为2,每个头400维参数,dropout参数都设置为0.1,使用adam优化器,学习率设置为2e-5,一个小批量64个输入,训练周期为10
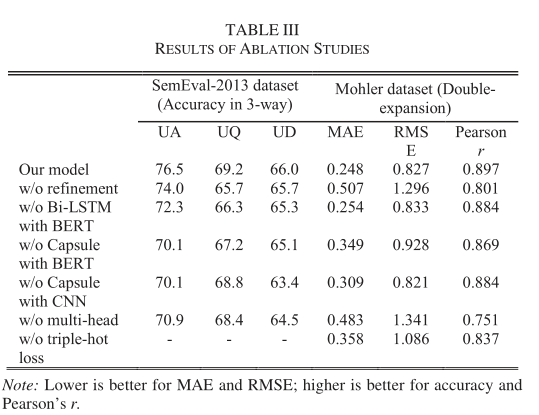
2.5.3. Ablation Studies
为了分析每一层的作用,从六个角度来做ablation studies:
- W/O refinement: 无refienment
- W/O multihead: 无multihead
以此类推,得到如下结果:
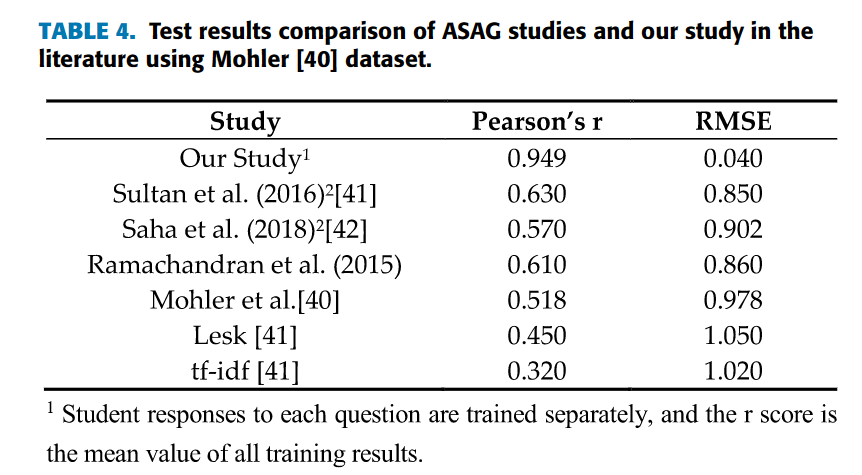
2.5.4. Comparison With Baseline Systems
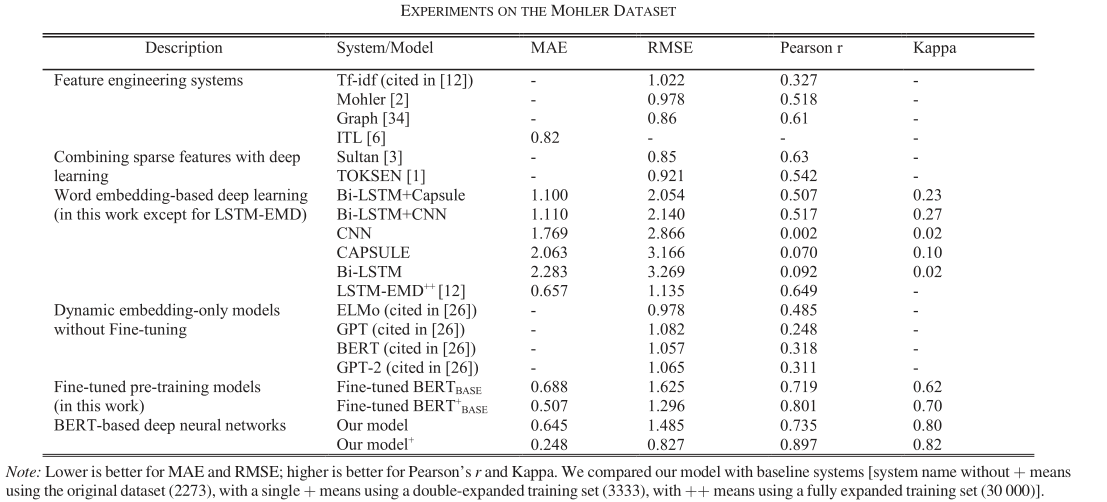
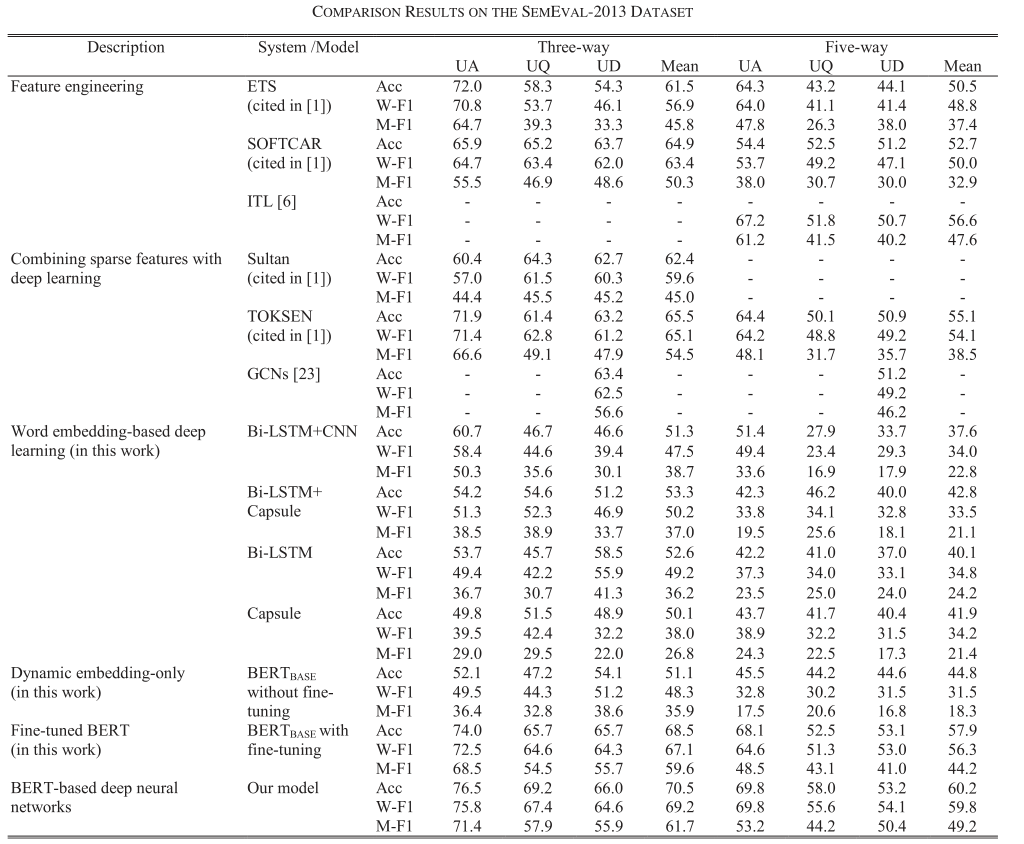
与众多模型进行对比,主要的实验结果如下:
- Mohler数据集
- SemEval-2013:
- PR曲线:
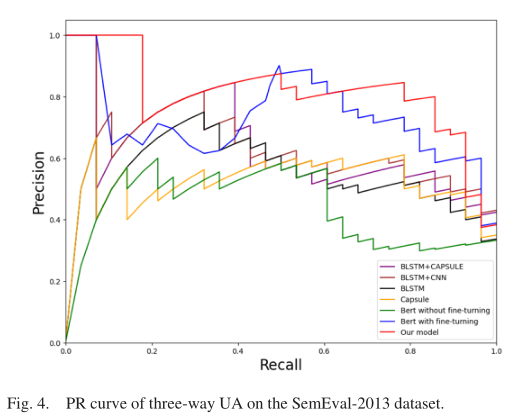
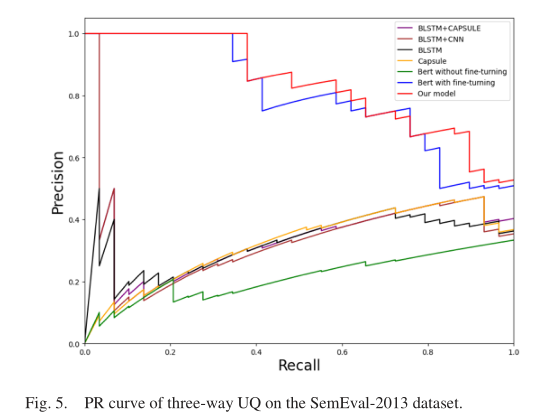
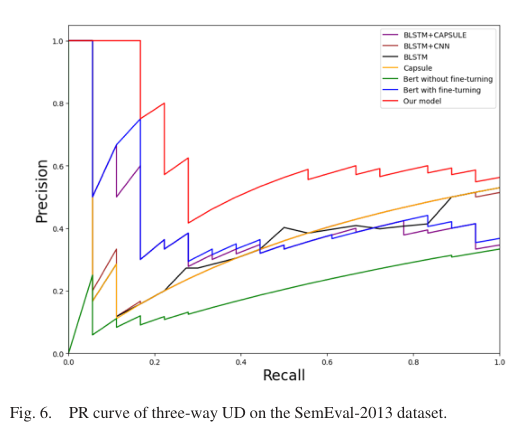
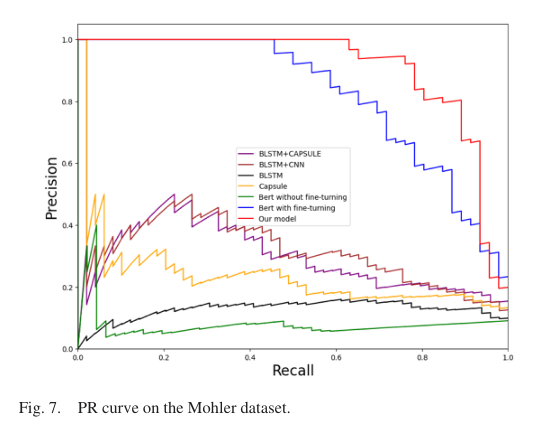
- AUC值和PR曲线平衡点:
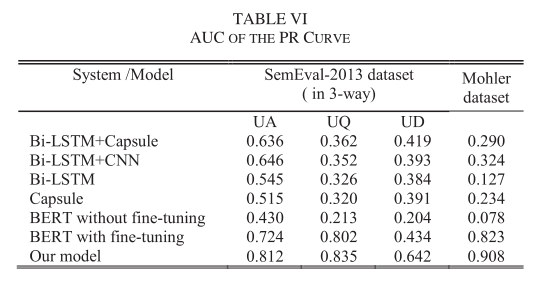
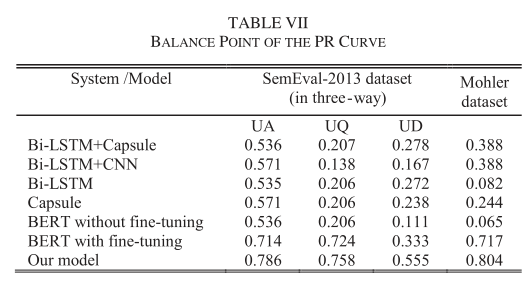
2.6. Discussions
从Ablation实验结果可以看出,refinement层提升了模型的在Sem-UQ和Mohler数据集上的精度,说明refinement层提高了BERT模型在相同问题领域的泛化性,同时也可以看出LSTM在refinement层也很重要,可以提取更丰富的全局context信息。Capsule的有无也说明了它可以提取局部context信息,同时发现它的效果比一般的CNN要好。Triple-loss的设计也确实提升了模型的性能
接着简单分析了一下表4(Mohler数据集)与表5(SemEval-2013)的结果,其实就是对比了不同模型的性能度量,说哪个模型更好什么的
然后分析PR曲线的结果,作者认为在大多数情况下,模型的PR曲线远高于其他模型的PR曲线,这与表6中模型在所有图中AUC最大的结论是一致的。除此之外,平衡点的值也更高,说明模型性能最好
模型可以应用于智慧教育系统的两个场景:
- ITSs领域,即智慧辅导系统,可以让评估变成自动化的
- MOOC线上平台,可以替代老师的手动评估,快速精准地为大量的free-text answer进行评分
2.7. Conclusion
作者提出了一种新的BERT-based网络结构来解决ASAG问题,进行了大量的实验,得出了一下的结论:
- 基于词嵌入的网络,如CNN、LSTM、Capsule无法在小数据集上取得很好的结果
- 预训练网络BERT可以很好的适配ASAG任务
- 利用LSTM和Capsule网络可以进一步挖掘语义信息
模型局限性:
- 在开放领域的问答中,小数据集训练出来的模型无法取得预期的效果,比如Sem-UD
- 目前来说,模型无法消除或者替代学生答案中的大量的代词,作者计划在后续通过BERT模型来消除学生答案中的代词来提升模型的性能
3. Leveraging Semantic Facets for Automatic Assessment of Short Free Text Answers
论文全称为Leveraging Semantic Facets for Automatic Assessment of Short Free Text Answers,接下来将逐段阅读并整理论文
3.1. Abstract
短文本问答能反映出学生对于知识的掌握情况,由于自然语言的复杂性,简答题的自动评估任务仍具有挑战性。现有的自动评估模型的做法是预测答案的分数来评估学生的答案,他们一般不关心参考答案的语义面,这限制了预测的表现。该篇论文的关注点是短文本答案的不同的语义面(semantic facets),每个语义面对应着需要掌握的知识。利用带有语义面标注的数据集,作者首先展示了语义面状态与答案质量(一个答案的好坏)的对应关系,然后展示了语义面在自动评估答案质量的重要性。作者接着将工作拓展到不包含语义面的数据集上,证明了作者的工作在自动评估短文本答案方面的有效性,这些工作包括语义面提取、预测语义面状态和使用语义面的特征工程。
论文的贡献有:
- 论文提出的方法提升了短文本答案评估的SOTA的表现
- 论文深入研究短文本答案的语义面组成,让短文本评估模型的可解释性更高
3.2. Introduction
评估学生的答案非常重要,在网上学习中,实现手动评估非常困难,加速了关于自动评估的研究。研究着重于学生的短文本答案,与多选题相比,答案更不被定义且不具备结构化,所以自动评估很困难。此外,为了正确回答问题,一个短文本的回答可能传达了学生对知识的更深层次的思考,并且可能包含多个从属的知识。有了语义面之后,一个更详细的评估方法出现了,可以分析学生答案的不同语义部分,而不是简单的给出答案的分数。
最近的研究基本上都采取了黑盒的模式(black box),即从一端输入学生的答案和参考答案,另一端直接输出答案的分数,这中间发生了什么我们并不知道。虽然说对于评估系统来说,分数很重要,但是参考答案涉及到的多个知识点与学生答案的匹配情况我们却一概不知。为了提升评估任务的表现,作者将关注点从黑盒转移到分解评估的过程。为了简便,作者将参考答案的知识组成称为语义面(Semantic Facets),给定一段文本,这段本文的语义面是由文本的短语组成的集合
论文的主要实验和工作有两个,分别在SciEntsBank数据集和Beetle数据集上展开
- 第一个工作数据集是SciEntsBank,每个问题的语义面都标注好了,学生答案与问题的语义面匹配状态(matching state)也给出了,这样我们就可以得到不同评分等级(correct, incorrect…)的答案的语义面匹配状态的分布情况。有了分布情况后,我们便可以回答以下问题: 1)是否能根据学生答案的语义面匹配状态来确定答案的评分? 2)分布情况对自动评估系统是否有帮助? 除此之外,我们还可以构建模型来通过学生的答案和语义面来预测语义面的匹配状态
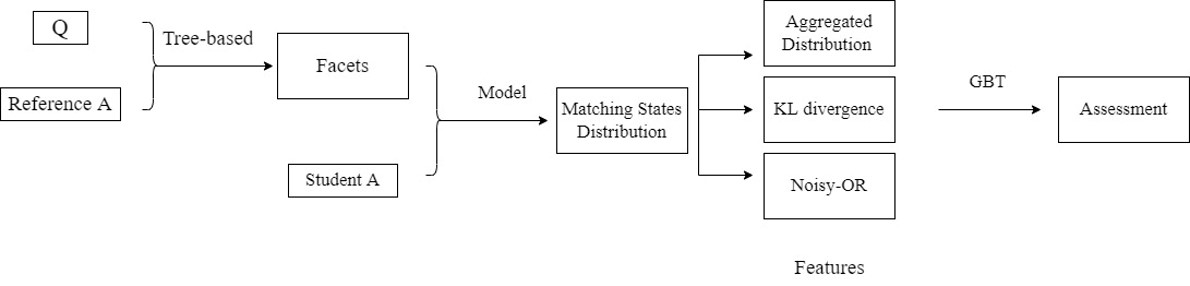
- 为了泛化第一个工作,第二个工作使用的数据集是Bettle数据集,这个数据集既没有语义面的标注,也没有语义面的匹配状态的标注。作者首先提出了一种从参考答案提取语义面的方法: 利用词汇统计(lexical statistics)和语法信息(syntax information)。接着利用第一个工作中训练好的预测语义面的匹配状态的网络来预测这个数据集的语义面匹配状态,然后再利用工作一中发现的pattern来通过学生答案的语义面匹配状态来获取features(后续用于对答案进行评分,所以这一步就是feature engineering),最后,利用这些feature来预测答案的评分
贡献:
- 部分程度上打开了自动评估模型的black box
- 发现了matching state与不同评分等级的对应关系,即发现了pattern,这对于自动和手动评估都有帮助
- 提出了一种从参考答案抽取语义面的方法
3.3. Related Works
该小节介绍了论文的两个相关工作: 1)自动评估系统的不同任务及对应方法 2)量化一对文本的语义相似度的方法
3.3.1. Automated response evaluation
根据自动评估系统目标的不同进行分类:
- 为了评估学习者的语言使用能力,许多评估系统从语言和语法使用、内容组织等方面评估写作质量,这样的系统有ETS(educational testing services)、E-Rator 、Coh-metrics、AcaWriter
- 评估学生答案时要求学生的答案涵盖特定的知识,只有涵盖了最关键的部分,学生才能获得满分。为了这个目标,许多系统训练了一个预测模型,有运用词重叠(word overlapping),语义和语法相似等特征的模型,也有预训练模型来做embedding的模型
论文工作属于第二类
3.3.2. Semantic similarity measurement
量化两段文本的相似度是自然语言处理的基本步骤,短文本自动评估系统通过文段相似度的测量来量化学生答案和参考答案的相似度。测量方法有term matching(术语匹配)技术和涉及外部知识的语义计算(semantic computation)
- term matching技术基于真实文本和预测文本的公共单词,基于term matching的方法有BLUE和Rouge。
- term matching有个明显的短板就是无法处理近义词或者同义词,可以用WordNet来解决。除此之外,一个单词或者短语的意思可以被分解成量化的语义块,这样测量起来才是数字化的(非二进制),这样的方法有LSA(Latent Semantic Analysis)、Word2vec、GloVe。但即使是Word2vec也无法解决一词多义的问题,所以诞生了单词的动态语义嵌入(即考虑了context),这样的模型有RNN-based ELMo、Bert等等
3.4. Patterns and indicative powers of facets matching states
也就是intro里提到的第一个工作,着眼于发现state和response type的pattern,然后利用这个pattern来做预测(通过答案的语义面匹配状态来预测答案的评分)
3.4.1. Materials and methods
3.4.1.1. Dataset
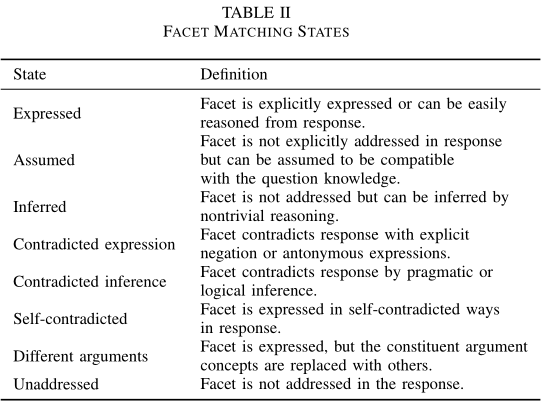
数据集使用的是SciEntsBank,数据集大约有10000个学生答案和197个问题,学生答案分为五类(5-ways,见表格1),训练集和测试集分别有4969和5835个样本,同样地,根据问题的不同分为: UA, UQ, UD。数据集中每一个问题都包含语义面的标注,正确的学生答案应该cover这些语义面,数据集中同样包含语义面匹配状态的标注,语义面的状态一共有八种,见表格2

为了更直观地了解样本和语义面及语义面匹配状态,这里举了一个例子:


这个例子的语义面及两个学生答案对应的语义面匹配状态见表格3:
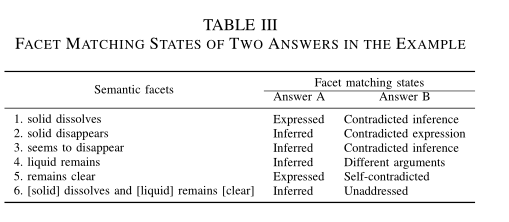
通过表格3我们可以发现语义面关注相关对象的特定属性或状态,这里可以发现相对正确的答案A基本上与所有的语义面都匹配,但是相对不正确的答案B与某些语义面冲突
3.4.1.2. Summary of facet matching states
每个语义面只有一个语义面匹配状态,不同问题的语义面数量不同,可以用语义面匹配状态的分布情况来总结一个问题的总体的语义面匹配状态,这样我们就可以比较不同评分等级的答案的匹配状态,比如我们可以比较答案A和B的分布,见表格4:
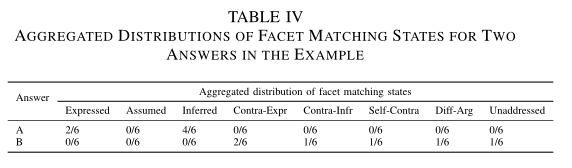
3.4.1.3. Answer quality prediction with facet matching states
不同答案的语义面匹配状态的分布不同,可以将八种匹配状态的分布权重视为feature,答案的类型作为label,那么就可以进行分类。作者采用Gradient Boosting Tree(GBT)来当作预测模型。这样就可以通过答案的匹配状态分布来预测答案的评分
3.4.2. Results and analysis
3.4.2.1. Facet matching pattern
数据集总体的语义面匹配状态分布见表格5,利用卡方检测,可以发现答案的类型与语义面匹配状态的权重(即分布)有关
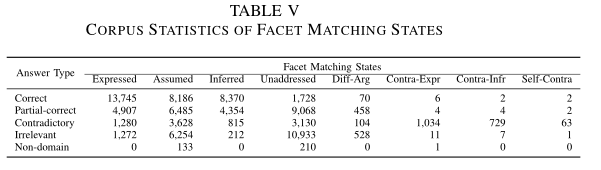
归一化每个匹配状态的权重,得到下图的分布,可以发现不同答案类型的匹配状态分布不同:
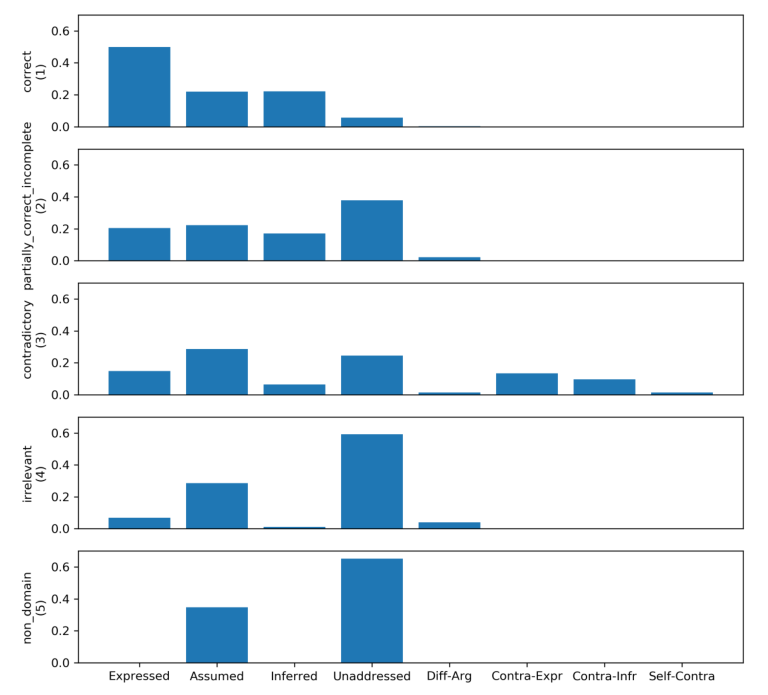
观察发现,Correct的答案基本上express语义面,non domain的答案基本上unaddress语义面,不同类型答案的匹配状态分布情况就是一个pattern,用来连接一个答案的匹配状态和类型
3.4.2.2. Answer evaluation leveraging facet matching states
接下来评估以下GBT模型(通过匹配状态来预测类型)的表现情况,结果见表格6,性能度量是Macro F1
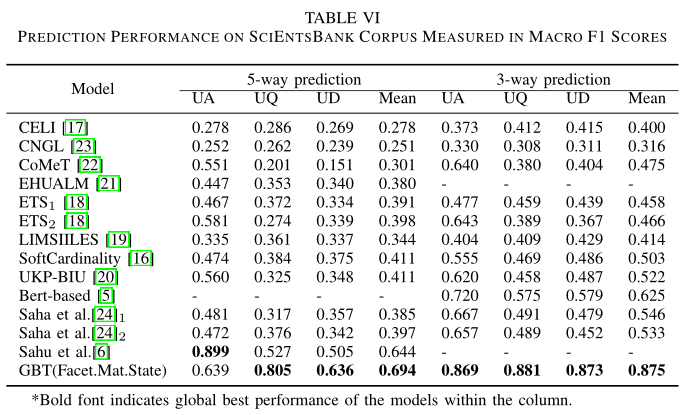
通过表格6可以发现,这个分类任务是具有挑战性的,基本上所有的模型都取得了相对较低的F1值,比较不同模型发现,GBT取得了最好的结果。总的来说,现实任务中不太可能会知道一个问题的语义面或者语义面匹配状态,所以作者将工作拓展到更一般的情况,也就是3.5节将介绍的内容
3.5. Automatic Extraction of Facets Matching Features For Better Prediciton
对于语义面和语义面匹配状态都没有的情况下,作者提出了抽取语义面和预测语义面匹配状态的方法,然后利用特征抽取的方法挖掘出语义面匹配状态分布与pattern的关系,再结合语义相似性来预测答案的类型,这种方法大大提高了预测的表现
3.5.1. Materials and methods
3.5.1.1. Dataset
数据集使用的是Beetle数据集,56个问题,5000个学生答案,标签有5-way和3-way,训练集和测试集分别有3941和1258个样本,测试集分为UA, UQ
3.5.1.2. Automatic semantic facet extraction
Beetle数据集的参考答案不包含语义面,但是一个问题会有多个参考答案,他们之间有细微的差别,一个例子:
问题是: Why does measuring voltage help you locate a burned out bulb?
参考答案:
- Measuring voltage indicates the place where the electrical state changes due to a damaged bulb
- Measuring voltage indicates the place where theelectrical state changes due to a gap
- Measuring voltage indicates whether two terminals are connected to each other
- Measuring voltage indicates whether two terminals are separated by a gap
接下来将介绍作者如何从参考答案集中抽取出语义面:
- 关键词提取: 从问题和参考答案中抽取出现次数超过两次的词,这些词就是关键词(pivotal word)
- 基于语法的expression提取: 从参考答案的语法树(dependency parsing tree)中获取与语法相关的术语来形成更完整的expression,下面这张图展示了例子中四个参考答案的语法树:
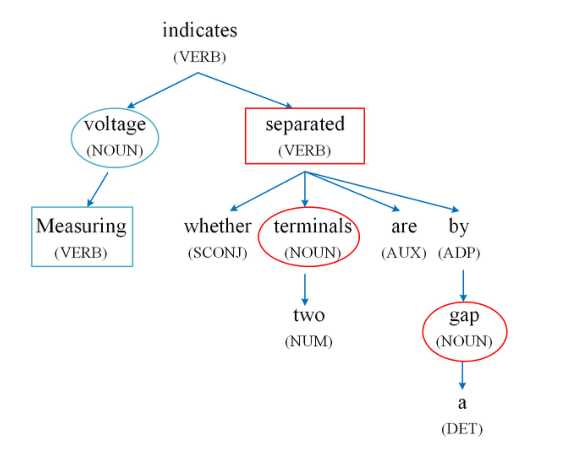
语法树建立句子中单词的语法关系,从中心词往外伸展,一个句子的中心词就是它的谓语。有两种生成语义面的方法,第一种就是连接关键词和树上与它相邻的词,比如voltage和measuring构成了一个语义面measuring voltage。第二种方法是针对一对关键词,找到它们的最小公共节点构成语义面,比如terminals和gap的最小公共节点是separated,那么它们可以构成语义面terminals separated gap。第一种方法的出发点是一个关键词可能是一个expression的一部分,第二种方法的出发点是两个关键词可以覆盖较大的语义区域,再结合它们的公共节点,便可包含多个语义面,成为一个新的语义面。
通过这两种方法可能会生成意义不明的语义面,但是这也是后续算法需要考虑的部分,增强了算法的泛化性
3.5.1.3. Facet matching features
有了学生答案的语义面后,接下来就需要实现语义面匹配状态的预测。为了实现预测模型,作者用带匹配状态标签的SciEntsBank数据集进行训练。模型的细节在Appendix A中具体展开。模型的结构如下图所示:
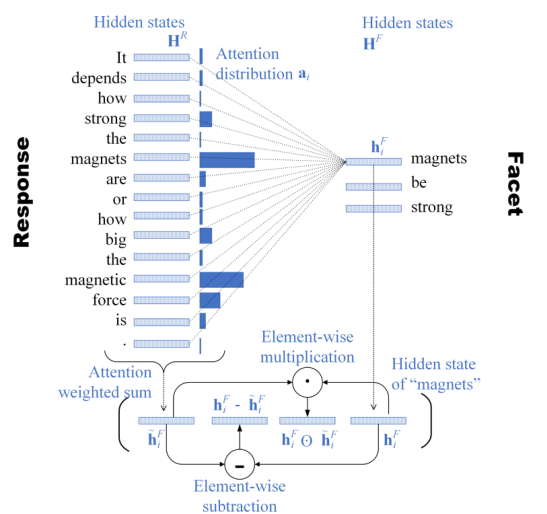
模型的左边代表学生答案的输入,模型的右边代表语义面的输入,它们的每个词元都经过Bi-LSTM(embedding选择的是Glove),然后输出隐状态,然后用注意力机制获得$\tilde{h_i^F}$,查询是语义面的hidden state,K和V是答案的hidden state,注意力权重为:
\begin{equation} a_{i,j}=\frac{e^{(h_i^F)^T\cdot h_j^R}}{\sum_{j'=1}^{N_R}e^{(h_i^F)^T\cdot h_{j'}^R}} \end{equation}
为了获取facet更全面的信息,作者将$\tilde{h_i^F}$、$h_i^F-\tilde{h_i^F}$、$h_i^F\odot \tilde{h_i^F}$、$h_i^F$连结了起来:
\begin{equation} \mathbf{c}_i=\left[\tilde{\mathbf{h}}_i^F ; \mathbf{h}_i^F-\tilde{\mathbf{h}}_i^F ; \mathbf{h}_i^F \odot \tilde{\mathbf{h}}_i^F ; \mathbf{h}_i^F\right] \end{equation}
接着对C进行取平均和最大的操作,concat之后输入MLP作预测,MLP这里取了三层,神经元数量分别为64、32和8,激活函数用ReLU:
\begin{equation} \begin{aligned} &\mathbf{c}_{\max }=\max (\mathbf{C}) \\ &\mathbf{c}_{\min }=\operatorname{avg}(\mathbf{C}) \\ &\mathbf{c}_{\mathrm{agg}}=\left[\mathbf{c}_{\max } ; \mathbf{c}_{\mathrm{avg}}\right] \\ &\hat{\mathbf{y}}=\operatorname{softmax}\left(\operatorname{MLP}\left(\mathbf{c}_{\mathrm{agg}}\right)\right) \end{aligned} \end{equation}
模型定义完后,作者比较了三种GBT的效果,GBT-Gold代表GBT在标注好的匹配状态和语义面上训练,GBT-Predict表示GBT在预测的匹配状态和标注好的语义面上训练,GBT-Approx表示GBT在预测的匹配状态和语义面上训练,性能度量同样是Macro F1,数据集用的也是SciEntsBank:
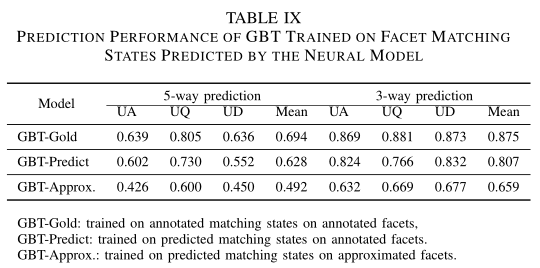
从表格中可以看出,GBT-Predict效果和GBT-Gold的效果差不多,根据预测的语义面匹配状态,我们有:
- Aggregated facet matching states: 一个学生答案的预测语义面有很多,预测的语义面匹配状态需要聚合在一起。作者提出了两种聚合方法: 第一种软的是平均了所有语义面的预测匹配状态的概率,第二种硬的做法是针对每个语义面,只保留概率最高的匹配状态,两种方法都可以获得匹配状态的分布
- Pattern matching: 将网络结构的输出aggregate之后,与五种类型的真实匹配状态分布对比后,了解该答案的预测匹配状态分布属于哪一种类型。具体的对比方法是选取KL散度最小的作为该答案的类型,KL散度能测量两个分布的差距,0代表两个分布相似度最高,假如预测的分布为$\tilde{p(x)}$,那么KL散度为:
\begin{equation} D(p_k(x)\|\tilde{p(x)}=\sum_{x\in C}p_k(x)log\frac{p_k(x)}{\tilde{p(x)}}) \end{equation}
- Confidence of prediction: 除了pattern matching外,匹配状态的confidence level也包含了很多信息。通过aggregate获得语义面的匹配状态分布后,取每个语义面预测概率值最高的概率值作为该语义面的confidence level。那么我们可以计算出Noisy-OR score:
\begin{equation} Noisy-OR=1-\prod_{i=1}^{N_F}(1-\tilde{p_i}) \end{equation}
其中$N_F$是语义面的个数,$\tilde{p_i}$就是语义面i的confidence level。如果所有的预测概率都是1,那么Noisy-OR为1,如果所有的预测概率都是0,那么Noisy-OR为0。Noisy-OR衡量了模型中至少有一个预测是合适的可能性有多大。Noisy-OR同样可以对某一个语义面匹配状态进行计算,这样得到的特征更好配合后续的使用
3.5.1.4. Semantic closeness features
除了3.5.1.3小节中提到的基于feature的分类方法,基于语义相似度的分类方法也适用。接下来会介绍一些计算参考答案和学生答案语义相似度的方法,如果有多个参考答案,取平均值即可:
- Term Matching Features: 用这些指数来计算语义相似度: N-gram overlapping, Rouge, Rouge-1, Rouge-2, Rouge-l, BLUE
- Fixed and dynamic embedding features: Glove, LSA, BERT。对参考答案和学生答案编码后计算相似度
- Semanic entailment features: 使用预训练的text entailment model: Decomposable Attention Model。输入文本对后,模型预测这两段文本的关系,有entailment, contradict, neutral
3.5.2. Results and analysis
为了评估3.5.1.3.和3.5.1.4.这两节提出的features,可以用GBT来测试。GBT可以看成随机森林,GBT在不同的特征上进行训练,表格7给出了不同特征上训练的结果:
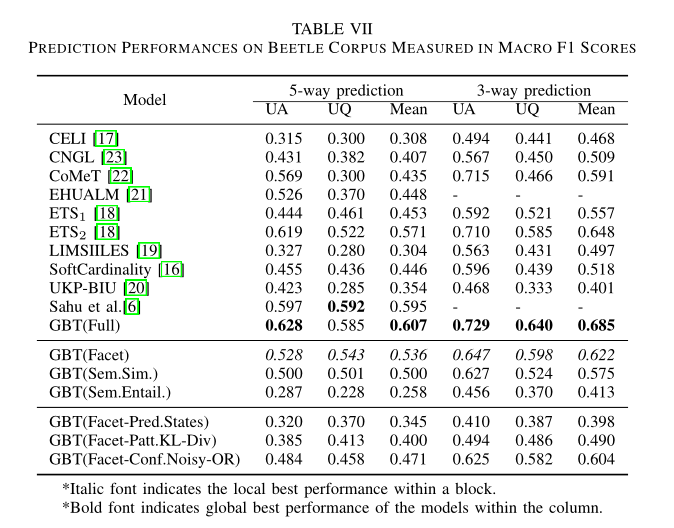
GBT(Full)表示上面提到的所有feature都运用了,包括aggregated matching state、KL散度、Noisy-OR、语义相似度和语义推断(semantic entailment)。可以发现将所有的信息都运用后,GBT(Full)模型是表现最好的模型。然后作者希望了解facet feature是否真的有效,GBT(Facets)就是运用了Facets所有特征的模型,横向对比GBT(Sem.Sim)和GBT(Sem.Entail),发现facet的表现最好,不止如此,将这些特征全部结合得到的效果会更好。最后对比以下facet三个特征: Nosiy-OR、KL散度、aggregated matching states。发现Noisy-OR的效果最好。
为了更深入地了解facet的三个特征,作者画出了三种特征的importance scores,如下图所示:
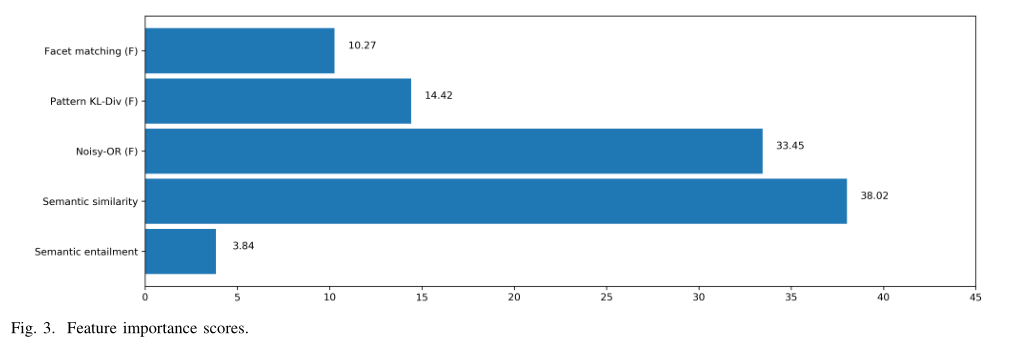
importance score表明了数的预测结果相对于特征值的变化有多大,值越高说明该特征对于GBT来说越重要,作者将这些值归一化。观察发现,facet的三个特征中,Noisy-OR最重要,其次是KL散度,最后是匹配状态,这和表格7得出的结果一致。同时也发现语义相似度作为特征来说表现其实已经很好了,比但看facet的任意一个特征都强,但是却不如facet的三个特征加起来使用,变相证明了作者工作的有效性。还有就是虽然Semantic entailment作为特征来说表现不佳,但是也能将模型的整体性能提升一点
3.6. Discussion
总的来说,作者用两个数据集进行了两个实验,第一个实验首先得到了五种类型的答案的分布情况,然后用GBT实现了通过语义面匹配状态的分布来预测答案的类型。第二个实验首先给出了生产语义面的方法,然后提出了预测语义面匹配状态的网络,有了语义面匹配状态后,就可以得到facet的三个特征: state分布、KL散度和Noisy-OR。实验发现Noisy的效果很好,并且利用confidence进行预测是一种新思路,可能会对后续研究有所帮助。
然后作者分析实验结果发现,模型目前能明显区分出correct和non domain、irrelevant,但是与partially correct、contradictory相比却并不能很好的区分开。作者认为可能是partially和correct在语义上可能并不冲突导致。
接着,作者着眼于强调论文研究的重要性。论文里提出的facet不仅能提高模型的性能,更重要的是它们可以为更详细的反馈提供相关信息,这是教育系统为学习者提供反馈不可缺少的部分。具体来说,facet的出现让评分的可解释性更强。这样我们就可以分析学生答案是哪个知识点没有答对,或者是哪个知识点没有出现在答案中。这样,教育系统就能为学习者提供有效的反馈,可以提供点对点的反馈,比如这个facet为什么没有expressed等等。facet的实用价值高,它除了作为feature外,还可以使答案分析的可解释性更强。
3.7. Conclusion
之前的许多研究往往关注评估学生回答的模型的表现,我们将待评估问题的知识点分解为从属的语义单元,称为语义面。每一个语义面都代表知识的某个方面,而它们共同构成参考答案的语义。然后作者实现了两个实验来说明研究的有效性,具体内容在discussion中已经说明。
future work: larger corpora, 优化语义面提取的算法, 预测state的算法使用更新的网络(比如bert及其衍生网络), facet的实用价值(比如提高解释性和用作feedback)
3.8. 小结
facet这篇论文的着重点就是提出了语义面,这篇论文的出发点其实很好想到,就是评估模型的性能可能无法有很大的提升了,那么我将答案分成好几个小部分进行评估是否能提升模型的性能?于是便有了这篇论文,facet可以理解成参考答案的知识点,它是否在学生答案中表达出就是它的states。论文做了两个工作,第一个是直接基于有facet标注和state标注的数据集上进行实验,因为不同问题的facet数量不一样,所以用state的分布来表达可能会更好,首先通过统计得到了不同类型答案的state分布,这为后续KL散度这一特征有帮助。然后使用GBT作为预测模型,通过state的分布来预测答案的类型,得到了较好的效果。第二个实验基于正常的数据集,就是不包含facet和state的标签,这也是比较一般的情况,毕竟标注facet和state非常贵。首先每个问题没有了facet,那么首先就得设计算法来得到问题的facet,作者提出了一种基于Dependency parsing tree得到facet的方法,并在附录B对这个算法进行了评价。得到facet后还是没有state,所以得设计一个网络来得到facet的状态,模型的输入是facet和学生的response,利用LSTM来获得隐状态,并用注意力机制找到facet的近似表示,然后连结了facet的隐状态的各类信息,最后加个MLP得到state。到目前为止,已经有了facet和state,那么就可以得到facet的特征来作预测,相当于特征工程。facet的特征使用到的有: state分布, 与第一个工作中真实分布对比的KL散度, 运用到confidence的Noisy-OR。除此之外,作者还对比了其余的特征,比如语义相似度和semantic entailment(这是已有的工作)。最后将这些特征fusion之后的效果比较好
4. Text-to-Text Semantic Similarity for Automatic Short Answer Grading
论文题目为Text-to-Text Semantic Similarity for Automatic Short Answer Grading,文章的出发点是利用语义相似度来进行ASAG任务,作者将语义相似度分为了Knowledge-Based Measures和Corpus-Based Measures,其中前者就只考虑词和词的相似性,后者考虑了词表来测量词的相似性关系
4.1. Knowledge-based Measures
Reference A的每个单词和Student A同词性的每个单词进行语义相似度的测量,找出语义相似度最高的值作为该单词该词性的语义相似度。作者比对了八种不同的语义性测量方法:
- shortest path:
\begin{equation} Sim_{path}=\frac{1}{length} \end{equation}
其中length表示两个词的最短路径(通过node-counting的方法)
- Leacock & Chodorow
- Lesk
- Wu & Palmer
- Resnik
- Lin
- Jiang & Conrath
- Hirst & St.Onge
4.2. Corpus-Based Measures
上面比较词的相似度的方法不考虑整个序列的语法和词表信息,Corpus-Based方法考虑了词表和序列信息,具体来说,作者使用了LSA(latent semantic analysis)和ESA(Explicit semantic analysis)来测量语义相似度
4.3. Experiment
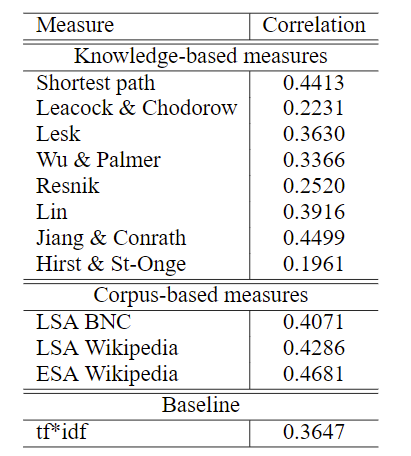
实验用相关性作为衡量各种语义相似度测量的指标,knowledge-based measures与Wordnet里提供的词的相似性指标进行相关性的测量,LSA与wordnet里提供的Infomap指标进行相关性的测量,ESA则是使用ESA算法进行测量,实验结果如下:
4.4. LSA(Latent semantic analysis)
LSA是分析语义相似度的传统方法,这里对该方法进行简要的介绍。LSA的中文说法是潜在语义分析,是一种无监督学习方法,主要用于文本的话题分析。
首先介绍一下单词向量空间与话题向量空间,单词向量空间就是用一个向量表示一段文本的语义,向量的每一维对应一个单词,其数值为该单词在文本中出现的频数或权值,向量空间的度量,如内积或标准化内积表示文本之间的语义相似度,单词向量空间的优点是模型简单,计算效率高。,局限性在于内积相似度未必能够准确地表达两个文本的语义相似度。
话题向量空间模型就是给定一段文本,用话题空间的一个向量表示该文本,向量的每一个分量对应一个话题,其数值为该话题在该文本中出现的权值。所谓话题,就是指文本所讨论的内容或主题,一段文本一般含有若干个话题,话题由若干个语义相关的单词表示。用两个向量的内积或标准化内积表示两段文本的语义相似度。
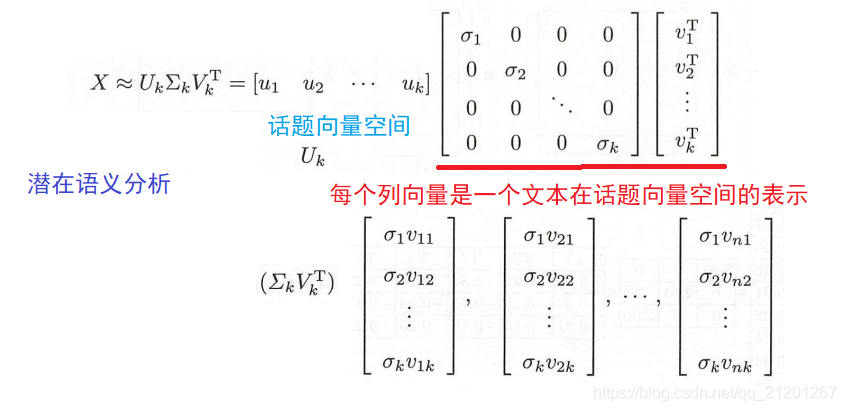
潜在语义分析利用矩阵奇异值分解(SVD),对单词-文本矩阵进行奇异值分解,左矩阵作为话题向量空间,对角矩阵与右矩阵的乘积作为文本在话题向量空间的表示。这样就可以通过单词向量空间得到话题向量空间的向量表示,然后计算不同文本向量的内积就可以得到语义相似度。

5. Pre-Training Bert on Domain for ASAG
论文全称为Pre-Training BERT on Domain Resources for Short Answer Grading,同样使用BERT作为主干网络,本篇文章的主要亮点就是利用当前领域的textbooks和QA对BERT进行微调,扩充了预训练的数据集,相当于是一种针对领域的微调方法
5.1. Usage of Textbooks
使用特定领域的textbook来扩充预训练数据集,将textbooks分为多个段落进行微调
5.2. Usage of Question-Answer Pairs
使用正确的Student A和Reference A作为一个pair进行微调,因为BERT本身的任务就有下一句预测,所以相对合理
5.3. 微调ASAG
Student A和Reference A作为一个句子对输入BERT,提取<cls>输入一个全连接层进行预测
5.4. Experiments
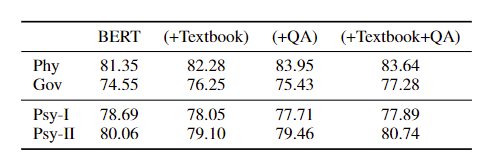
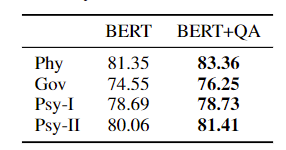
6. Imporving Short Answer Grading Using Transformer-Based Pre-training
论文全称Imporving Short Answer Grading Using Transformer-Based Pre-training,算是第一篇将Bert应用于ASAG任务上的论文,简单的输入Student A和Reference A作为序列对,然后利用<cls>进行分类
6.1. 数据集
数据集使用了SemEval2013和两个心理学领域的数据集
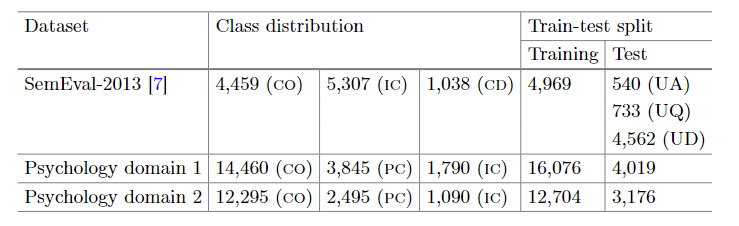
6.2. 实验
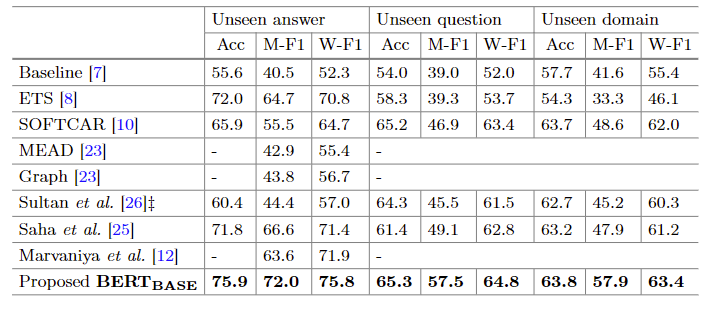
7. Investigating Transformers for Automatic Short Answer Grading
论文全称Investigating Transformers for Automatic Short Answer Grading,比对了不同的BERT-like架构在ASAG任务上的表现,主要探讨了多语言Transformer的表现、不同Pre-training tasks的表现、knowledge disillation的表现。用wmt2019表现最好的模型做翻译
7.1. 实验
总的实验结果:
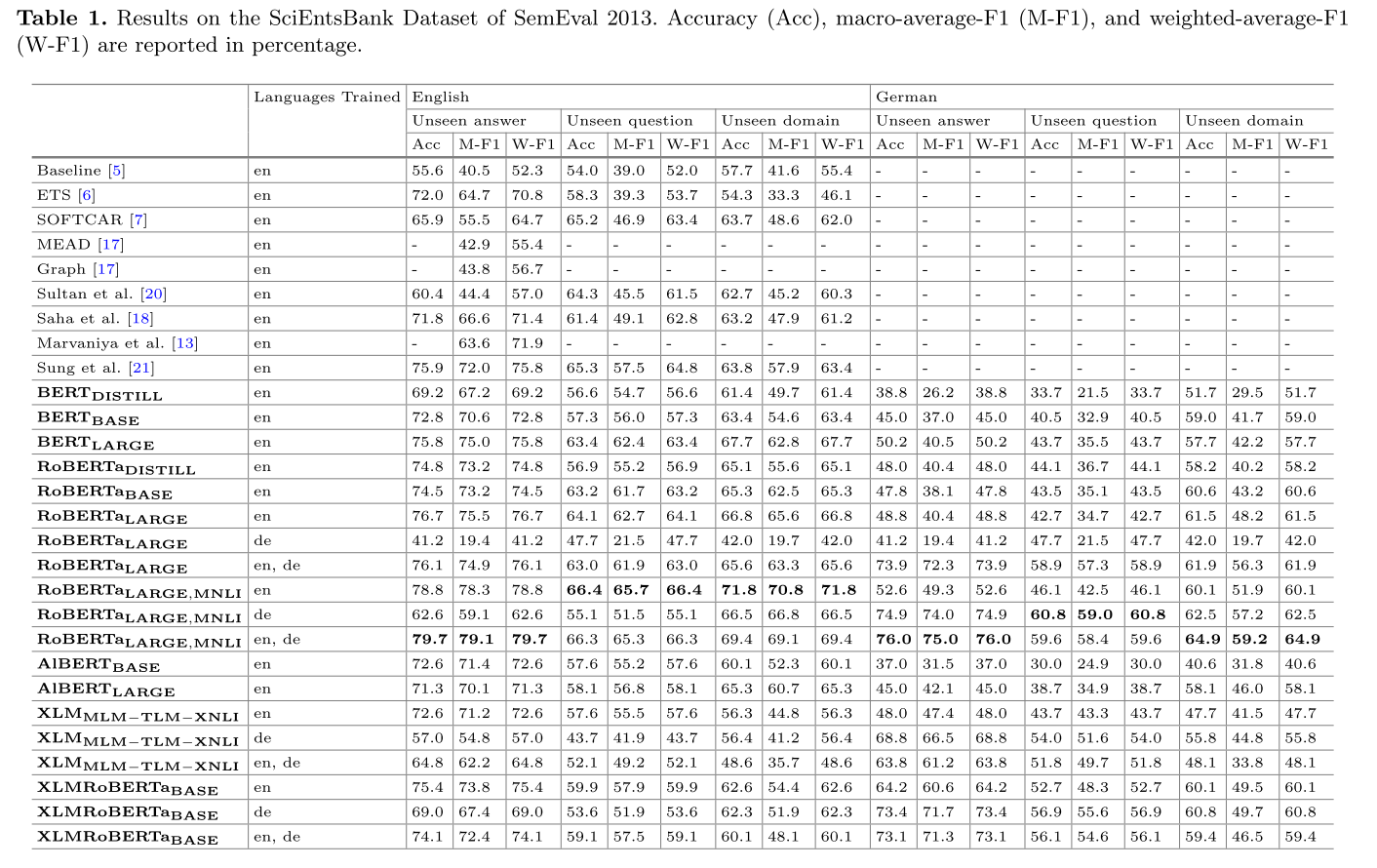
7.2. 结果分析
- 大模型能提升ASAG任务的效果吗: 可以
- 多语言Transformer的表现如何: 表现一般,XLM模型的表现不好,XLMRoBerta表现和普通的RoBerta差不多
- 预训练的时候采用多种语言可以提升模型的泛化能力,在别的语言上也能取得不错的效果
- 有更好的预训练任务吗: 实验结果表明,预训练任务MNLI(自然语言蕴含任务)能极大提升ASAG任务的效果
- knowledge distillation表现如何: 虽然说distil的bert性能会下降,但是在节省40%参数的情况下只降低了2%的效果,可以接受
8. Superlative model using word cloud for short answers evaluation in eLearning
论文的主旨是通过RA和SA生成词云(word cloud)的方法来辅助老师对短文本回答进行评估,生成词云的模型作者命名成superlative model
8.1. Superlative Model
生成词云的大致步骤:
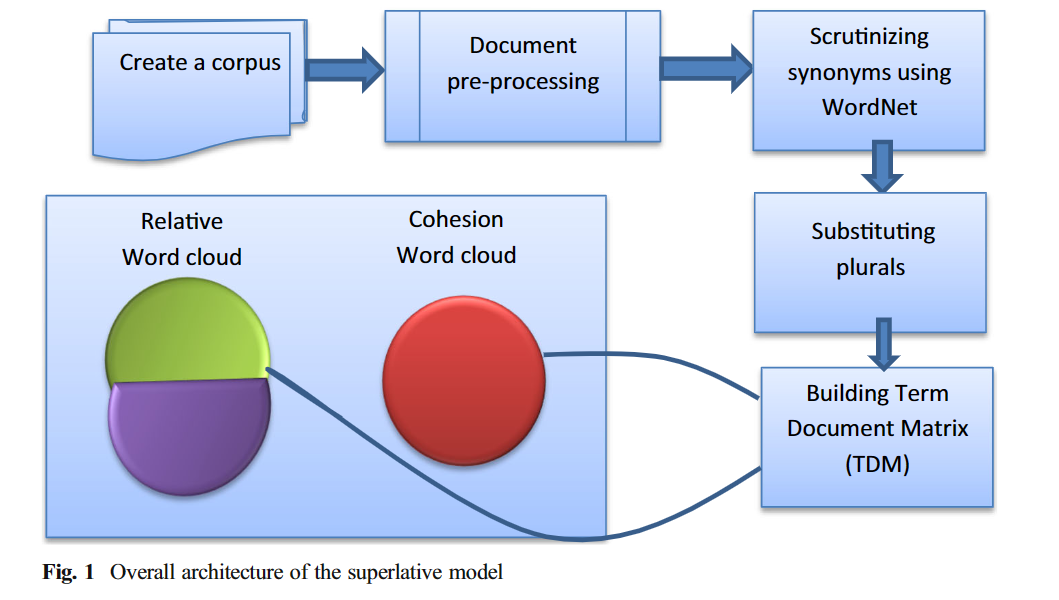
前面的几步可以看出数据预处理的步骤,这里我对其进行简单介绍:
- 把RA和SA拆成语料,也就是单个的单词
- 去掉无用的词,比如冠词、连词、问题包含的单词也可以去掉
- 通过wordnet(相当于一本词典),合并同义词
- 替换复数
- 生成单词-文本矩阵,行代表单词,纵代表文本,用哈希算法进行存储
- 生成词云
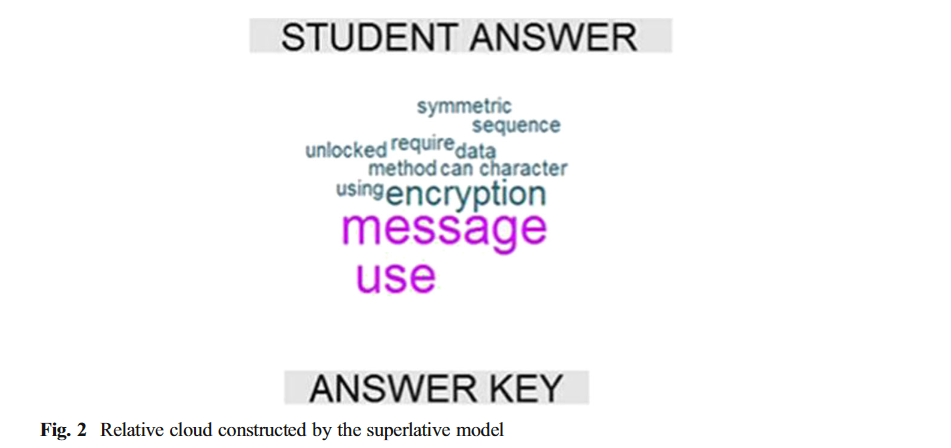
这里生成词云可以细说一下,主要生成了两种词云,作者对其命名为cohesion word cloud和relative word cloud。前者cohesion word cloud代表RA和SA的共同词组成的词云,后者是非共同词组成的词云,一个例子:

8.2. 词云 word cloud
词云(Word Cloud)又称文字云,是文本数据的视觉表示,由词汇组成类似云的彩色图形,用于展示大量文本数据。每个词的重要性以字体大小或颜色显示。
8.3. WordNet
WordNet是一个由普林斯顿大学认识科学实验室在心理学教授乔治·A·米勒的指导下建立和维护的英语字典。由于它包含了语义信息,所以有别于通常意义上的字典。WordNet根据词条的意义将它们分组,每一个具有相同意义的字条组称为一个synset(同义词集合)。WordNet为每一个synset提供了简短,概要的定义,并记录不同synset之间的语义关系。
wordnet可以获得两个单词之间的语义相似度
9.Sentence Level or Token Level Features for Automatic Short Answer Grading?: Use Both
9.1. Proposed Features
论文结合了hand-crafted feature(token level feature)和sentence-level feature(deep-learning)进行ASAG任务,模型的总览图如下:
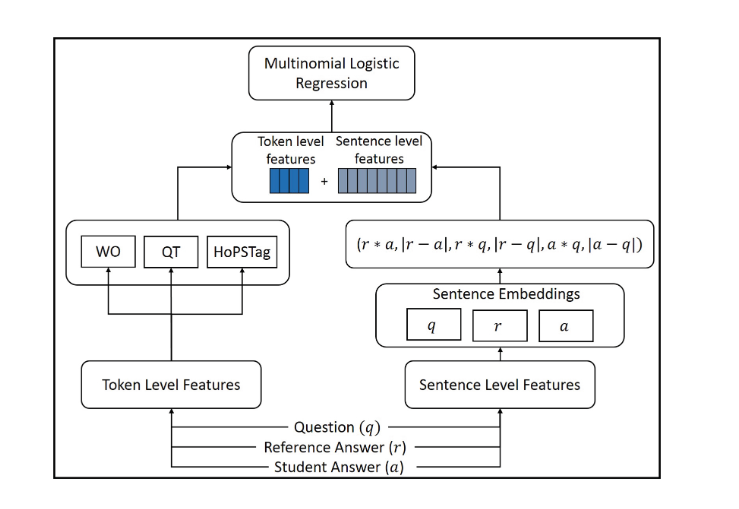
9.1.1. Sentence Level Features
对于问题,参考答案,学生回答(q,r,a)对而言,首先获得了这三个序列的sentence embedding,使用了InferSent模型,Infersent模型是一个有监督的语句嵌入模型,和sentence2vec有点像。获得qra的语句嵌入后,模型计算了以下的feature:
\begin{equation} S_{feat}(q,r,a) = (r * a, |r - a|, r * q, |r - q|, a * q, |a - q|) \end{equation}
9.1.2. Token Level Features
首先需要对数据进行预处理,和上一篇论文类似,首先需要去掉RA和SA中的stop words,就是一些没有意义的词,然后需要做question demoting,即去掉问题中出现的单词,接着就可以获得两个bag of words,一个是RA的,一个是SA的。然后就可以根据这两个词袋获得以下features:
- Word Overlap,词重叠。取RA中的每一个单词,和SA中的每一个单词计算分数,如果分数超过某一个阈值,那么就认为是overlapping的,分数的计算公式如下:
\begin{equation} Score(\omega_i,SA) = \mathop{max}_{\omega_j\in SA}Cos(\omega_i, \omega_j), where \quad \omega_i \in RA \end{equation}
或者根据wordnet中两个单词属于同一个synset来判断它是否是overlapping,随后计算出Precision/Recall/Precision*Recall来作为features
- Histogram of Partial Similarity(HoPS),HoPS的目标是捕获SA和RA之间的similarity pattern。对于RA中的每个单词$\omega_i$,计算与SA的相似度分数,然后可以得到index I的值:
\begin{equation} I(\omega_i)=min(\frac{Score(\omega_i, SA)+1}{h},N-1) where \quad h=\frac{2}{N} \end{equation}
- HoPs with POS tags and Question Types: 这个feature是HoPS的拓展,将RA根据词性分为动词,名称,形容词,副词和其他,然后计算HoPS时,将每个bin分为在RA中和该单词拥有相同词性的单词的个数。Question type就是问题的种类,作者分为了8类,分别是How, What, Why, Who, Which, When, Where, Whom,然后根据问题的类别生成8个二进制的feature
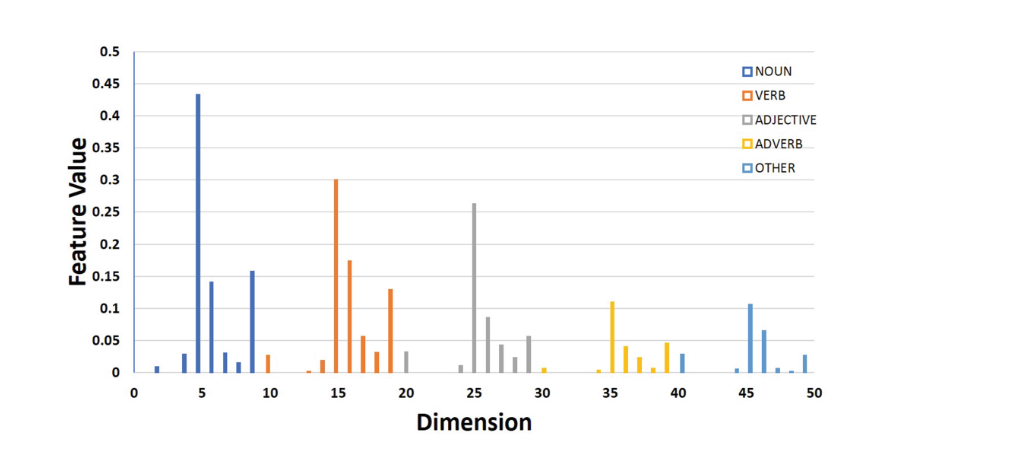
9.2. Token level的消融实验结果
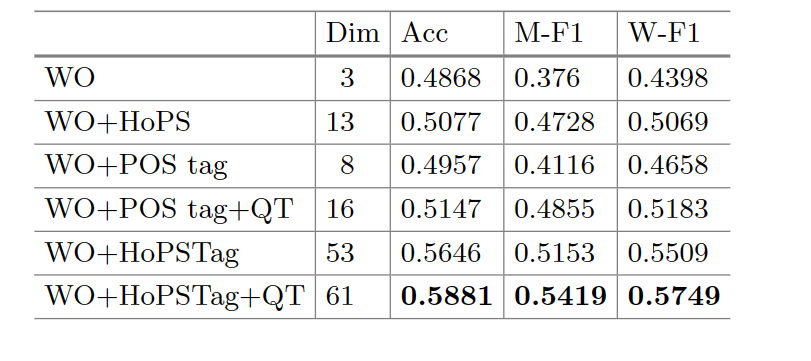
10. An Experimental Study of Text Preprocessing Techniques for ASAG in Indonesian
10.1. Introduction
论文介绍了一些针对于ASAG任务的预处理方法,它使用了印度尼西亚语的问题和答案
10.2. 预处理方法
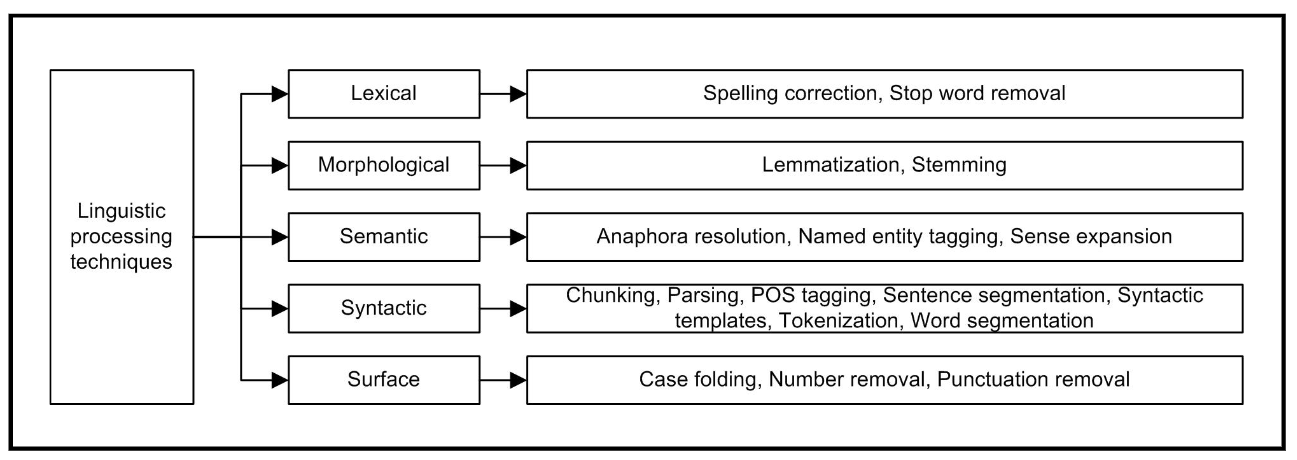
Burrows et al.总结了文本预处理的五方面技巧,分别是lexical, morphological, semantic, syntactic and surface,所对应的技巧如下图所示:
然后作者根据以往的研究,总结了应用于ASAG任务的五个预处理技巧:
- Case Folding: 将所有字母小写
- Tokenization: 将序列分成词元,在这个过程中可能会丢弃一些字符,比如标点符号
- Punctuation Removal: 在词元化后,会移除所有的标点符号
- Stop Word Removal: 一些common word在序列中可能并没有什么意义,这些词被称作stop word,需要去除
- Stemming: 去掉单词的词缀
10.3. Research Method
在预处理完毕后,计算RA和SA的余弦相似度,作为分数
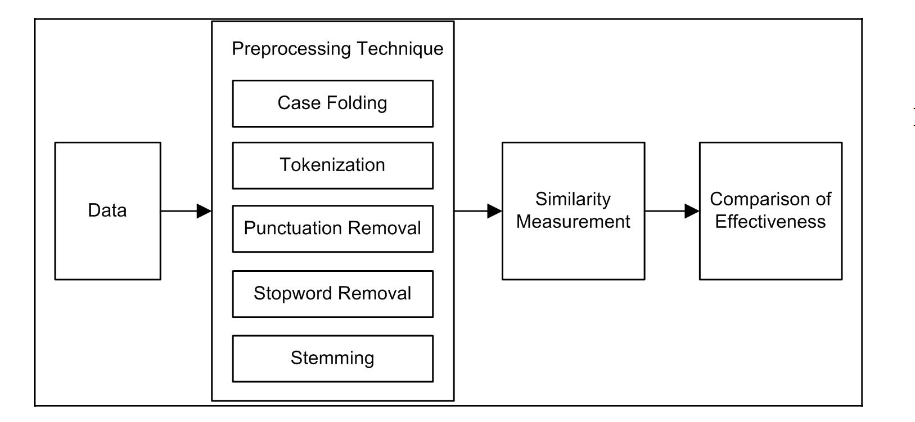
作者一共进行了两组实验,一组实验是使用了Tokenization和Punctuation的技巧,另一组实验多使用了Case Folding, Stemming, Stopword Removal的技巧,计算学生答案的平均分数和老师答案平均分数的correlation(相关性)和MAE,然后用t-test来判断两组实验是否有区别
10.4. 实验结果
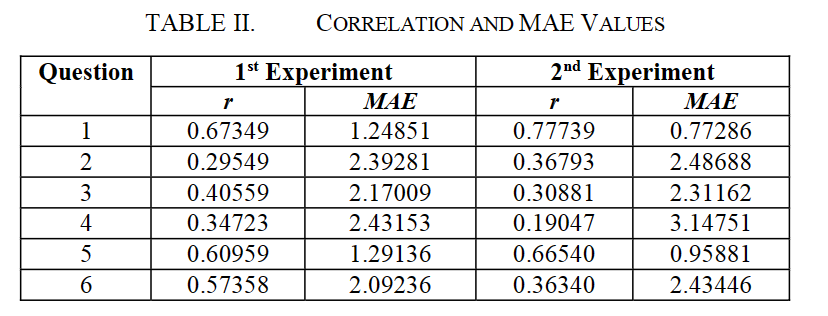
发现没有很大区别
11. Feature engineering and ensemble-based approach for improving automatic short-answer grading performance
11.1. Introduction
文章整合了ASAG领域的一些feature engineering的技巧,有传统的text similarity和一些新颖的features,比如relevance feedback based features, topic-modelling features, information retrieval motivated feature和Inverse document frequency based overlap feature。对比不同feature的效果,融合不同技巧进行ASAG任务(ensemble),有点像一篇综述
11.2. Problem Definition
11.2.1. ASAG as regression task
输入SA,RA,返回一个分数。回归任务的目标是学习一个回归模型$Y=f(\vec{X}, \vec{\omega})$,其中$\vec{X}$是一个n维的相似向量(similarity vector),通过n个RA和SA的相似度度量计算得出,模型的目标就是拟合出这些相似性度量的回归系数$\omega$,回归任务的性能度量是均方根误差(RMSE)和皮尔森相关系数$\rho$
11.2.2. ASAG as classification task
分类任务的本质其实和回归任务类似,分类模型的目标是计算出当前变量对于每个类别的分数,然后选出分数最高的类别作为分类类别,k是类别:
\begin{equation} \begin{aligned} & score(X_i,k)=\beta_k \cdot X_i \\ & k^*= \mathop{argmax}_i score(X_i, k) \end{aligned} \end{equation}
分类任务的性能度量是权平均F1值和Macro-average F1值
11.3. Feature extraction
作者将text similarity feature分为了以下6个类别并对其进行了简单介绍:
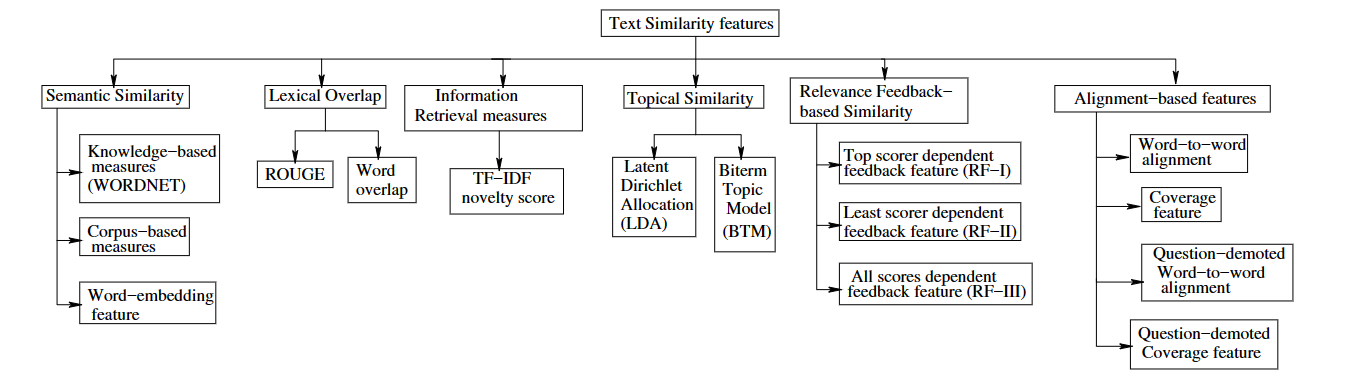
11.3.1. Semantic Similarity Features
- Knowledge-based measures: 使用WordNet查询单词的语义相似度
- Corpus-based features: LSA
- Word-embedding feature: 连续词袋模型(CBOW)和跳元模型(skip-gram)
11.3.2. Lexical Overlap Features
RA和SA之间的回答会有很多词重叠的部分,可以利用起来作为features:

- Word-overlap features: 有Jaccard Similarity Coefiicient, Simple word overlap等
- Summary evaluation measures: ROUGE-N,ROUGE一开始是广泛用于摘要生成的效果评估,具体做法是比较参考摘要和生成摘要共有的gram除以参考摘要的总gram数
11.3.3. Information Retrieval Measures
TF-IDF可以用于估计RA和SA之间的相关性和相似度,公式为:
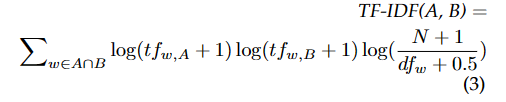
11.3.4. Topical Similarity Features
- Latent Dirichlet Allocation(LDA): 假设每段文本都在讨论多个话题的融合,每个话题由文本中出现的单词组成,LDA能处理多义词。每段文本都是由多个话题组成,那么就可以计算出RA和SA之间的话题相似度
- Biterm Topic Model(BTM): 相较于LDA而言,BTM处理短文本的能力更强
11.3.5. Relevance Feedback-based Features
通过学生的回答来更新原始的参考答案,这样可以增强参考答案的词汇量,生成这样的features分为两步,第一步是计算相似度,第二步是更新参考答案。不同features计算相似度的方法都是类似的
- similarity computation step: 通过LSA的方法计算出每个学生回答相对于参考答案的余弦相似度,作为similarity
- Top Scorer Dependent Feedback Feature(RF-I): 通过相似度最高的几个学生答案的单词对参考答案进行更新,这样可以重新计算出学生答案和参考答案的余弦相似度,也就是一种根据学生答案对参考答案进行更新的一种反馈机制
- Least Scorer Dependent Feedback Feature(RF-II): 和RF-I类似,但是更新变成了至少P个学生答案
- All Scores Dependent Feedback Feature (RF-III): 全部的学生答案对参考答案进行更新
11.3.6. Alignment-based Features
配对学生答案和参考答案的语义相近的单词获得的feature,这里作者没有详细介绍,说可以在word-to-word alignment using word-aligner中找到详细的解释
11.4. Answer Grading Models
使用了多个模型进行实验,既用到了单个的模型,也用到了集成学习的方法
11.4.1. Individual models
- Regression: 线性回归,支持向量回归,核方法脊回归(Kernel ridge regression),各种树等等
- Classification: 随机森林
11.4.2. Ensemble learning
对于回归任务而言,分为两步:
- ensemble generation: 生成单个的回归模型
- ensemble integration: 对单个的基模型进行集成
作者对不同的回归子模型使用了名为Stacked Regression的方法,就是对不同的模型进行滑动平均的方式对其进行集成,在基模型不止一种的情况下会有比较好的结果
11.5. Evaluation
11.5.1. Test Bed
针对回归任务,使用了University of North Texas数据集(UNT),针对分类任务,使用了SRA(Subsets of Student Response Analysis)数据集,这个数据集包含两个子集,一个是ScientsBank,一个是Beetle
11.5.2. 实验设计
一共设置了五组实验:
- Performance analysis of feature groups: 分析对比了不同feature的效果
- Feature significance tests: 分析feature是否重要
- Optimal feature set selection: 找出最好的feature set
- Ensemble-based regression- University of North Texas dataset: 判断集成学习在回归任务上的表现,先用数据集训练出单个的回归模型SVR,KRR,LR,LASSO,ELAS-TIC,TREE,BAG,BOOST,然后训练一个regressor(MLP)对这些模型预测的分数进行聚合
- 消融实验
11.5.3. 实验结果
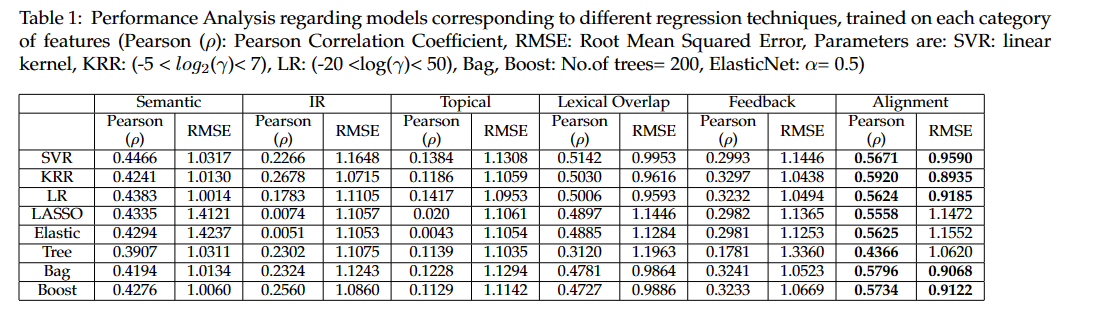
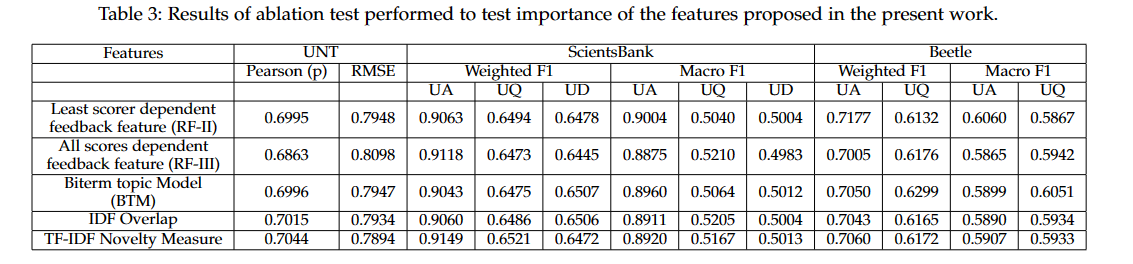
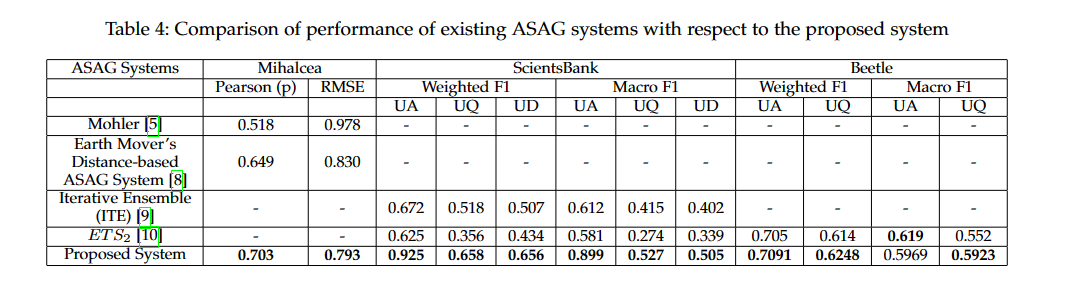
11.6. 总结
作者提出的stacked-regression模型相较于其他的模型而言表现更好,alignment-based feature, lexical overlapping features, semantic similarity feature都在其中起到了重要的作用,新加上的一些特征也能有效地提升模型的性能
12. Machine Learning Approach for Automatic Short Answer Grading: A Systematic Review
一篇整合了44篇使用了机器学习方法来解决ASAG的综述,综述的目标是让每一篇论文都回答以下四个问题:
- what is the nature of datasets?
- 使用了什么机器学习或者自然语言处理的方法?
- 选中的feature是什么?
- 实现了什么样的结果?
12.1. Nature of Datasets
往往是一个问题对应多个回答,问题多的数据集对应的回答会相对少一点,但一般来说只有一个参考答案。用的较多的数据集是Automated Student Assessment Prize(ASAP)和SemEval 2013中的两个数据集SciEntsBank和Beetle,最后还有回归任务使用较多的Texas数据集
12.2. Natural Language Processing Techniques
就是在特征提取的时候使用的一些预处理技巧,比如punctuation, numbers and other symbols removal, acronym expansion(首字母缩略词扩写), sentence segmentation, case normalization(大小写统一)和tokenization
除此之外,还有一些在使用回答的lexical时用到的技巧,有stopword removal, spelling correction and stemming and lemmatization(还原词干,就是去除后缀)
使用syntactic用到的技巧:part of speech tagging(词性)
使用semantic用到的技巧: Wordnet
12.3. Machine Learning Algorithms
使用到的机器学习方法有Artificial Neural Networks, Deep Belief Networks, K-Means
最常见的还是将ASAG任务视为分类或回归任务,使用到的机器学习方法有: 支持向量机,决策树,逻辑回归,Ridge Regreesion,朴素贝叶斯,K则最邻近和线性回归。有些文章使用了集成学习的方法: Stacked Generalization, 随机森林,Gradient Boosting Machine,Bagging和Adaptive Boosting
12.4. Features
作者将使用到的feature分为了三类: lexical, syntactic and Semantic
- Lexical: N-gram(n=1时就是常见的词袋Bag of Words),用词出现的频率作为权重构建矩阵。ROUGE, BLUE, Word2vec, lexical similarity。还有一些广泛用到的feature有count of words, response’s length, verb counts等等
- Syntactic: phrase ngrams(combination of the main verb and their noun phrase), denpendency ngrams(syntactical relations between words), similarity between RA and SA POS tags
- Semantic: knowledge-based features(WordNet), corpus-based similarity(LSA,ESA…)
12.5. Systems’ Evaluation
不同数据集,不同模型的evaluation:
13. Automatic Short Answer Grading via Multiway Attention Networks
13.1. Introduction
ASAG任务的两大困难点: 1. 短文本回答需要有较深的语义理解 2. 问题往往是开放式的,同时涵盖了多个领域
为了解决以上问题,作者提出了用深度神经网络来解决,作者提出了:
- 一种end-to-end的方式来解决ASAG任务,不需要人为地提取特征
- 一种新的框架,可以拟合RA和SA的语义关系
- 可以在多领域使用
13.2. Approach
总体的模型架构如下:
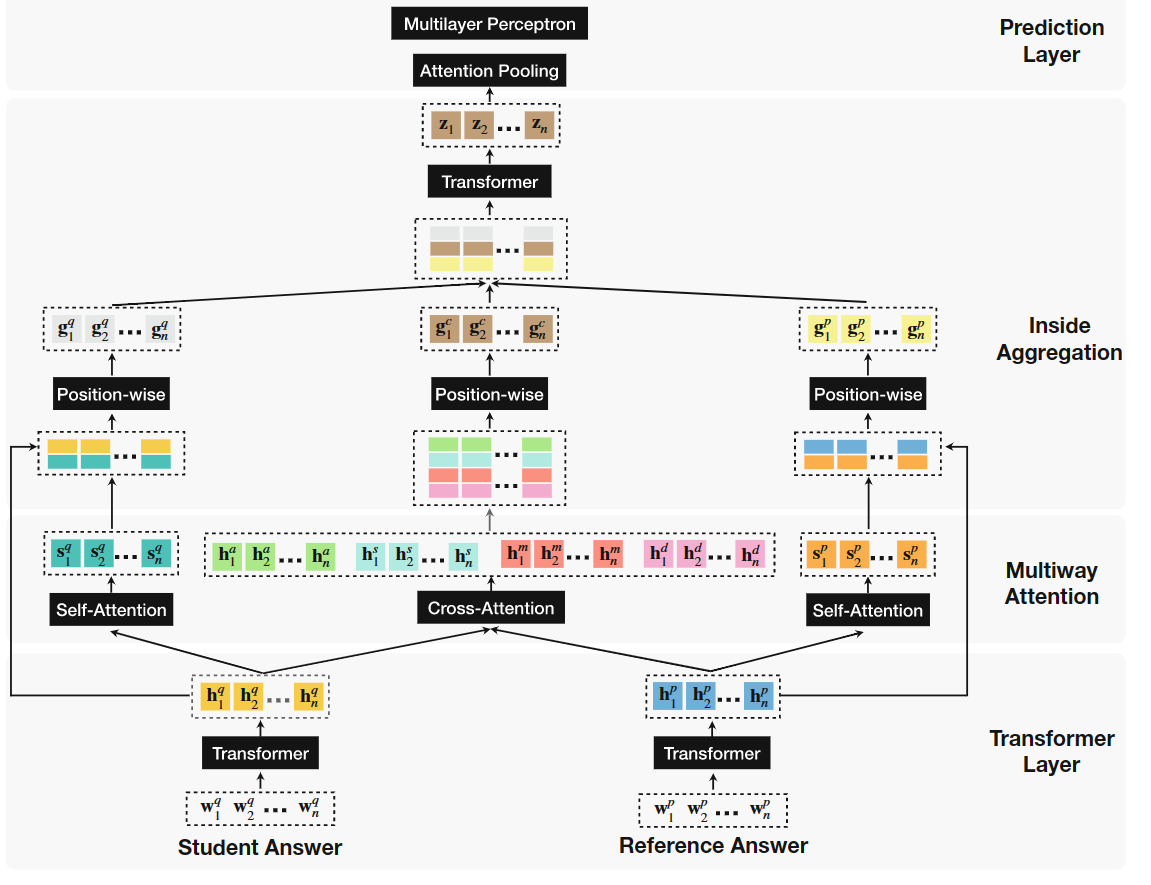
- Multiway attention: 重点讲一下中间那个cross-attention,每个$h^q_i$都会和其余的每个$h^p_j$计算注意力权重,一共有四组输出,分别代表不同的注意力机制,{a,s,m,d}分别对应addictive, subtractive, multiplicative, dot-product
- Inside Aggregation: 聚合之前的三组结果,使用了Transformer对其进行聚合
- Prediction Layer: 通过self-attention pooling layer把aggregated sequence representation变成一个定长的向量,注意力池化和注意力机制好像没太大区别,作者这里使用的变化公式为:
\begin{equation} x=softmax(w^z_1tanh(W^z_2Z^T))Z \end{equation}
其中$w^z_1$和$W^z_2$是可学习的矩阵,变换后输入MLP得到预测结果,这里作者将其视为二分类任务
13.3. 实验结果

14. Automated Short-Answer Grading Using Deep Neural Networks and Item Response Theory
14.1. Introduction
作者提出了一种结合DNN(Deep Neural Networks)和IRT(Item Response Theory)的模型,简单来说就是在提问时加上一些判断正负的客观问题来辅助评分,这种方法可以适用于任何一个DNN-ASAG模型,作者这里采用最标准的LSTM-ASAG模型来演示
14.2. Proposed Method
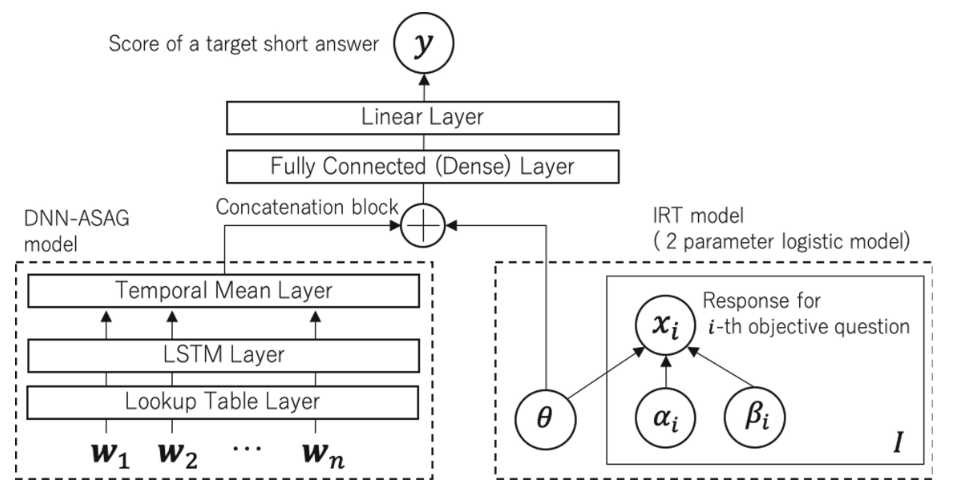
模型整体架构如上图所示,首先介绍一下DNN部分,word sequence首先经过look up table layer,这个layer的作用是把单词转换成词元,也就是word embedding representation,接着LSTM layer将其转换成hidden vector,接着经过一个temporal mean layer,将vector输出成一个定长的vector M。
接着介绍一下IRT model,作者使用了一个名为two-parameter logistic IRT model来获得学生的ability $\theta$,学生回答正确的概率公式如下:
\begin{equation} (1+exp[-\alpha_i(\theta - \beta_i)])^{-1} \end{equation}
其中$\alpha_i$和$\beta_i$分别代表问题的区别系数和难度系数, $\theta$就是学生的ability
concatenate两者的输出后,经过一个MLP进行降维,然后输入线性层输出最终结果
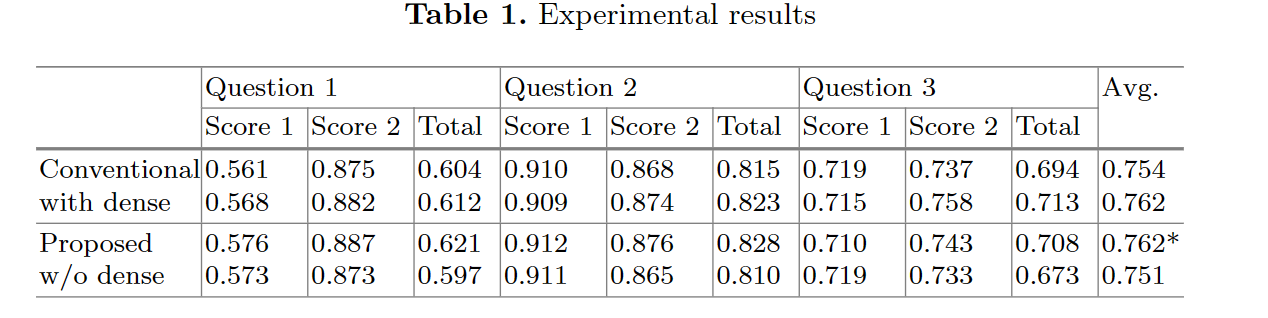
14.3. 实验
实验结果如下所示:
15. Comparative Evaluation of Pretrained Transfer Learning Models on Automatic Short Answer Grading
15.1. Introduction
作者对比了四种不同的预训练迁移学习模型ELMo,GPT,GPT-2,BERT在ASAG任务上的表现,主要方法就是利用这几种模型的词嵌入做cosine相似,作者对比了RMSE分数,发现ELMo的效果最好
15.2. Experiment
实验结果如下:
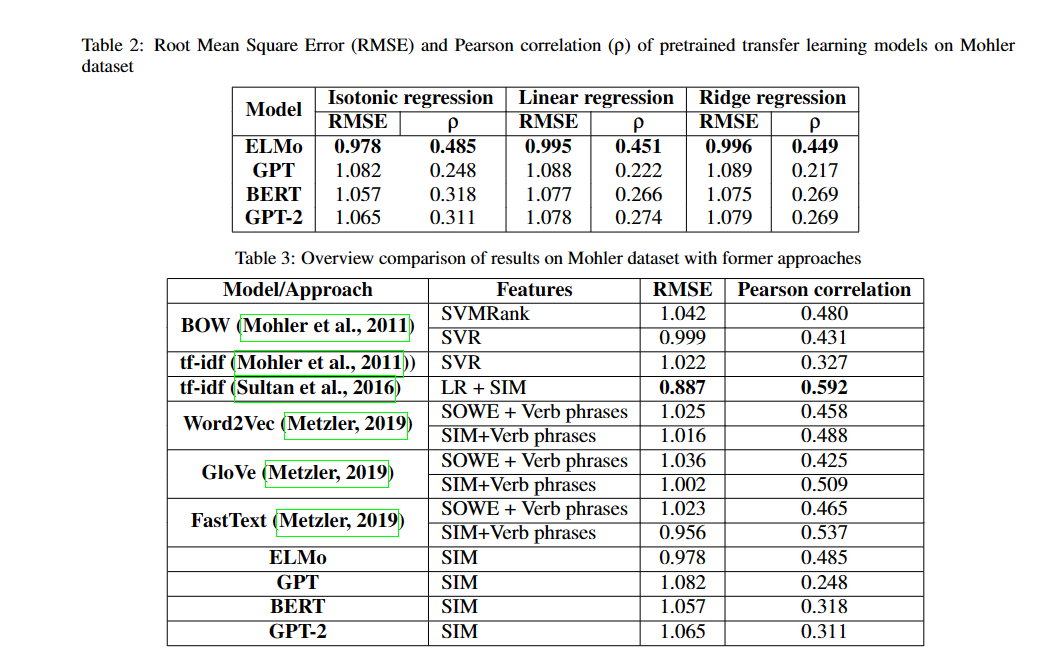
除了四种预训练模型外,作者还对比了与其他word embedding的模型的区别,并尝试解释其原因
16. Going deeper: Automatic short-answer grading by combining student and question models
16.1. Introduction
作者总结了在ASAG任务领域的一些answers-based模型,认为没有考虑到question的作用,于是结合了question model和answers model,并研究了deep belief networks(DBN)在ASAG领域的表现,发现应用question models于传统的answer-based模型能提升其表现,同时发现DBN的效果不错,强于传统的机器学习方法
16.2. State features
16.2.1. Answer model
每个问题都有对应的参考答案(referred correct answers),在最开始,answer space只有参考答案,但随着训练过程,不断有学生答案被鉴定为正确并加入到answer space里,通过词袋的方式对answer space进行建模,作者称其为word-answer matrix,横坐标表示单词,纵坐标代表不同的答案,每一行每一列的数值等于这个单词在回答中出现的次数,这个矩阵会动态更新
answer model主要包含了以下6个特征:
- length difference: 学生答案和参考答案的句子长度差
- cosine similarity: 通过学生答案和参考答案的tf-idf向量计算余弦相似度,TF-IDF是一种用于资讯检索与资讯探勘的常用加权技术,TF-IDF是一种统计方法,用以评估一个单词对于一个文件集或一个语料库中的其中一份文件的重要程度,单词的重要性会随着它在文件中出现的次数成正比增加,但同时会伴随着它在语料库中出现的频率而成反比下降
- max-matched idf: 衡量了一个学生答案在answer space中词重叠的信息,idf衡量了一个单词能提供的信息
- LSA: LSA用来评估一个学生回答的质量,具体方法就是拿他与其他正确答案进行比较
- Domain-specific text similarity: 在sentence level衡量学生答案和参考答案的相似度,具体做法就是让专家手动的列一个领域词汇表dl,然后就计算学生答案s和参考答案c的相似度:
\begin{equation} sim_d(s,c)=\sum_{\omega_1 \in sv}\sum_{\omega_2 \in cv} 1_{dl}(\omega_1) \cdot 1_{dl}(\omega_2) \end{equation}
其中1代表指标函数,当$\omega_1$在list中时为1,其次sv和cv分别代表matrix中的学生答案向量和参考答案向量
- general text similarity: 测量了学生答案和参考答案的整体文本相似度,记为$sim_g(s,c)$,计算它之前,首先需要计算word-level的相似度$sim_w(C_1,C_2)$,公式如下:
\begin{equation} sim_{\omega}(C_1,C_2)=\frac{2*depth(LCS)}{depth(C_1)+depth(C_2)} \end{equation}
上式中$C_1$和$C_2$代表两个concept,depth(·)表示concept沿概念树的边数,所以这里需要借助一个knowledge-based dictionary,这里作者使用了WordNet,LCS全称为Least common subsumer,即最小公共包含,即$C_1$和$C_2$在概念树上的最小公共祖先节点
然后就可以计算$sim_g(s,c)$了,具体公式如下,其中$dl_c$表示领域词列表的补集:
\begin{equation} sim_g(s,c)=\sum_{\omega_1 \in sv}\sum_{\omega_2 \in cv} 1_{dl^c}(\omega_1) \cdot 1_{dl^c}(\omega_2) \cdot sim_{\omega}(\omega_1, \omega_2) \end{equation}
集合5和6,可以计算出一个归一化的sim(s,c),就是对5.和6.的公式加权得到,权重分别为0.6和0.4,最后,给定了一个学生答案,学生答案将和answer space中所有的参考答案都计算相似度,然后最后求平均
16.2.2. Question model
不同于大多数的ASAG系统是question-specific的,作者提出了一种domain general的ASAG系统,不是针对每个问题都建立一个分类器,而是对所有的问题都建立一个分类器。为了实现这样的目标,需要有一个question model把问题分成一个general feature space,这样才能保证ASAG模型能学习到一些feature。具体而言,作者设计的question model包含两个主要的特征:
- Knowledge Components(KCs): 构建一个Q-matrix来表示单个的问题和KCs间的关系,Q-matrix是一个qxk的二维矩阵,q代表问题,k代表KCs。比如说$Q_{jk}$=1代表问题j是KC中k的一个应用。这里作者让专家来设计这个矩阵,一旦有学生回答了一个问题j,就从Q-matrix把第j行拿出来,然后添加到特征向量中
- Question Diffuiculty: 本来KCs的feature只有八个,这个问题难度将作为第九个feature加入Q-matrix中,根据专家的评判以及学生回答这个问题的情况来决定
16.2.3. Student model
Student model可以定义为收集相关信息的过程,以推断学生当前的认知状态并对其进行表示,以便辅导系统可以访问和使用以提供适应性。Bayesian Knowledge Tracing(BKT)是在ITS领域中应用最广的student model。BKT利用学生与辅导系统的交互的序列信息来更新它对于该学生潜在知识掌握能力的评估。
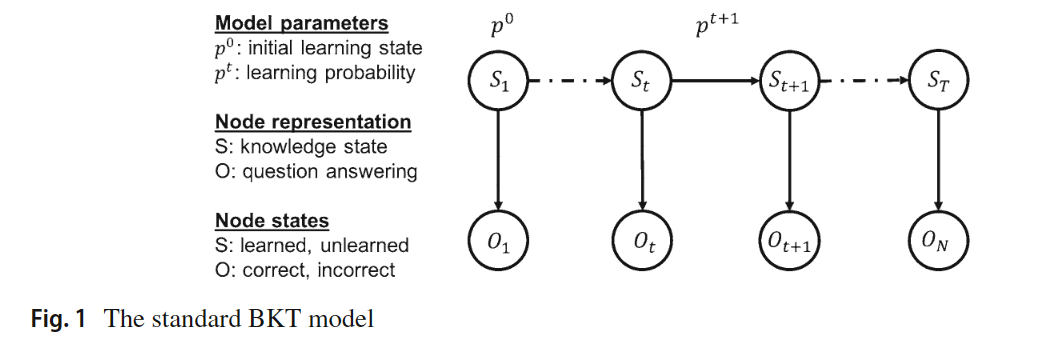
总的来说,Student model有16个feature,对于KCs的每一列而言,它用BKT来估计学生在每一个KC上的掌握水平
16.2.4. Composite feature space
结合了以下student model和question model的一些特征
16.3. Six Classifiers
使用了六个分类器来通过前面提到的特征预测学生在某个问题上的回答情况,分别是: 朴素贝叶斯,逻辑回归,决策树,支持向量机,ANN和DBN
16.4. Data
为了能有效地利用这些特征,数据集的准备也是别有用心,数据集采自Cordillera,一门教导学生大学物理的课程,它属于能量领域的,KC的特征有动能,重力势能等等。158名学生参与了数据收集的过程: 首先参加背景的调研,然后学习课本和先修材料,然后参加预测试,接着在Cordillera做题,最后参加考试
16.5. 实验
16.5.1. 实验设置
总共设置了三个阶段的实验,如下图所示:
16.5.2. 实验结果
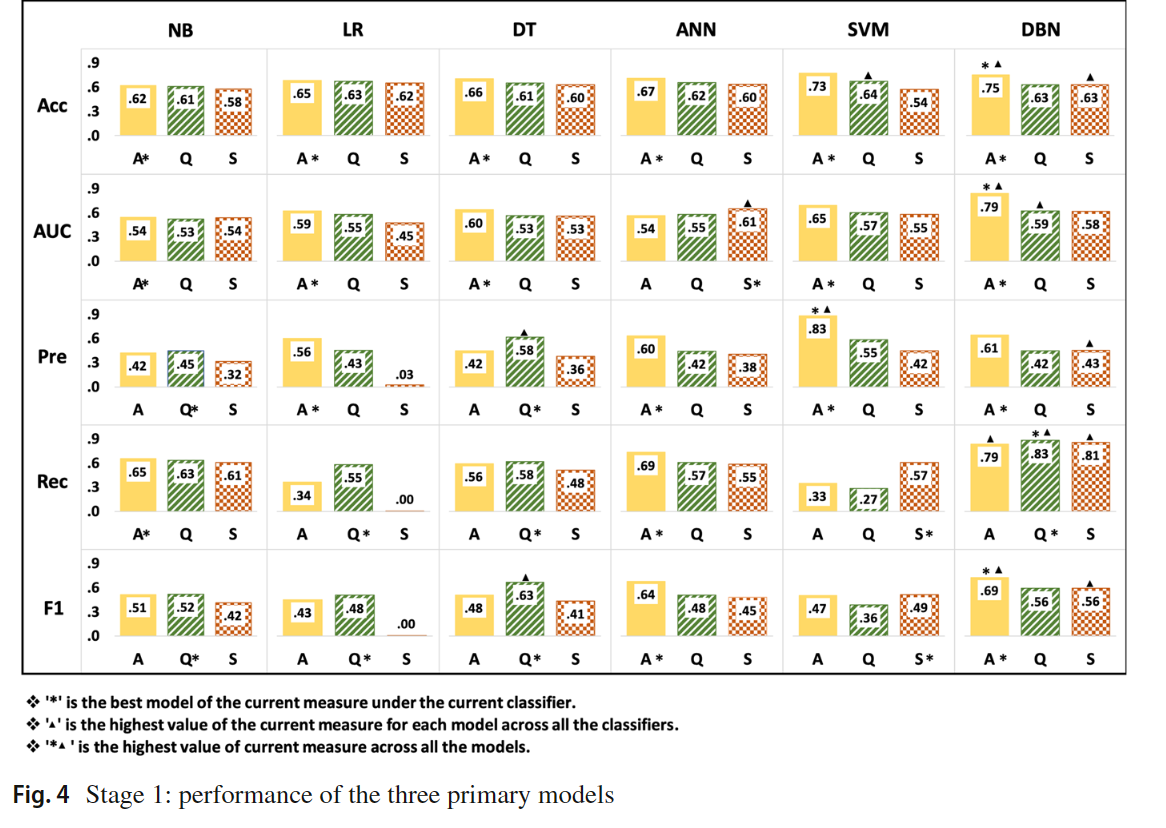
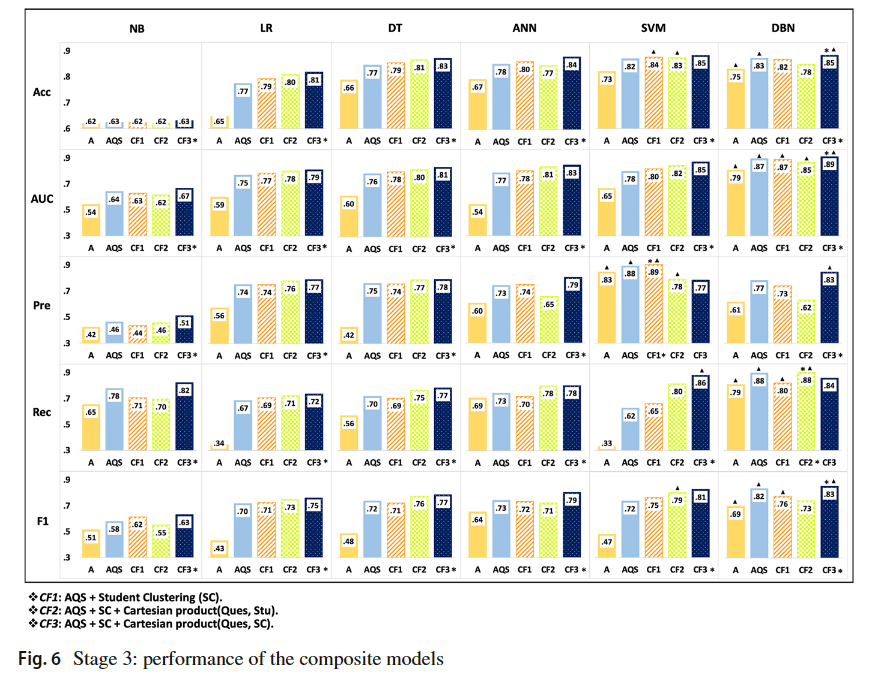
16.6. 总结
实验结果表明,Question model和student model的加入能增强answer model的效果,其次就是DBN相较于传统的机器学习方法表现更好
17. Automatic Short Answer Grading With SemSpace Sense Vectors and MaLSTM
17.1. Introduction
作者提出了利用Semspace的sense vector输入MaLSTM从而实现ASAG任务,Semspace是一个基于WordNet中synset的一种sense embedding的方法,后续会具体介绍。文章的两大关键组成部分是SemSpace和Manhattan LSTM(MaLSTM)
17.2. Method
模型实现分为以下三步:
- 基于WordNet的同义词集训练SemSpace算法
- 根据Word Sense Disambiguation,将数据集分为词元
- 训练MaLSTM
17.2.1. Determining Sense Vectors with Semspace Method
Sense Embedding就是根据词的意思来生成词表示,与Word2Vec,Glove,FastText等有区别,后者无法处理多义词。SemSpace是sense embedding的一种方法,作者这里对它进行了一定的改动,在运行Semspace算法时,节点间的关系用欧式距离表示,然后根据WordNet中同义词集的关系(或者说相似度),调整向量,两个向量之间的相似度通过以下公式计算:
\begin{equation} Sim(V_1, V_2)=e^{-\|V_1-V_2\|} \end{equation}
其中$V_1$和$V_2$分别表示sense vector的欧式距离,如果两个向量的相似度超过了它们之间的relation weight,那么就把两个向量拉近,反之则拉远。这就是SemSpace算法训练过程中向量位置的变化
预处理步骤:
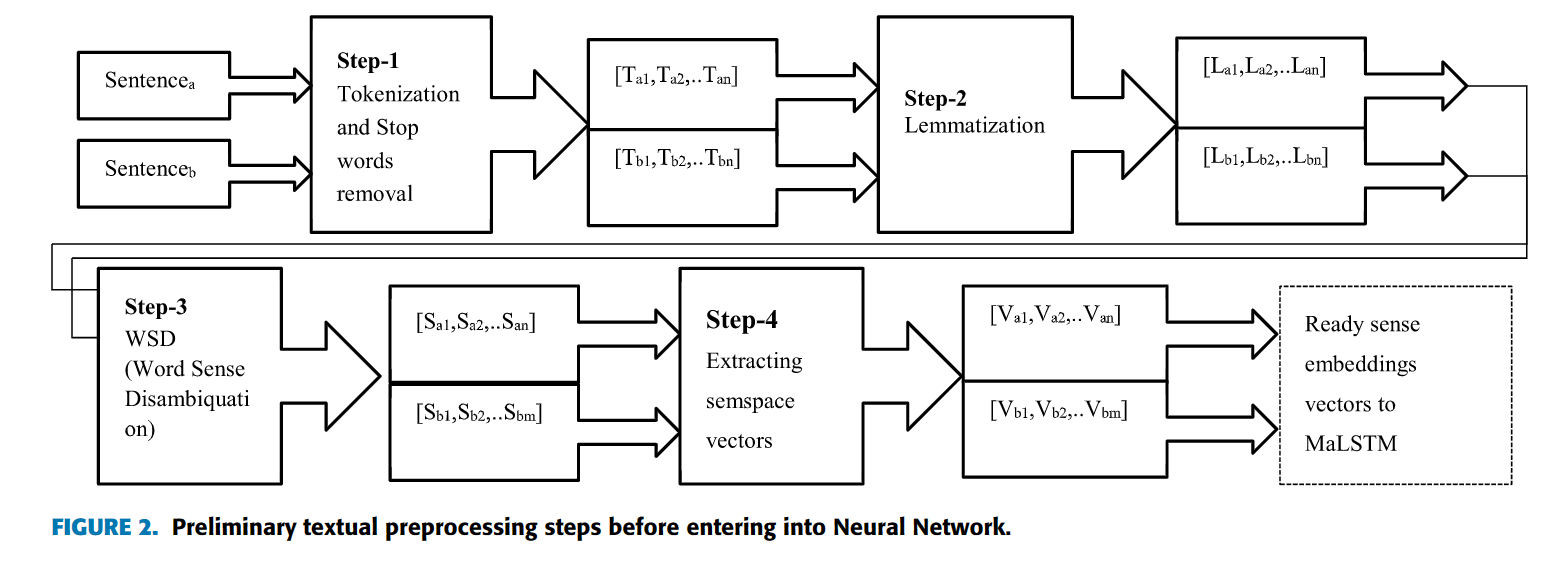
Sentence a和Sentence B分别代表学生答案和参考答案,那些包含多个WordNet同义词集的单词会通过WSD处理:
\begin{equation} C_{WSD}=\mathop{argmin}_{G_j}\sum _i^N \|C_j-P_i\| \end{equation}
N是context cluster的同义词集数量,$C_j$表示歧义词的候选同义词集,$P_i$是context cluster的sense vector表示,context cluster就是整个数据集出现最多的单词的集合
17.2.2. Grading with MaLSTM
MaLSTM被广泛用于句段相似的应用中。模型的主体架构如下图所示:
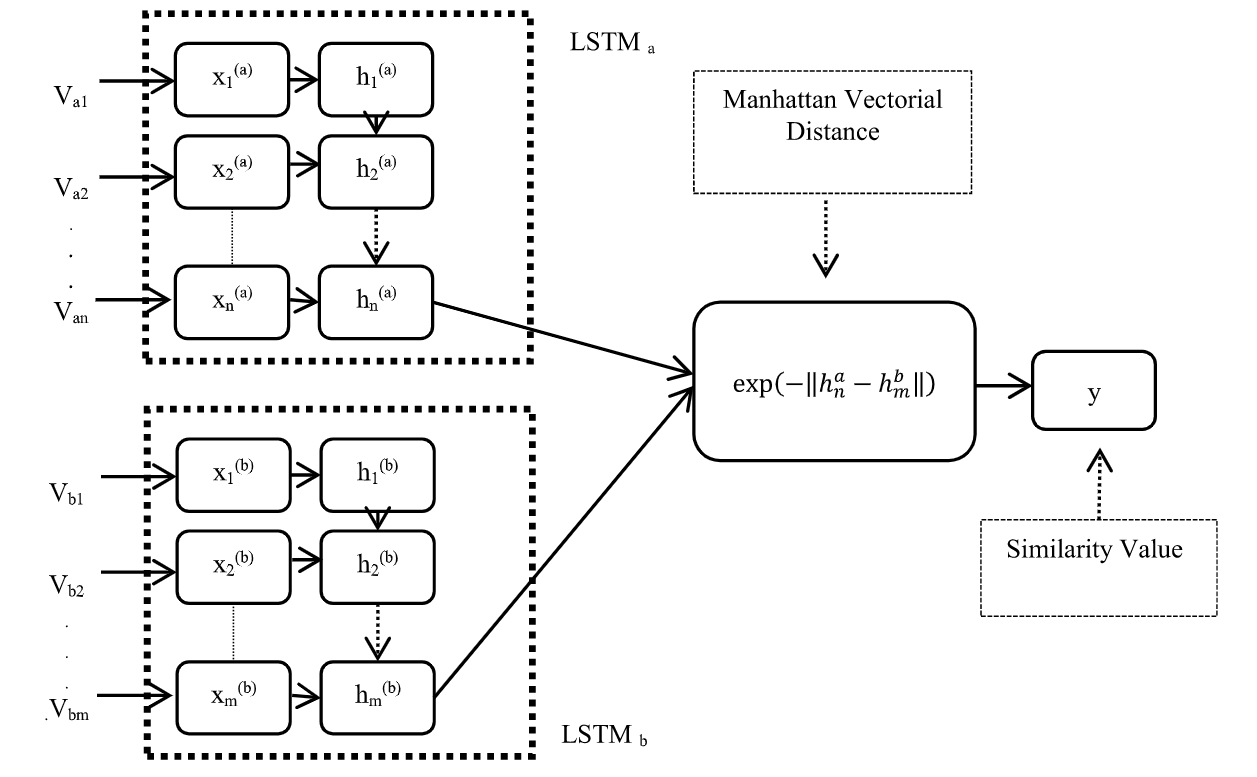
学生答案和参考答案分别输入不同的LSTM模型中,得到sentence representation(在LSTM的最后一个隐层),然后计算两个向量之间的Manhattan distance,归一化后将范围控制在0,1之间,得到的结果作为相似度。曼哈顿距离标明两个点在标准坐标系上的绝对轴距总和。
17.2.3. Datasets
使用了两个数据集,一个是Mohler数据集,另一个数据集是CU-NLP
17.3. 实验
实验结果:
18. A Semantic Feature-Wise Transformation Relation Network for Automatic Short Answer Grading
18.1. Introduction
作者提出了一种新的网络模型来解决ASAG任务,名称为Semantic Feature-wise transformation Relation Network(SFRN)。SFRN是一个端到端的模型,有三个组成部分,encoder首先编码QRA对,生成QRA的向量表示。当一个问题存在多个参考答案时,relation network将单个的QRA向量转化成single relation vector,接着一个学习过的feature-wise transformation function融合了所有relation vector。最终,分类器决定每个学生答案对应的分数或者类别。
为了解决数据不足和类别不平衡的问题,作者采用了一个简单的数据增强(data augmentation)的方法,back-translation。ASAG的数据集相对来说小。back-translation能从数据集中已经存在的数据生成新的数据。
18.2. SFRN
18.2.1. Relation Network
Relation network,关系网络,最初是用在CV领域,用来学习不同类别的物体的区别,这里作者用来寻找不同text vector之间的关系,Relation Network可以用下面这个公式简单表达:
\begin{equation} RN(O)=f_{\phi}(\sum_{i,j}g_\theta(o_i,o_j)) \end{equation}
公式里O是输入物体的集合,f和g是可以训练的带参函数,g用来学习物体对的关系,返回一个抽象的表示,输入f,f是分类器
18.2.2. QRA relation vectors
假设向量化的QRA对为$(q,r_j,a)$,对于一个问题而言,共有n个参考答案。生成relation vector的过程图如下所示:
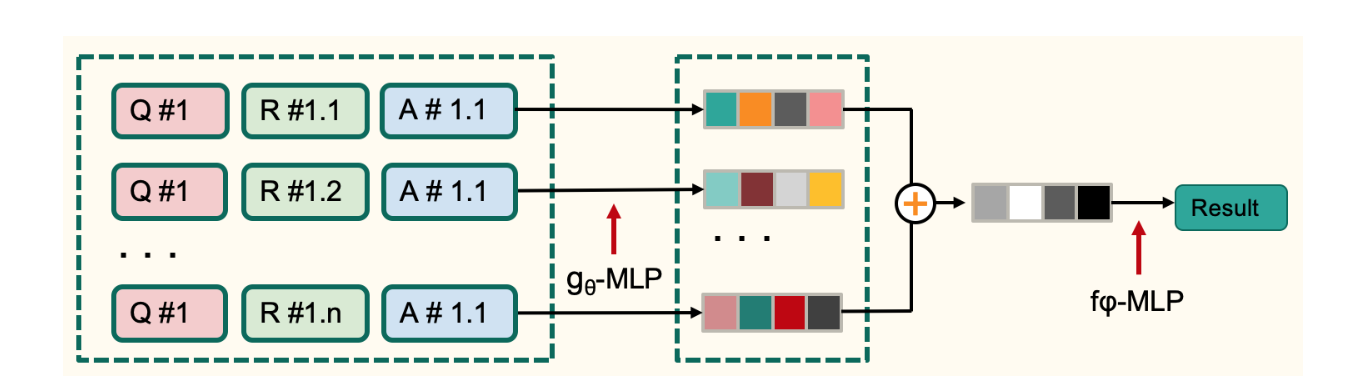
q,r,a首先concate在一起输入$g_\theta$,g是一个MLP,参数为$\theta$,假设共有n个qra对,那么会生成n个relation vector $l_j$
18.2.3. Relation Fusion
接着就需要把这n个关系向量融合在一起,原本的Relation Network会把它们加起来,然后输入到分类器f中,但是一般情况下关系都是二元的,对于ASAG任务而言,qra是三元的,所以作者对其进行了一定的修改。作者使用了Semantic Feature-wise Transformation(SFT)来融合n个关系向量,具体的公式如下:
\begin{equation} SFT(C,L,n)=\sum_{j=1}^n(\alpha(c_j)\odot l_j+\beta(c_j)) \end{equation}
公式中C代表qra set,L表示关系向量set,n表示参考答案的个数,$c_j$是qra pair concatenate的结果,$\alpha$和$\beta$是MLP。
SFT得到的结果输入到分类器中得到最终的分类结果,所以整体上来说SFRN能写成:
\begin{equation} SFRN([Q,R,A])=f_\phi(SFT(g_\theta)) \end{equation}
18.2.4. SFRN Encoder
剩下还有一部分没有介绍,就是encoder部分。作者实验了不同encoder的效果,baseline model使用了LSTM作为encoder,除此之外,还使用了BERT作为encoder,取BERT最后一个输出层的输出
18.3. Data Augmentation
鉴于SemEval ASAG数据集只包含有限的数据和严重的数据倾斜问题,所以作者采用了Back-translation的方法来做Data Augmentation。Back-translation就是将数据从原始语言翻译为一个或多个其他语言,然后再把翻译结果从其他语言翻译成原始语言。作者这里使用的语言是汉语和法语。作者使用了EasyNMT网络和谷歌翻译的API来完成这个操作

实验Data Augmentation发现,数据平衡对实验结果影响不大,除非重平衡的类和原始类的数据量差别很大。并且并不是数据扩大的倍数越大越好,如果一个类别和数据量最大的类别的差异有五倍,那么作者会double这个类别
T-test的实验结果
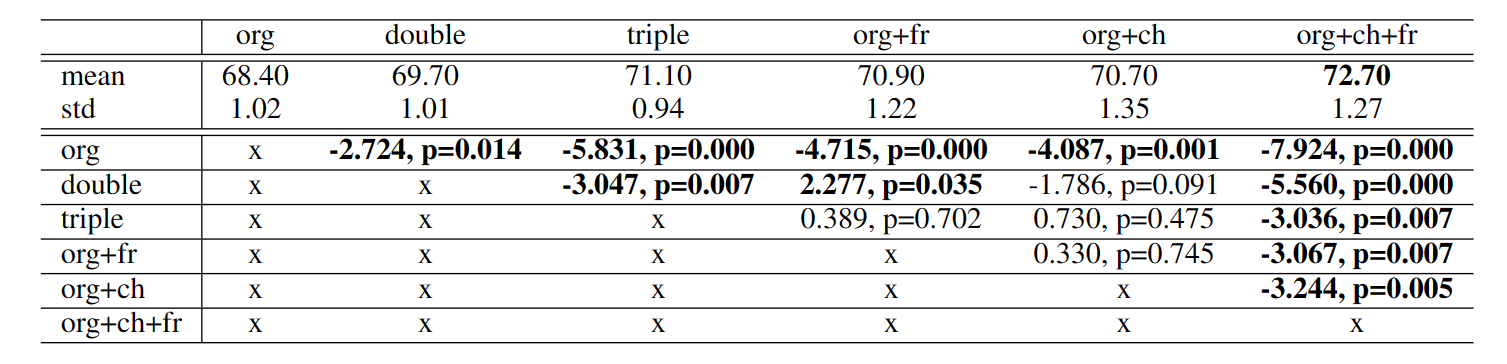
T-test一般用来检验不同参数设置的实验结果是否有显著的差别
18.4. 实验
和多个其他baseline进行了对比实验,并且分别在Bettle数据集,SciEntsBank数据集和数据增强过的两个数据集上做了对比试验,其中应用了Bert作为encoder的模型表现最好
19. An automatic short-answer grading model for semi-open-ended questions
19.1. Introduction
传统的ASAG通过对比RA和SA的相似度来评估SA的分数,这种方法对于closed-ended question有不错的效果,因为这些问题只有限定数量的RA。但是对于半开放的问题,比如阅读理解题,参考答案相对来说更多更广泛,作者提出了一种基于LSTM的方法实现半开放问题的短文本答案的评估
19.2. Proposed model
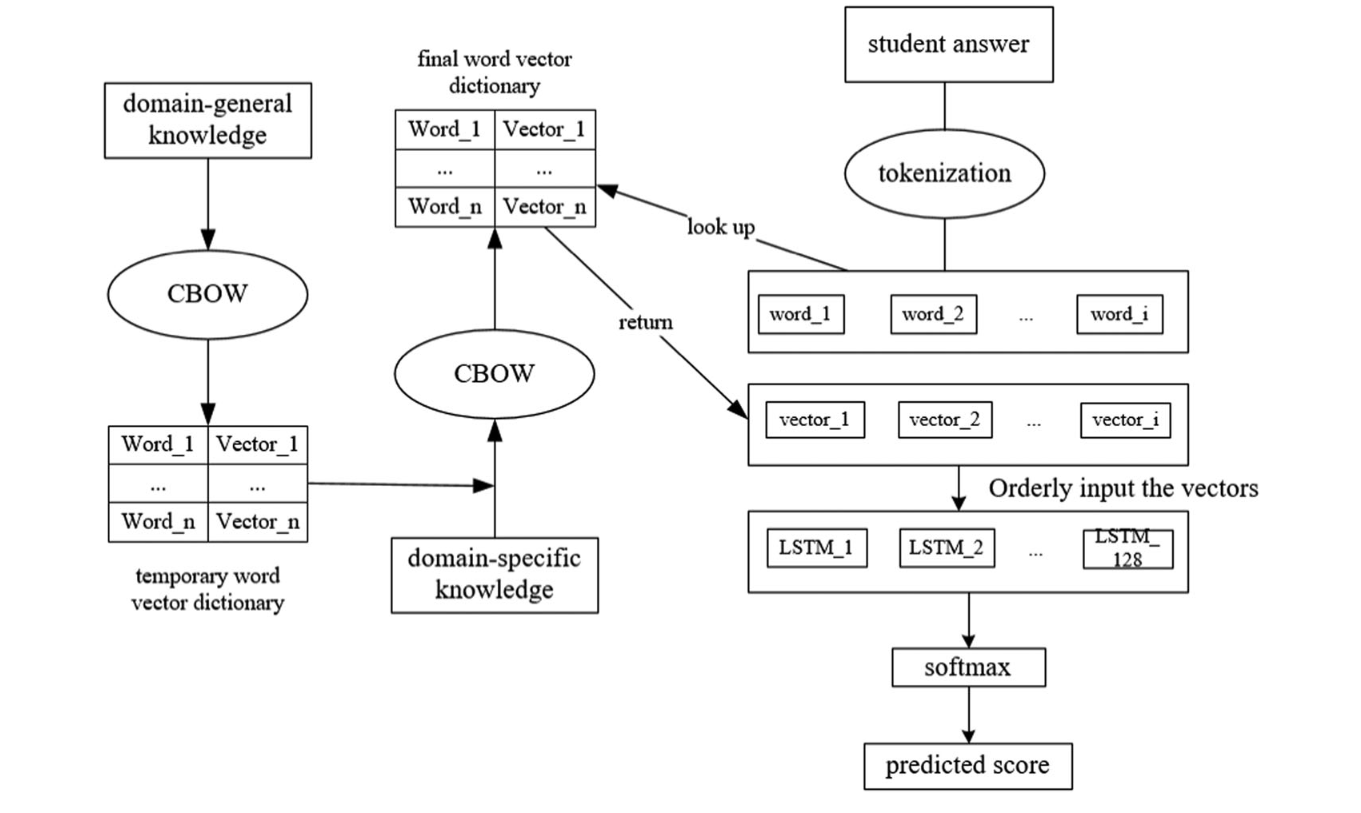
结合domain-general information和domain-specific information来解决ASAG任务,前者的信息提取自Wikipedia,后者的信息来源于已标注的学生答案。同时利用LSTM来提取句段信息。模型的大体架构如下图所示:
19.2.1. CBOW
Continuous bag-of-words连续词袋模型,简称CBOW,是一种将word embedding的手段,让语义相近的单词在嵌入空间的距离更近,在之前,LSA和LDA也是常见的word embedding的手段。CBOW模型如下图所示:
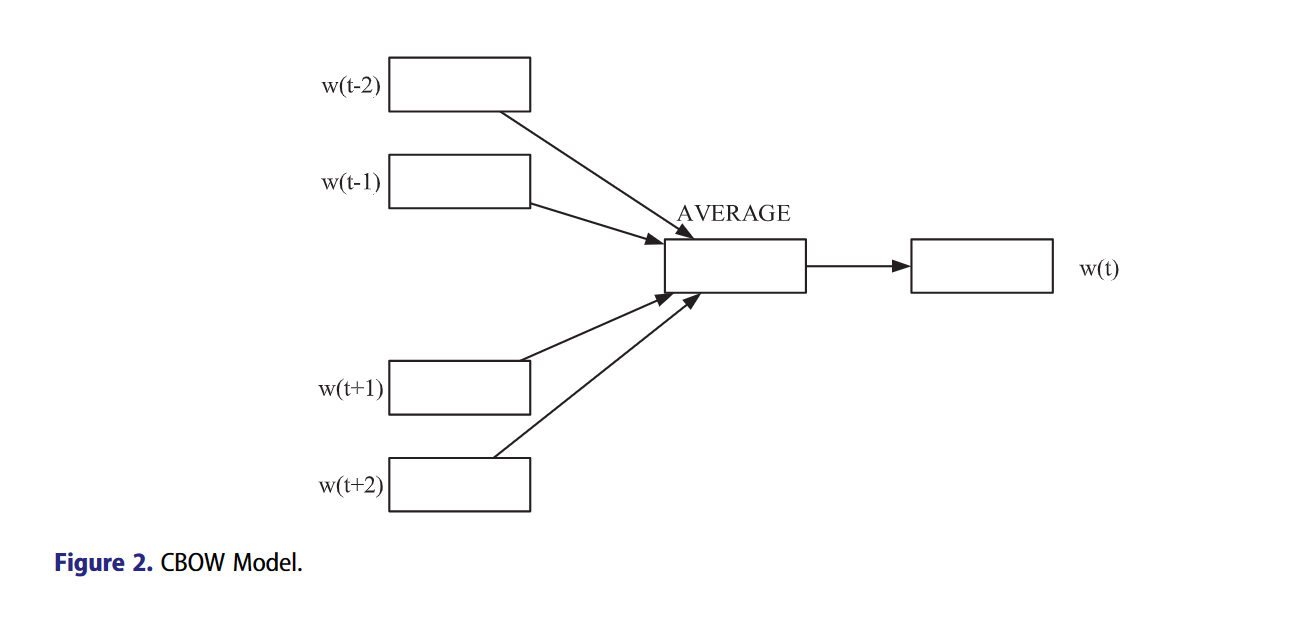
输入中心词上下距离c的单词向量,平均下来作为中心词的投影向量,CBOW在学习的过程就是让这个投影向量和它本身向量更相近,和相反意义的单词向量更远,也就是最小化以下损失函数:
\begin{equation} loss_{CBOW}=log\prod_{k=1}^{|D|}\{\sigma(v_k^T \theta^k)\prod_{j=1}^{|Neg_k|}[1-\sigma(v_k^T\theta^j)]\} \end{equation}
19.2.2. Integration of domain-general information with domain-specific information
第一步,用Wikipedia语料库训练CBOW模型,最开始单词向量是随机初始化的,接着CBOW用正确的学生答案的语料进行训练,这时单词的向量来源于第一步训练的结果
19.2.3. LSTM and classifier
这里貌似将输入向量经过LSTM之后,加上一个Softmax就直接预测了,但是我觉得这里肯定没有写完整,应该还是经过了一个线性层,输出维度为预测分数的类别数,然后用softmax来得到最终的预测结果
20. Multi-Relational Graph Transformer for Automatic Short Answer Grading
20.1. Introduction
大多数的ASAG方法使用序列文本来比较RA和SA,忽略了文本的结构性语境。于是作者提出了一种Multi-Relational Graph Transformer,MitiGaTe,在考虑结构化语境的情况下表示词元(词元的嵌入表示)。Abstract Meaning Representation(AMR) graph在解析文本回答后得出,然后被分离成多个subgraphs,每个对应AMR的一种特殊的关系。Graph Transformer用来表示每个词元的嵌入表示(在考虑关系的情况下),也就是需要利用AMR的subgraph,最终会得到一个subgraph representation。最终,比较RA和SA的subgraph representation,得到最终的分数。
本篇文章的主要贡献:
- 提出了一种Graph Transformer-based技巧来获取文本的结构信息
- 证明了词元的语义表示能提升模型效果
- MitiGate能为学生提供可解释的分数反馈
- 提升了Benchmarks的效果
20.2. Methodology
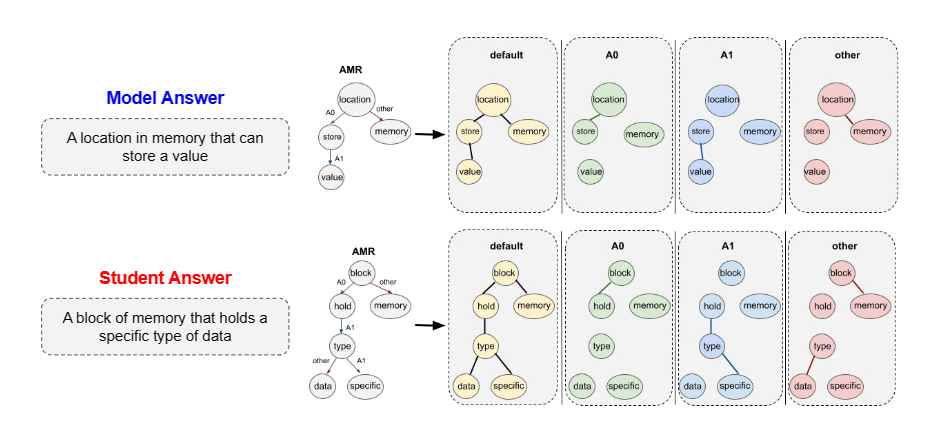
将ASAG任务作以下定义: $A^M= \lbrace w_1^M,w_2^M,.. \rbrace$和$A^S=\lbrace w_1^S,w_2^S,.. \rbrace$分别表示model answer和student answer,text-matching model $f(A^M,A^S)$的作用是计算SA和RA的语义相似度。作者提出了一种graph-based matching model,用来根据输入语句创造graph,首先需要解析每个句段成AMR图,接着从AMR图中准备好subgraphs,接着就可以从每个subgraph创造relation-specific token representation$h_{w,r}$,然后聚合成最终的subgraph representation $g^\phi_{r,M}$和$g^\phi_{r,S}$,比较两者得到最终分数。AMR大体结构图如下所示:
20.2.1. AMR parsing
文本的含义用根指向的图来表示,节点表示概念,边表示概念的关系,比如主语和宾语的关系。AMR捕获有意义的内容,获得抽象的表示。AMR的效果和之前的dependency parser差不多。作者直接使用了AMR model的API来创建每个Answer的AMR graph。
20.2.2. Subgraph Preparation Layer
根绝边的类别数量来生成subgraph,所有subgraph和原始的graph有相同数量的节点,但是只有这个类别的边被保留。AMR大概有100种不同的relation来捕获语义,如果全部用上会低效率的,作者只保留了ARG1和ARG0,其他全部被划分为other。那么原始的graph会被分成以下部分:
\begin{equation} G_{sub}=\lbrace default, A_0, A_1, other \rbrace \end{equation}
20.2.3. Preparing Node and Subgraph Representation
模型整体架构图如下所示:
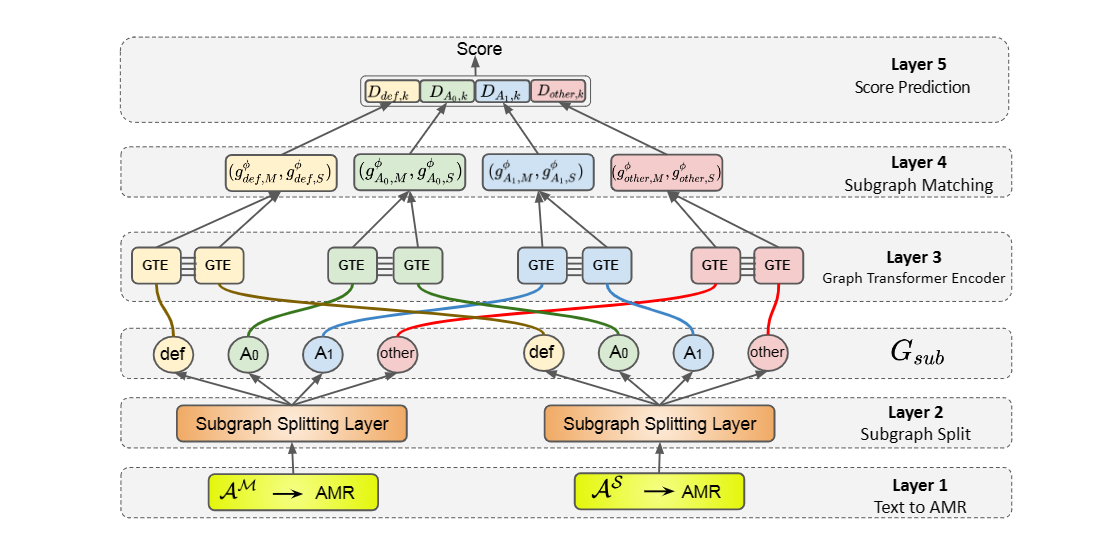
这一步的主要作用是表示之前得到的subgraph。分为两步: 第一步是用Graph Transformer来生成node,接着聚合所有node。
- 生成node representation的网络是Graph Transformer,其实就是针对节点序列的Transformer,从subgraph输入节点序列$x=(x_1,…,x_n)$,每个节点看成token输入Transformer,与一般的Transformer的区别有两点,一个是只计算该节点相邻节点(包括自身)的注意力权重,第二点是注意力函数有区别,会乘以关系的向量表示$e_{ij}^l$,作者拿最后一层的节点表示$h_{w,r}$来表示特定节点特定关系的表示
- 接着对这些node进行相加,得到的结果$g^\phi_{r}$就是这个关系的subgraph representation
\begin{equation} g^\phi_{r,M}=\frac{\sum_{w\in A_M}h_{w,r}}{\|A_M\|}, \forall r\in G_{sub} \end{equation}
20.2.4. Graph Matching Layer
在获得subgraph representation后,我们就相当于得到了文本的句法信息和语义信息,接着就可以比较RA和SA的距离了:
\begin{equation} \begin{aligned} & D_{r,k}=cosine(w_k^{cos}\odot g^\phi_{r,M},w_k^{cos} \odot g^\phi_{r,S}) \\ & D = [D,D_{r,k}] \end{aligned} \end{equation}
k表示不同方面,$w_k^{cos}$是一个参数向量,负责给不同的方面赋予不同的权重,得到的k个$D_{r,k}$向量concatenate成D
20.2.5. Prediction layer
用全连接层作为分数预测层
20.3. Experiment setup
20.3.1. Dataset
使用了Mohler数据集,视为回归任务
20.3.2. Data Processing
在AMR环节,利用GloVe对单词进行embedding
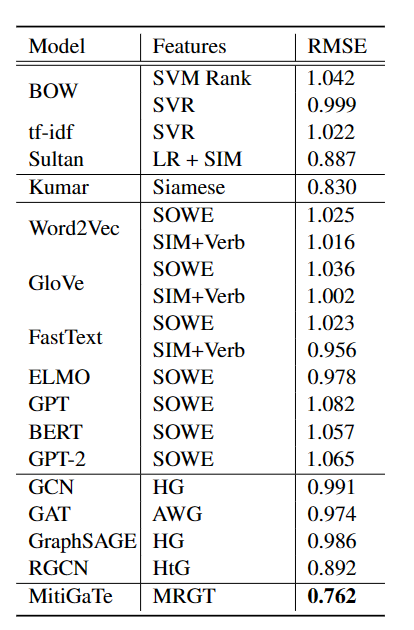
20.4. 实验
实验结果:
feedback可以看下图这个例子:
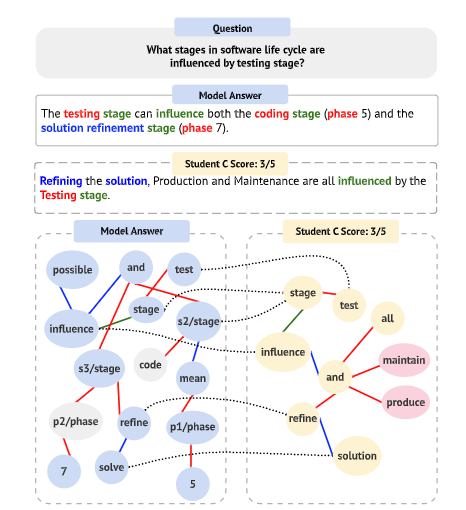
其中灰色的节点表示学生答案种遗漏的部分,粉色节点表示学生答案中多余的部分
21. Automatic Short Answer Grading (ASAG) using Attention-Based Deep Learning MODEL
21.1. Introduction
用BERT来解决ASAG任务
21.2. Method
作者将任务步骤分为了三步: 数据准备,数据预处理,评分
21.2.1. Dataset preparation
使用sQuad2.0数据集,数据集包含了10w+的数据
21.2.2. Data preprocessing
用BERT-uncased tokenizer来词元化文本
21.2.3. BERT grading
用BERT来encode学生答案和参考答案的<cls>词元,然后输入到分类器中进行分类
21.2.4. Evaluation metrics
kappa系数和混淆矩阵的性能度量,比如召回,精准率等等
22. Automated Short Answer Grading Using Deep Learning: A Survey
22.1. Introduction
一篇综述,ASAG任务的处理方法可以分为两大类,一类是基于handcrafted features,另一类是基于深度学习的方法。这篇综述整理了ASAG领域的深度学习方法。ASAG解决方法的发展历程:

这篇综述主要回答了以下四个问题:
- ASAG领域的数据集
- 评价指标
- 有哪些深度学习的方法用到了
- 结果如何
22.2. Corpora
综述整理了共六个ASAG领域的数据集,其中像ASAP,SemEval-2013和Beetle,ScientsBank都是竞赛的数据集:
- ASAP: 来源于Kaggle,共有10686个回答,每个回答都来源于短文,每篇短文大概150词到550词
- Beetle and ScientsBank: Bettle和SciEntsBank都来源于SRA(student response analysis),都是SemEval-2013的数据集
- Texas
- Cairo
- Powergrading
- Statistics
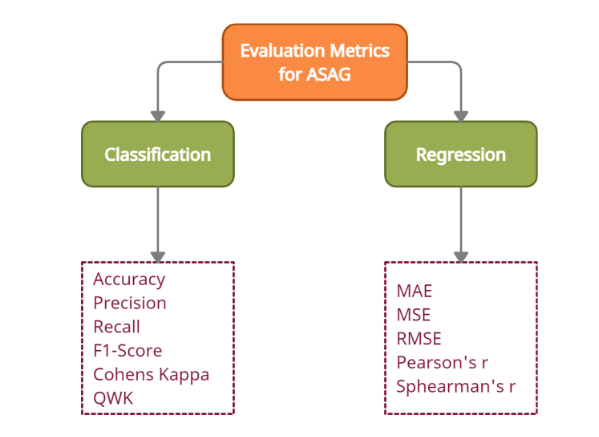
22.3. Evaluation Metrics
根据ASAG任务是分类任务还是回归任务而不同:
kappa系数是一种衡量分类精度的指标,kappa系数的计算基于混淆矩阵,计算公式如下:
\begin{equation} k=\frac{p_0-p_e}{1-p_e} \end{equation}
其中$p_0$是分类正确的样本数除以总样本数,$p_e$的计算公式为:
\begin{equation} p_e=\frac{a_1*b_1+a_2*b_2+..+a_c*b_c}{n*n} \end{equation}
其中每一类真实样本个数分别为$a_1,a_2,…$,而预测出来的每一个类样本的个数分别为$b_1,b_2,…$,总样本数为n,kappa的计算结果为-1到1,但通常kappa落在0-1之间,越高代表分类精度越高
QWK就是quadratic weighted kappa,二次加权kappa,在多级分类的深度学习评价中经常使用,就是加权的kappa
22.4. Deeplearning Approaches
主要用到的深度学习的方法分为了三大类,一类是基于LSTM及其变种,一种是基于Attention机制,最后一类就是Transformer-based,后续将逐个介绍,首先看一张近年来应用于ASAG的深度学习重要的文章:
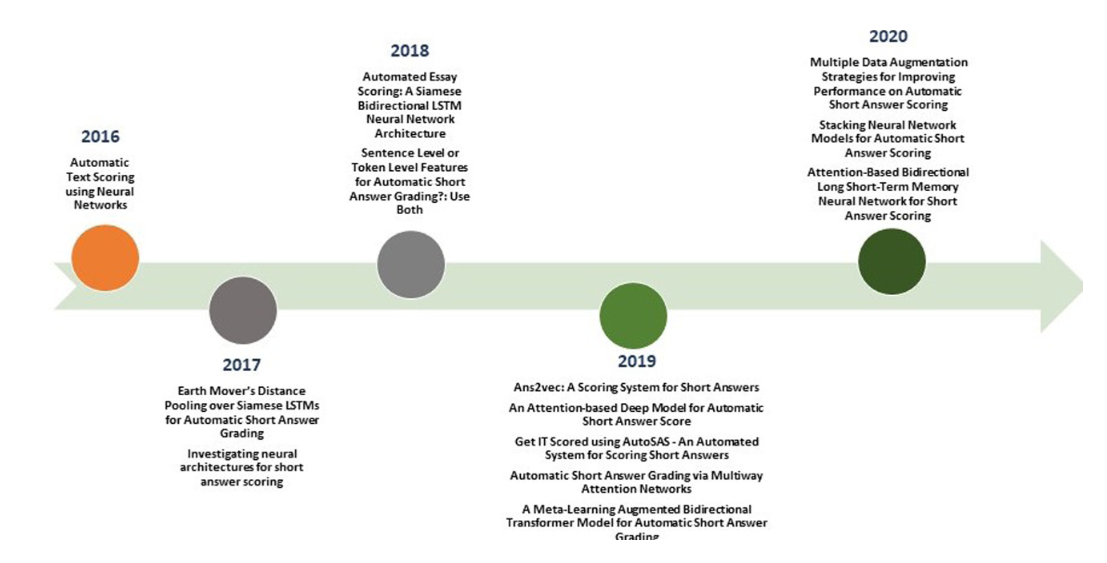
基于深度学习的方法及其性能:
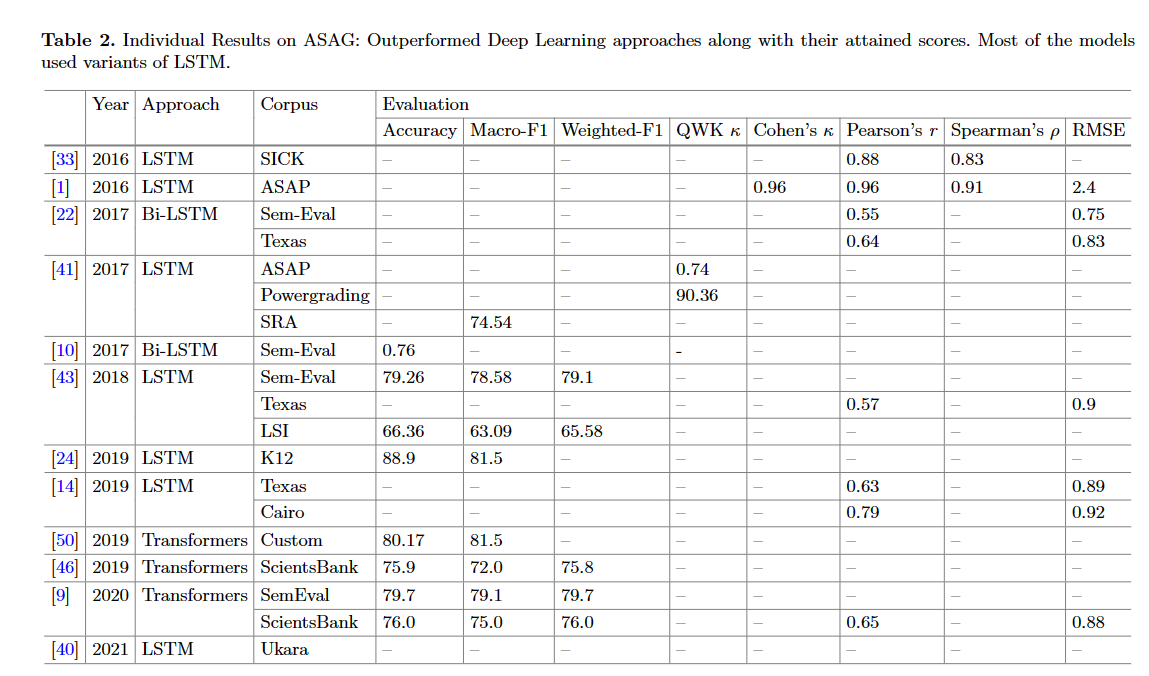
- LSTM: Siamese Bi-LSTM, Bi-LSTM
- Attention
- Transformer
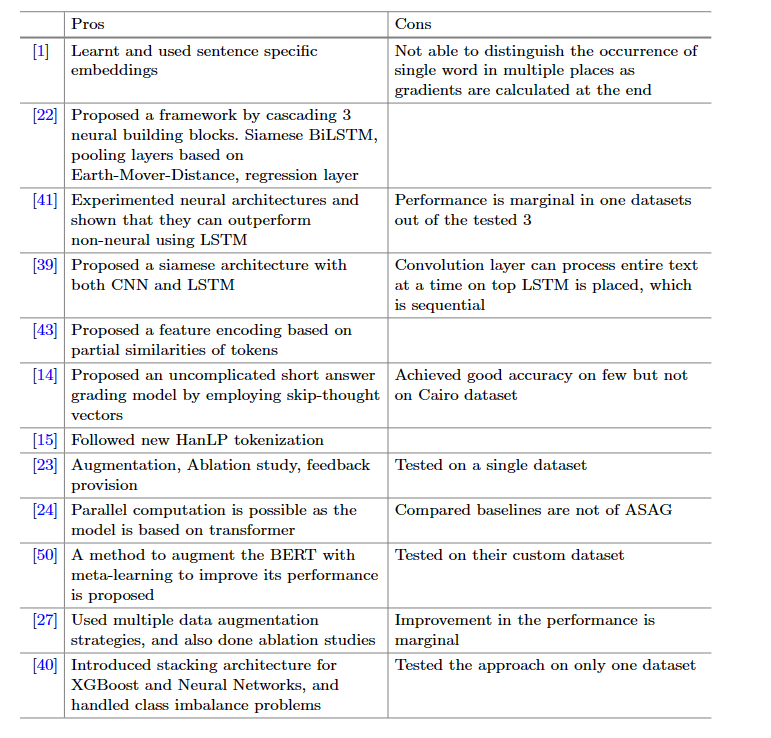
下表展示了作者收集的文章的模型及其效果和缺陷:
22.5. Conclusion
总的来说,用深度学习的方法往往相较于传统的特征工程的方法要省时且效果更好。这些方法中,涉及到注意力机制的模型往往表现更好。更多的Transformer方法被提出,比如BERT,XLNet,T5等等,更多的tokenization的方法提出,比如BPE,Word-Piece Encoding和Sentence-Piece Encoding
23. Survey on Automated Short Answer Grading with Deep Learning: from Word Embeddings to Transformers
23.1. Introduction
一篇关于Deeplearning在ASAG领域的综述,作者首先介绍了hand-engineering features到表征学习的转化,然后介绍了深度学习方法,主要分为了三大类: word embedding,sequential models,attention-based methods
作者根据文本的表征方法将方法分为两类:
- hand-engineered features with classifiers,我称其为特征工程的方法,具体来说根据特征的不同分为: lexical, syntactic, semantic
- deep learning methods,端到端,具体来说分为了word embedding, sequential models, attention-based methods
23.2. Historical perspective
按照大概的时间发展来说,研究者们首先使用concept mapping(概念映射)的方法来比较学生答案和参考答案,随着information retrieval的发展,从学生答案提取出feature与参考答案进行直接的比较。这个阶段的方法并没有考虑语义信息,纯粹的考虑句段的分析,基于语法树。接着,利用大型词典WordNet,语义信息开始被考虑。
23.3. Benchmark data sets for short answer grading
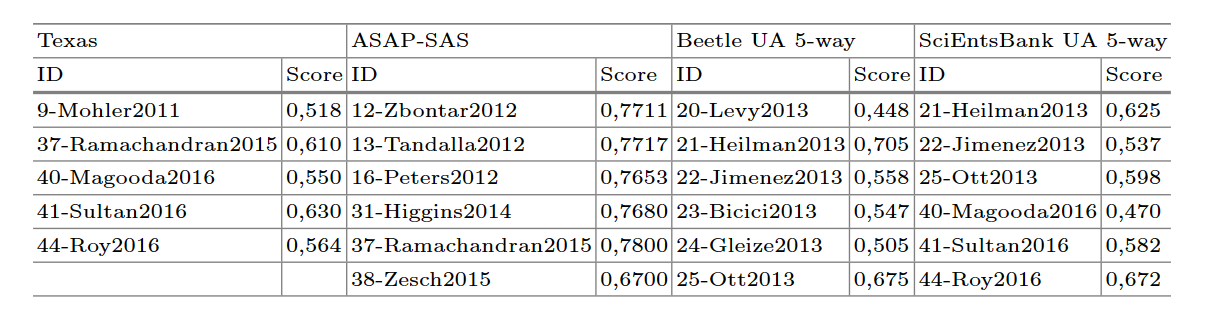
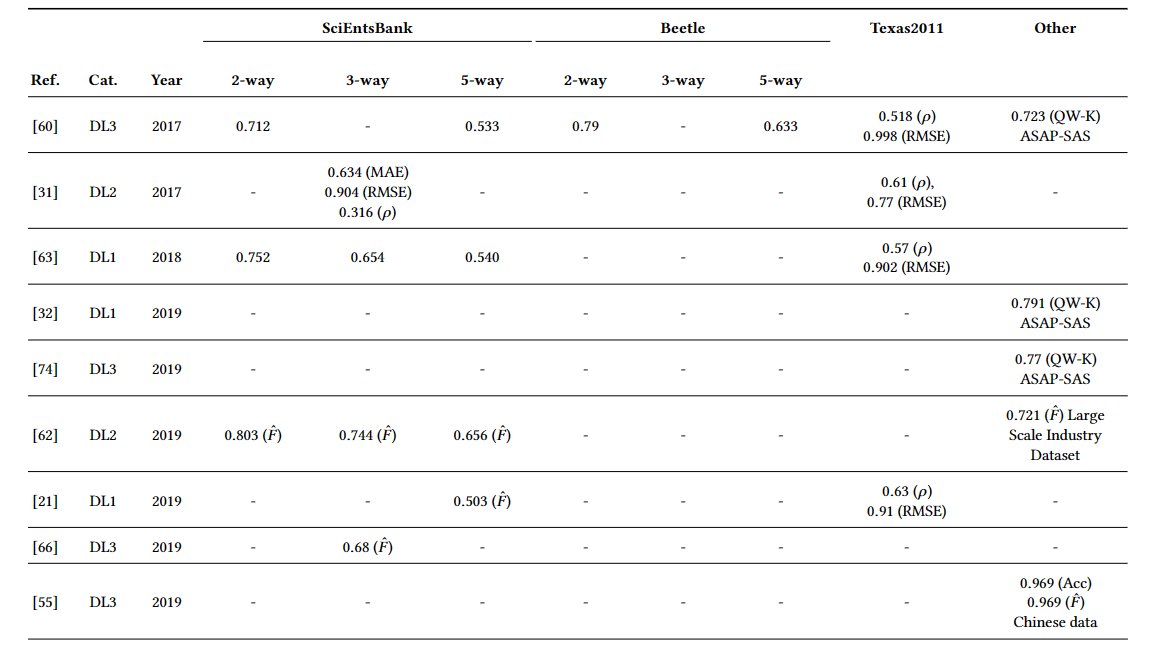
聚焦于这四个广泛使用的数据集: SciEntsBank, Beetle, Texas, ASAP-SAS,关于这四个数据集的总览信息如下表所示:
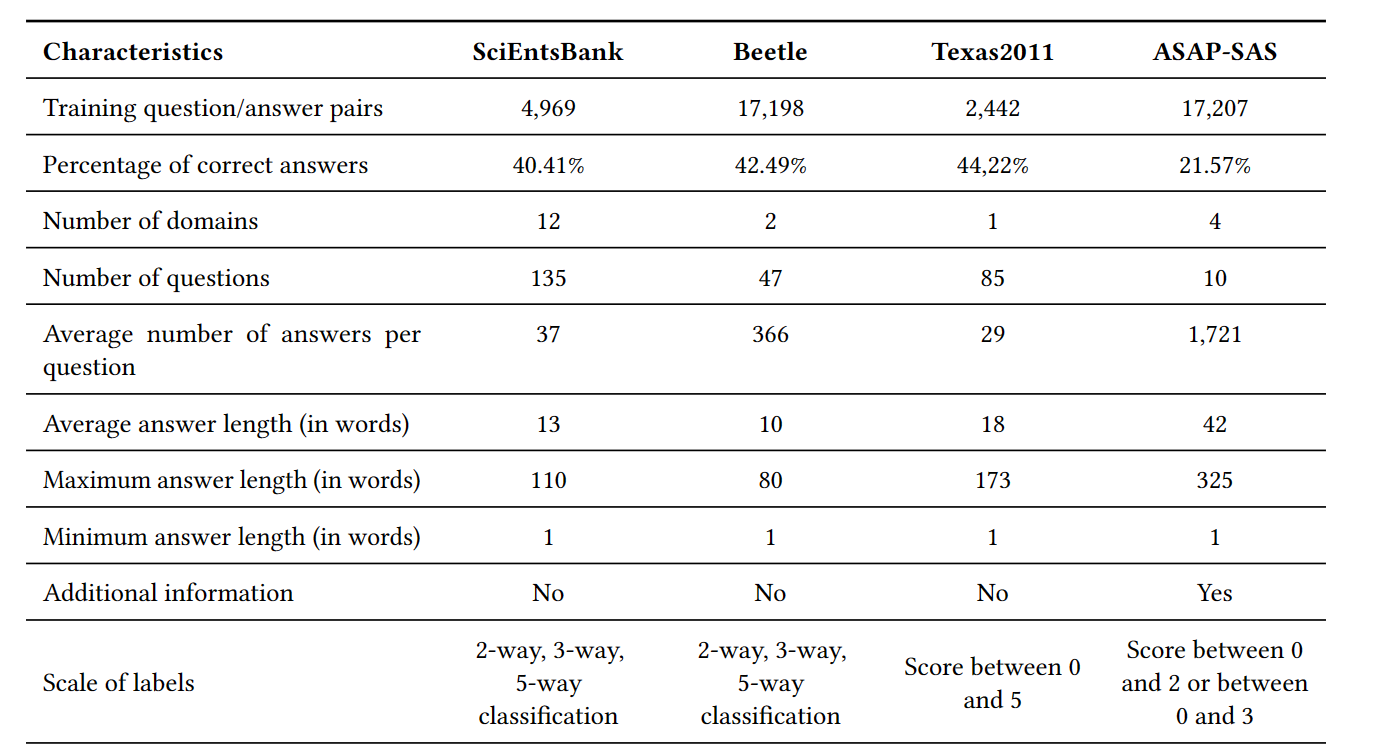
- SciEntsBank and Beetle: 都来源于SemEval 2013 challenge,总有三类的标签,分别是2分类(correct, incorrect),3分类(correct contradictory, incorrect)和5分类(non-domain, correct, partially correct incomplete. contradictory, irrelevant answer)。除此之外,数据集还有三个子集,分别代表评估系统可能遇到的情况,分别是unseen answers, unseen questions, unseen domains
- University of North Texas data set
- ASAP-SAS: 全称叫做Automated Student Assessment Prize Short Answer Scoring,来源于Kaggle competition in 2013
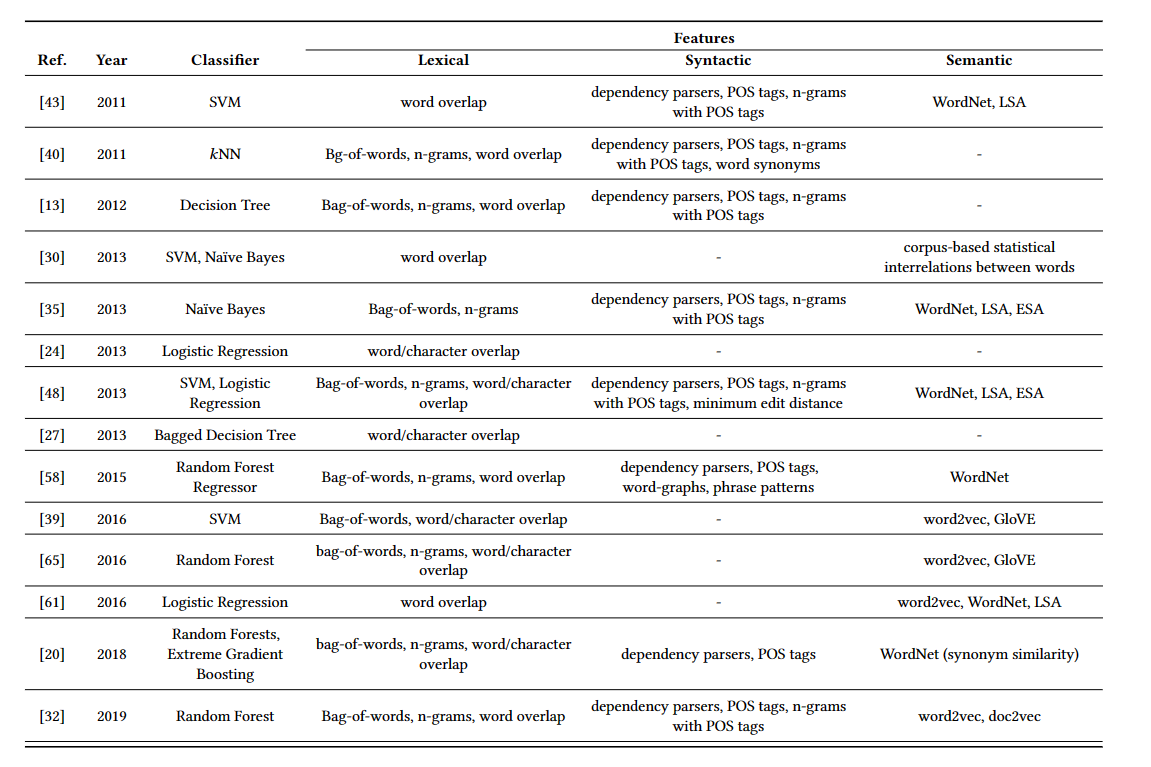
23.4. Hand-engineered Features and Machine Learning
特征工程的使用到的所有方法列于下表:
不同的方法在benchmark数据集取得的效果如下表所示:
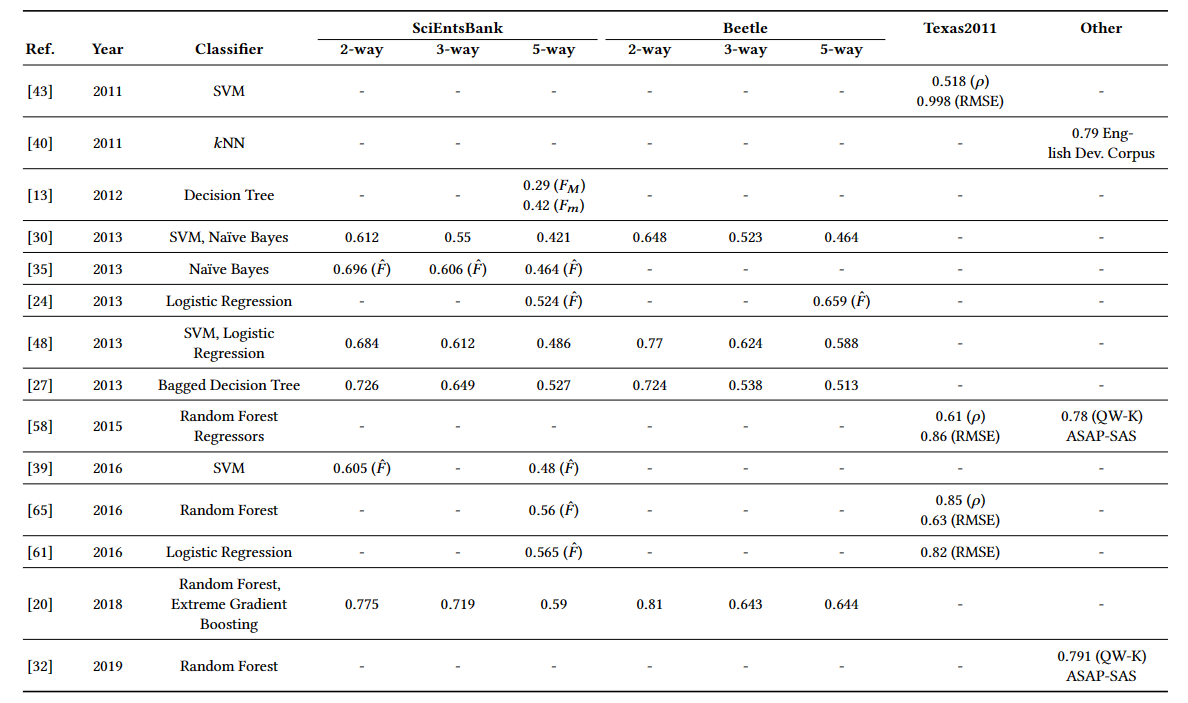
23.4.1. Lexical features
词汇特征,从单词的角度出发,早期用到的词汇特征有word-overlap,通过余弦计算方法得到的词重叠特征取得的效果最好。随着overlap技术的发展,也有像sentence overlap这样的方法出现。
23.4.2. Syntactic features
语法特征,常用的有语法树(parse tree)和词性标签(POS tags)
23.4.3. Semantic features
LSA,ESA和WordNet
23.5. Deep Learning Methods
这里作者将深度学习应用于ASAG的方法分为了三大类,分别是word embedding,sequential models和attention-based models。这和NLP和文本表征方法的进步相关,word embedding就是将单词和句段映射到隐空间中,能够捕获句段的语义信息,常见的有word2vec,glove等。sequential models,常见的有RNN和LSTM,能获得一段文本的序列信息,语义信息,重点是能获得长序列文本中各单词之间的关系。attention-based models同样能获得文本的序列信息和语义信息,通过注意力机制获得单词之间的关系。
下表展示了各模型用到的方法:
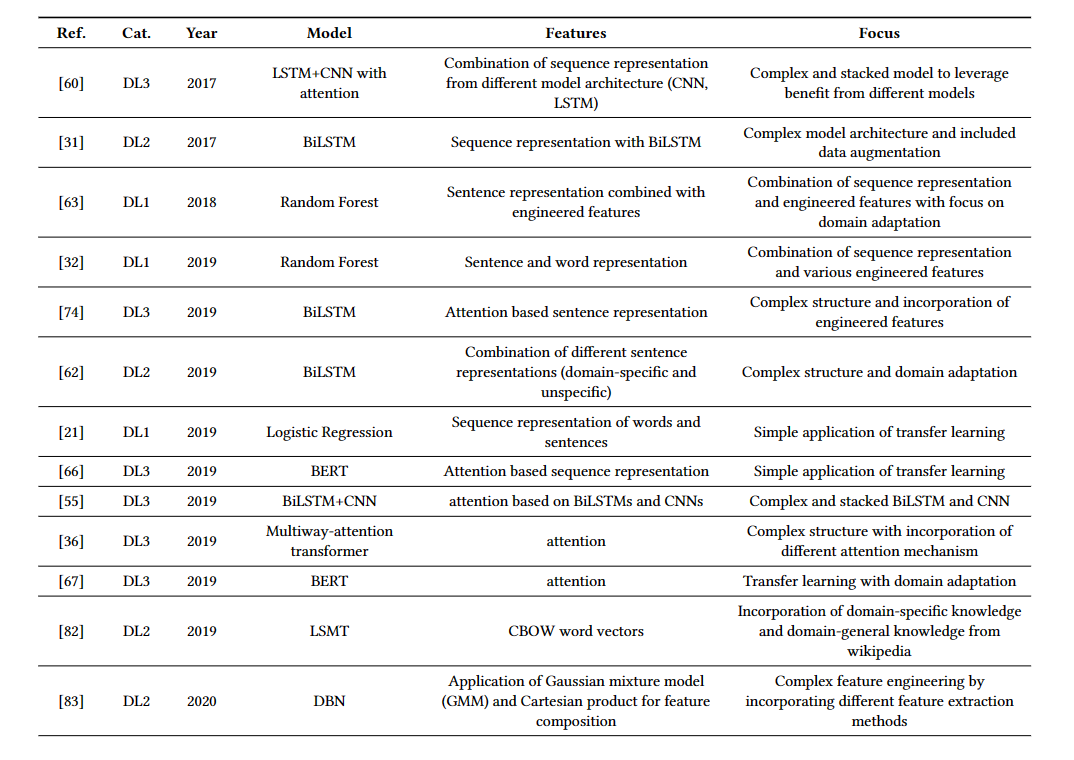
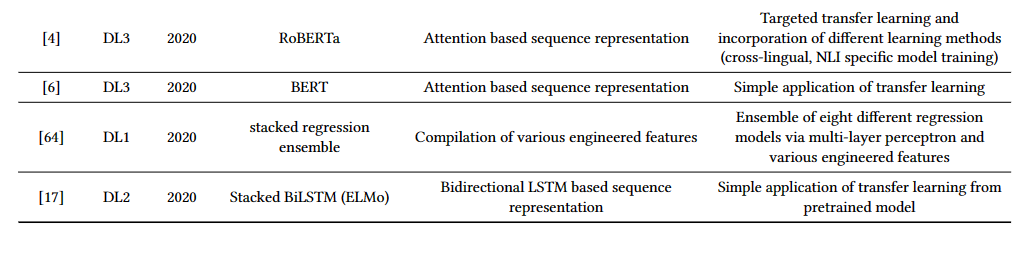
各模型的在benchmark数据集的表现:

23.6. Discussion
ASAG的methods发展的大趋势是从hand-engineered text features到deeplearning。一些适用于多种NLP任务的大模型并不能在这个下游任务上表现良好,这可能与ASAG任务本身的稀疏性和domain difference有关,稀疏性在自然语言处理领域有多种含义,比如data sparsity指的就是数据中存在多个零数据,远多于数据集中的非零数据,这里指的是ASAG的数据集非常sparse
attention-based model在NLP领域取得了很好的结果,但是在ASAG任务上,单一个finetuned transformer model并不能取得最好的效果,作者猜测它不能解开短文本中丰富的语义信息
23.7. Challenges
- semantic understanding: 现存的模型并不能有效地拟合短文本的语义信息,这与短文本本身的性质有关,短文本的信息用一种精简的方式蕴含在一段很短的文本中
- linguistic variations: 一个问题的回答词汇可能不止一种,回答问题的句子结构可能也不止一种,这给ASAG带来了很大的挑战,模型需要考虑不同的近义词汇或者不同的语法结构
- Details of questions and reference answers: 一般来说,参考答案相对来说简短,可能不包含足够的细节,除此之外,需要针对不同类型的问题和开放式问题进行评估
- Generalization across domains and answers: 字面意思
100. TODO
- 看GBT, GPT, ELMo
- 深入了解一下ASAG用特征工程解决的思路
- 想想改进方向
- 代码

Comments