1. Bert简介
BERT是GOOGLE团队于2018年提出的模型,在NLP领域里有着举足轻重的地位,BERT开创了NLP领域的预训练时代。BERT其实就是Transformer的编码器。BERT的双向性体现在MLM任务上,该任务可以让模型在得到全局的信息之后再去做预测
2. 相关工作
在BERT之前,将预训练的自然语言表示应用到下游任务有两种方法,一种是feature-based,代表模型就是ELMo,另一种是finetune,代表模型是GPT。这两种模型都是基于语言模型实现损失函数,也就是单向的,Bert提出了用掩码语言模型来做损失函数,这样既可以学到从左往右的信息,也可以学到从右往左的信息
3. 模型架构
模型主体架构就是Transformer的编码器
3.1. 输入表示
由于BERT预训练的数据集很大,所以BERT的采用WordPiece的方法来获得词元,WordPiece常见的方法有BPE,这样处理后有词表大小为30000。除此之外,BERT还有特殊的词元<cls>和<sep>,分别表示序列的整体信息和序列对的信息,嵌入层:
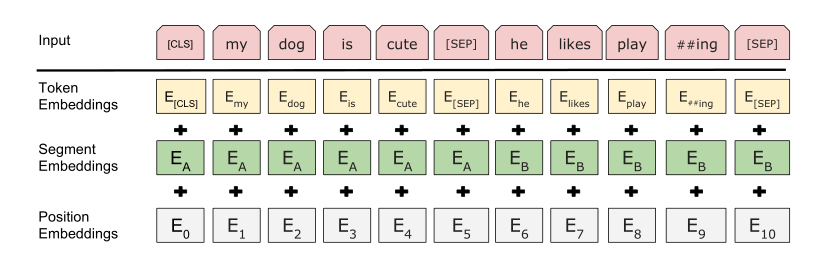
Segment Embedding就是句段的信息,如果有两个句子,那么输入为0或者1
3.2. 预训练的Task
预训练任务有两个,掩码语言模型(MLM)和下一句预测(NSP),MLM主要为了学习词元级别的信息,NSP为了学习序列对的信息,主要为了服务QA等任务。掩码语言模型就是随机替换或者掩蔽某一词元,具体来说,选择15%的词元来做掩蔽,10%的几率不替换,10%的几率替换成随机词元,80%的几率替换成[Mask]词元。
4. 预训练数据集和实验
预训练数据集为: BooksCorpus和English Wikipedia
做了很多很多实验,刷了很多榜,GLUE,SQuAD,SWAG,针对不同的问题,需要给模型加上输出层做微调,其中很多任务都使用特殊字符<cls>来做预测
Bert-Base有110M参数,Bert-Large有340M个参数
read more
Comments