目录
RACE
简介
RACE数据集包含了中国初高中阅读理解题目,最初发布在2017年,一共含有28k短文和100k个问题,最开始发布的目的是为了阅读理解任务。它的特点是包含了很多需要推理的问题。
RACE数据集格式
Each passage is a JSON file. The JSON file contains following fields:
- article: A string, which is the passage. 文章
- questions: A string list. Each string is a query. We have two types of questions. First one is an interrogative sentence. Another one has a placeholder, which is represented by _. 四个问题题干
- options: A list of the options list. Each options list contains 4 strings, which are the candidate option. 四个题目的四个选项
- answers: A list contains the golden label of each query.四个题目的正确答案
- id: Each passage has a unique id in this dataset.
RACE数据集分布

RACE-M表示初中题目,RACE-H表示高中题目
RACE数据集中的长度
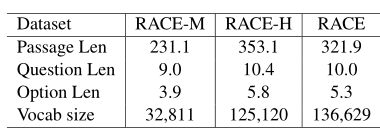
RACE数据集中的问题的统计信息
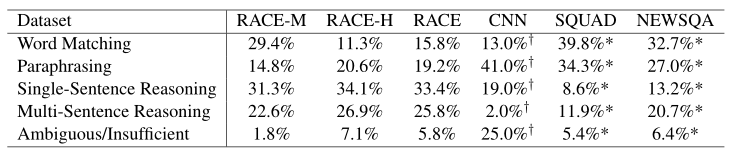
GaoRACE
Gao他们对于RACE数据集的处理
- 去掉了那些误导选项和文章语义不相关的数据
- 去掉了那些需要
world knowledge生成的选项
- githuburl,上面有预处理RACE数据集的代码
Gao处理后的RACE数据集统计信息
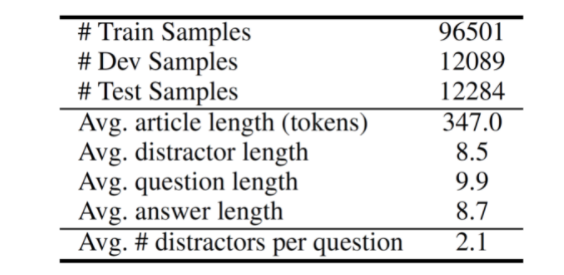
Gao处理后的数据集格式
预处理
首先把数据集规整到一个json文件里,分为dev,test,train三个json文件。
每一行包含以下信息:
article, sent(sentence), question(问题有两种,一种是疑问句,一种是填空), answer_text, answer, id, word_overlap_score, word_overlap_count, article_id, question_id, distractor_id.
那么一个问题会有2-3个误导选项,一篇文章又会有3-4个问题。相比于原本的数据集多了word-overlap指标,word-overlap就是词重叠率,交集比上并集。
updated
updated数据集和original数据集格式类似,少了overlap,内容上去掉了一些语义不相关的题目。
预处理代码
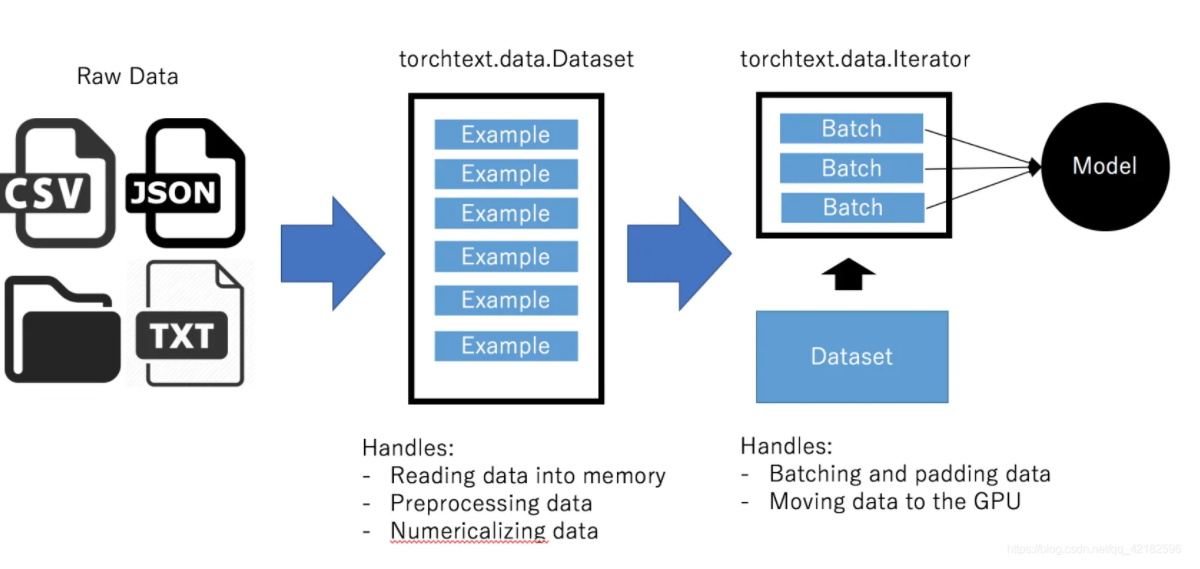
利用torchtext框架预处理文本,流程大概如下:
- 定义Field:声明如何处理数据 定义
- Dataset:得到数据集,此时数据集里每一个样本是一个 经过 Field声明的预处理 预处理后的 wordlist
- 建立vocab:在这一步建立词汇表,词向量(word embeddings)
- 构造迭代器:构造迭代器,用来分批次训练模型
Gao说有去掉一些语义不相关的误导选项,但是在代码中并没有看见这步操作??
MRC 阅读理解数据集
简介
发现了一篇很好的综述,里面涵盖了2021年之前用到的所有MRC数据集。现在对这篇综述简单介绍一下
Title
English Machine Reading Comprehension Datasets: A Survey
Abstract
文献收集了60个英语阅读理解数据集,分别从不同维度进行比较,包括size, vocabulary, data source, method of creation, human performance level, first question word。调研发现维基百科是最多的数据来源,同时也发现了缺少很多why,when,where问题。
Table 一张十分完整的表格
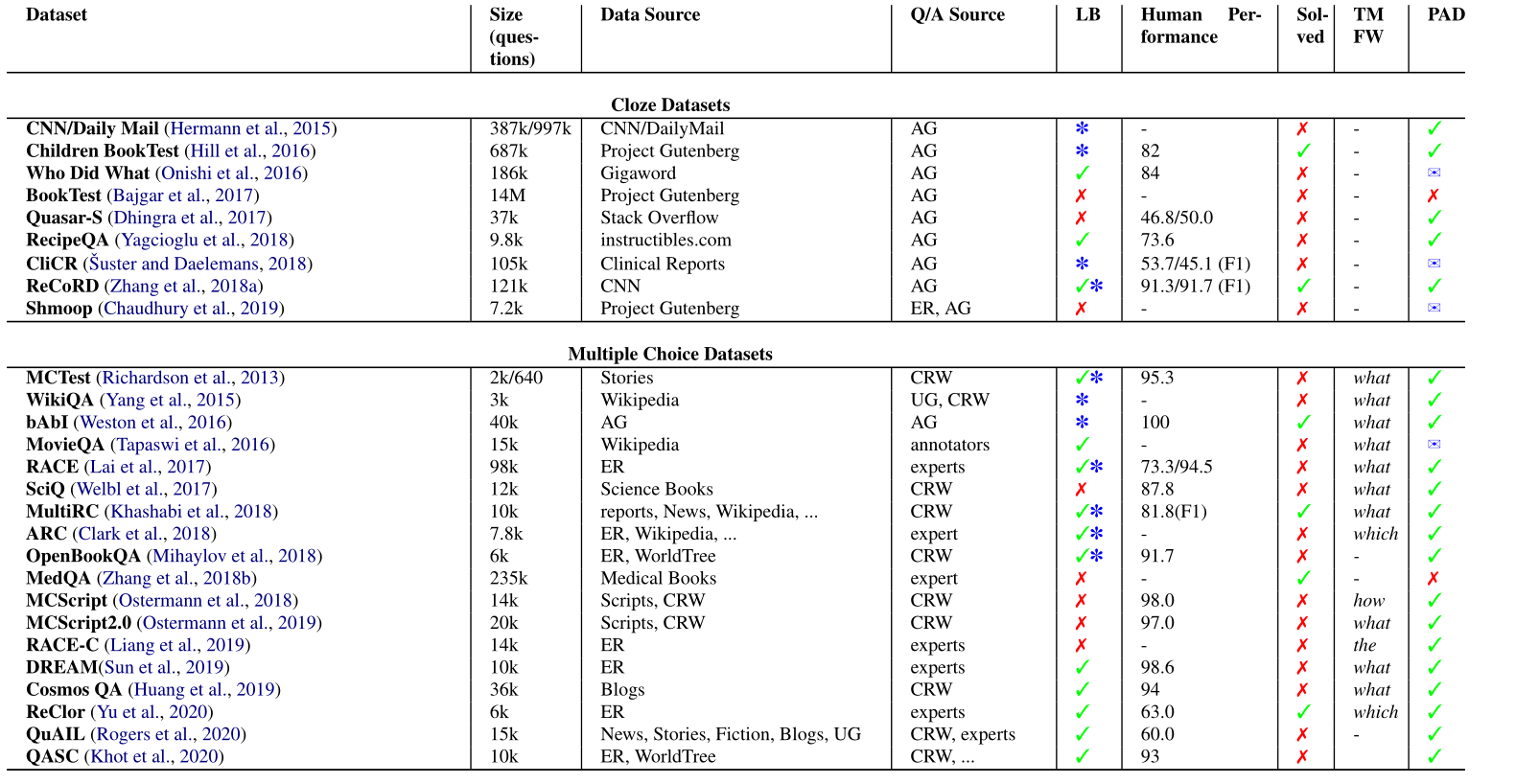
首先我简单解释以下这个表格,这个表格一个收录了18个Multiple Choice Datasets,也就是说这18个数据集都着眼于多选题。
- 第一列是数据集的名称。
- 第二列表示数据集中问题的个数(size)。
- 第三列表示数据集中文章的来源,其中ER表示education resource, AG表示automatically generated即自动生成,CRW表示crowdsourcing。
- 第四列表示答案的来源(answer),其中UG表示user generated。
- 第五列LB表示leader board available,即是否有排行榜,带*表示排行榜在网站上发布。
- 第六列表示人在该数据集上的表现。
- 第七列表示该数据集是否有被解决,也就是说是否有比较好的模型能在该数据集上表现良好。
- 第八列表示问题第一个单词出现最频繁的是哪个?比如what,how,which这样的单词。
- 第九列PAD表示是否开源。
值得关注的地方
这么多数据集中,来源于考试题目的有RACE,RACE-C,DREAM,ReClor,这些数据集的收集方法可以借鉴。
自制数据集
大型题库
泸江,星火英语…
方法
Python爬取网页

Comments