推荐系统
- 1. 推荐系统总览
- 2. 矩阵分解 Matrix Factorization
- 3. AutoRec
- 4. Personalized Ranking for Recommender System
- 5. Neural Collaborative Filtering for Personalized Ranking 使用协同过滤网络个性化排序
- 6. Sequence-Aware Recommender Systems
- 7. Feature-Rich Recommender Systems
- 8. Factorization Machines 因子分解机
- 9. Deep Factorization Machines 深度因子分解机DeeoFM
1. 推荐系统总览
1.1. 协同过滤 Collaborative Filtering
协同过滤最早出现在1992年Tapestry system,“人们相互协作,相互帮助,执行过滤程序,以处理大量的电子邮件和张贴到新闻组的信息。”现在协同过滤的概念更加广泛,从广义上讲,它是利用涉及多个用户、代理和数据源之间协作的技术来过滤信息或模式的过程。
协同过滤模型可以分为:1.memory-based CF; 2.model-based CF. 其中Memory-based CF又可以分为item-based和user-based CF。model-based CF有矩阵分解模型。
总的来说,协同过滤就是利用用户-物品的数据来预测和推荐。
1.2. 显式反馈和隐式反馈
为了学习用户的偏好,系统需要收集用户的反馈feedback。反馈可以分为显式和隐式。
显式反馈就是需要用户主动提供兴趣偏好。比如点赞、点踩。
隐式反馈则是间接反映用户的喜好,比如购物历史记录,浏览记录,观看记录甚至是鼠标移动。
1.3. 推荐任务
电影推荐、新闻推荐、评分预测rating prediction task、top-n reommendation。如果使用了时间戳信息,那么我们构建了sequence-aware recommendation。针对新用户推荐新物品称为cold-start recommendation冷启动推荐。
2. 矩阵分解 Matrix Factorization
The Matrix Factorization Model矩阵分解模型
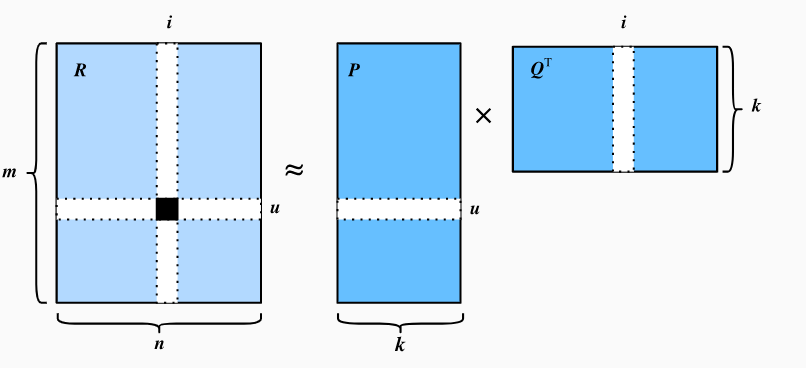
R是user-item矩阵,行数是用户数量,列数是物品数量,那么R∈Rmxn。P是user latent matrix,P∈Rmxk,Q是item latent matrix,Q∈Rnxk
矩阵分解就是把R分解成P和Q,那么预测的评分就是:
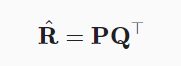
但是上面这个式子没有考虑偏置,我们会有下面这个完整的式子:
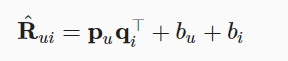
那么目标函数可以定义为:
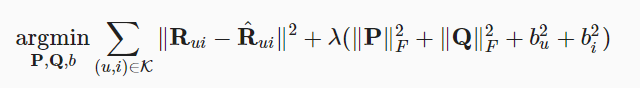
右边那一串是正则项,为了避免过拟合
下面这张图值观的展示了矩阵分解过程:
3. AutoRec
3.1. overview
使用autoencoder预测评分,上小节介绍的矩阵分解模型是线性模型,它不能捕捉复杂的非线性关系,比如用户的偏好。这一小节介绍一个非线性协同过滤神经网络模型AutoRec。
AutoRec是基于自编码器的结构,自编码器是一种特殊的神经网络架构,他的输入和输出的架构是相同的,自编码器通过无监督学习来训练获取输入数据在较低维度的表达,在神经网络的后段,这些低纬度的信息再次被重构回高维的数据表达。
所以AutoRec的架构也是输入层,隐藏层和重构输出层。它的目的是输入一个只有部分兴趣矩阵,输出一个完整的兴趣矩阵。
AutoRec可以分为user-based 和 item-based
3.2. formula
针对item-based:
$R_{*i}$表示兴趣矩阵的第i列,不知道的项填为0。那么神经网络的构架可以定义为:
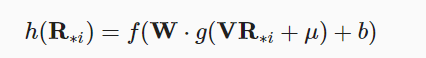
h()表示最终的输出,输出一个完整的兴趣矩阵,那么误差定义为:
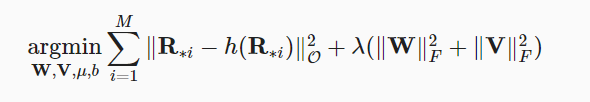
4. Personalized Ranking for Recommender System
4.1. overview
在上一节中,我们用到了显式反馈,同时模型只在能观察到的评分上训练。那么这种模型有两个缺点:第一个是很多的反馈并不是显式的。第二个是没有观察到的评分被完全忽略了。
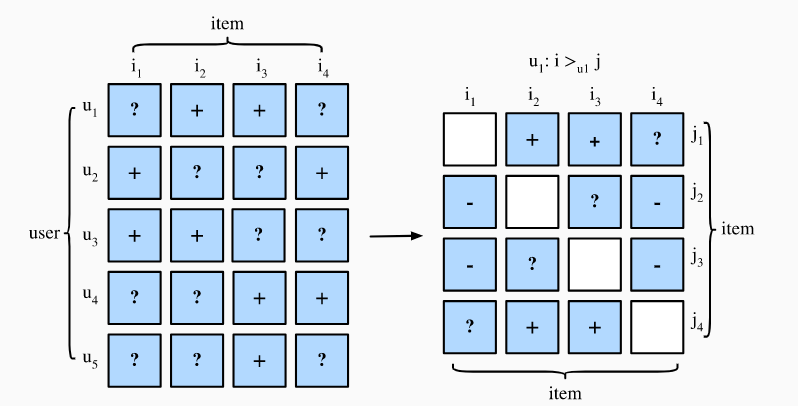
个性化推荐可以分为:1.pointwise;2.pairwise;3.listwise。Pointwise表示每次预测单个偏好,pairwise则是预测出一系列的偏好然后进行排序,listwise则是预测所有的item并进行排序。
4.2. Bayesian Personalized Ranking loss 贝叶斯损失
-
贝叶斯损失是一种pairwise个性化推荐损失。它被广泛应用于多种推荐系统中。它假设用户相对于无观察项,更加喜欢positive item
-
训练集格式是(u, i, j)表示用户u喜欢i超过j,BPR希望最大化下面这个后验概率:
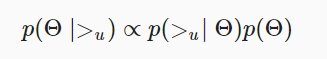
其中$\Theta$表示推荐系统的参数,$>_u$表示用户u对所有item的排序。
4.3. Hinge Loss
- 数学表达式
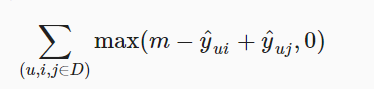
其中m表示安全系数,它的目的是让不喜欢的项离喜欢的项更远。它和贝叶斯都是为了优化positive sample和negative sample之间的距离。
5. Neural Collaborative Filtering for Personalized Ranking 使用协同过滤网络个性化排序
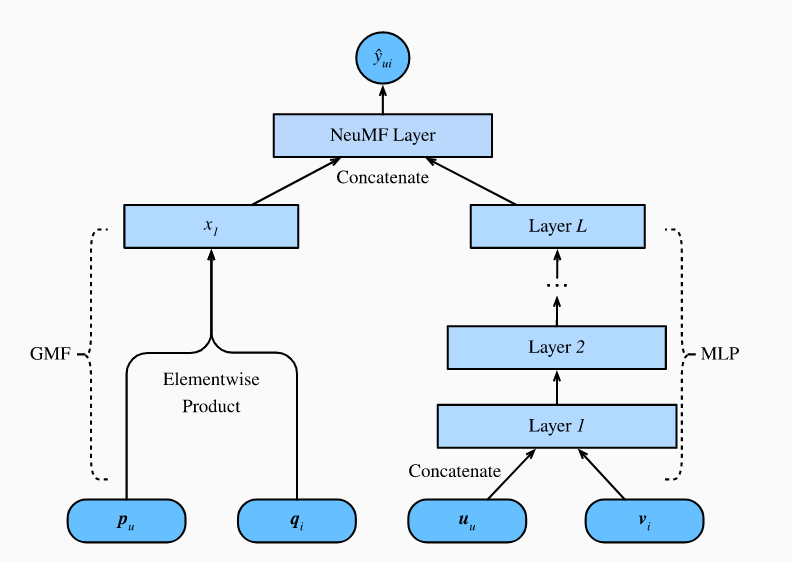
本小节重新将目光聚集到隐式反馈中,介绍协同过滤推荐系统NeuMF。NeuMF利用隐式反馈,它由两个子结构组成,分别是generalized matrix factorization(GMF)和MLP。不同于评分的预测如AutoRec,它将生成一系列的推荐,它根据用户是否看过这场电影来区分为正例和反例
5.1. The NeuMF model
NeuMF的网络结构由两部分组成。
- 一部分是GMF,也就是matrix factorization的类似形式,输入用户向量$p_u$和物品向量$q_i$,返回x
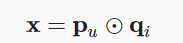
- 另一部分是MLP,输入和GMF一样,但是用不同的字母表示,具体公式如下:
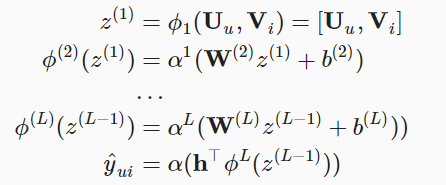
- 最后对这两个子结构concatenate一下,就是最终的输出
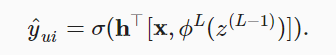
- 大体的网络结构如下
5.2. Evaluator
有两个性能度量指标
- hit rate at given cutting off l,记作Hit@l
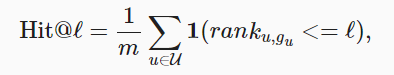
这个式子的主题思路是判断推荐的物品是否在top l中,m表示用户的数量,$rank_{u,g_u}$表示对于用户u和物品$g_u$的排名,1表示指标函数
- AUC,即ROC曲线下的面积,也是模型泛化能力的一个指标
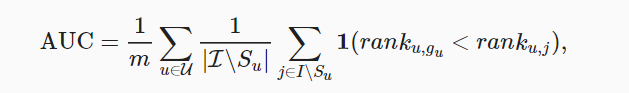
其中$S_u$表示模型对于u的推荐物品集,I表示item set,AUC越大越好
5.3. 代码
网络结构就是上面介绍的那样,net的输出是用户和物品匹配出的一个推荐值(我的想法)。在进行训练的时候,会给出正例物品(即用户有过评分的物品)和反例物品(用户没有评分,也就是没有看过)分别与用户得到一个推荐值,然后利用上一小节介绍的贝叶斯损失来优化(让评分过的物品有更高的推荐值),然后最终我们希望返回一系列的推荐物品,这些推荐物品都是没有负例物品,然后根据推荐值进行排序。性能指标是hit或者auc。hit的思想是让真实评分的物品在推荐列表中。
6. Sequence-Aware Recommender Systems
之前的模型都没有考虑时序信息,这小节的Caser模型将会考虑用户的时序信息。
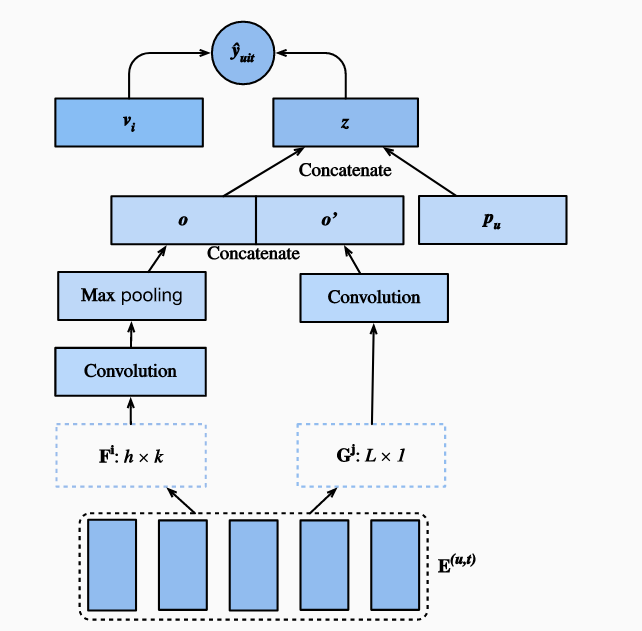
6.1. Model Architectures
模型的输入$E^{(u,t)}$表示用户u的近期L个评价的物品,Caser模型有横向和纵向的卷积层,输入矩阵分别与卷积层作用后,结果concatenate变成$z$,$z$再和用户的一般信息结合,也就是$z$和$p_u$concatenate最终输出$\hat{y}_{uit}$,其中$p_u$表示用户u的item信息
6.2. Negative Sampling 负采样
我们需要对数据集进行重新处理,比如一个人喜欢9部电影,同时我们的L=5,那么我们将最近的一部电影留出来作为test,其余的都作为训练集,可以划分出3个训练集。同时我们也需要进行负采样(采样没有评分的item)
7. Feature-Rich Recommender Systems
之前的模型大都用到了用户物品的交互矩阵,但是很少有用到一些额外的信息,比如物品的特征,用户的简介,发生交互的背景等等…利用这些信息可以获得用户的兴趣特征。本节提出了一个新的任务CTR(click-through rate),也就是点击率任务,对象可以是广告、电影等等。
8. Factorization Machines 因子分解机
Factorization machines(FM)是一个监督算法,可用于分类,回归和排名任务。它有两个优点:1.它能处理稀疏的数据;2.它能减少时间复杂度和线性复杂度
8.1. 2-Way Factorization Machines
$x$表示样本的特征值,而$y$表示它的标签值,即click/non-click。第二项表示线性项,第三项表示矩阵分解项
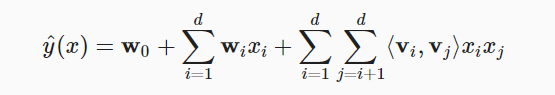
8.2. An Efficient Optimization Citerion
上面式子的第三项时间复杂度太高,我们可以简化一下
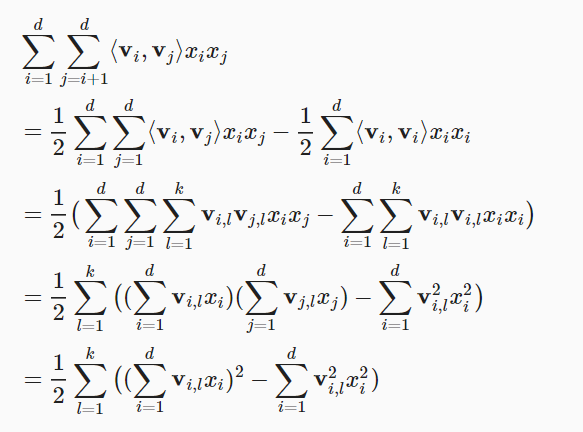
9. Deep Factorization Machines 深度因子分解机DeeoFM
上小节提到的因子分解机用到的都是线性模型(单线性和双线性),这种模型在真实数据表现并不好。这里我们就可以结合因子分解机和深度神经网络,比如我们这小节即将介绍的DeepFM。
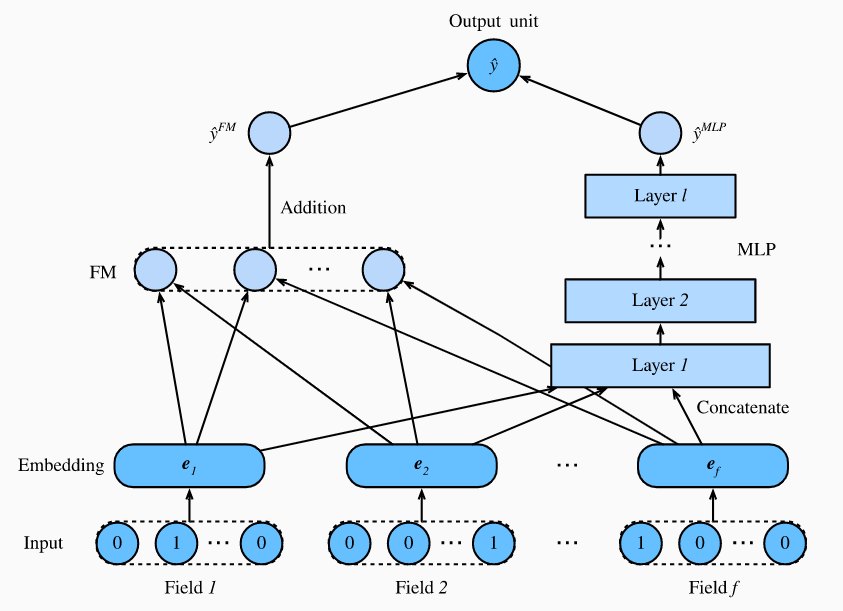
9.1. Model Architectures 模型架构
DeepFM由两部分组成,FM component和deep component,FM部分和上小节提到的2-way FM做法一样,主要是处理低纬度特征,而deep部分用到的MLP来处理高维度和非线性。这两部分使用相同的输入/嵌入层然后它们的结果整合成最终的预测。模型结构如下图:

Comments