T5模型
- 1. T5简介
- 2. 读论文
- 3. 个人总结
1. T5简介
T5的全称是text-to-text transfer transformer,是google于2019年推出的NLP领域的大型预训练模型,T5模型将NLP领域的任务均看成text to text类型,在众多任务的表现十分优异,模型本身的结构就是transformer的encoder-decoder结构,但是预训练目标以及其他细节有所区别
相关链接:
2. 读论文
摘要: 将所有的以文本为基础的语言任务变成text to text格式的任务,论文比较了不同的预训练目标、架构、无标签数据集、迁移方式在NLU任务上的表现。论文还新建了数据集C4,T5模型在很多benchmark上能做到SOTA,包括总结、QA、文本分类等。此外,T5模型和C4数据集均开源
2.1. Introduction
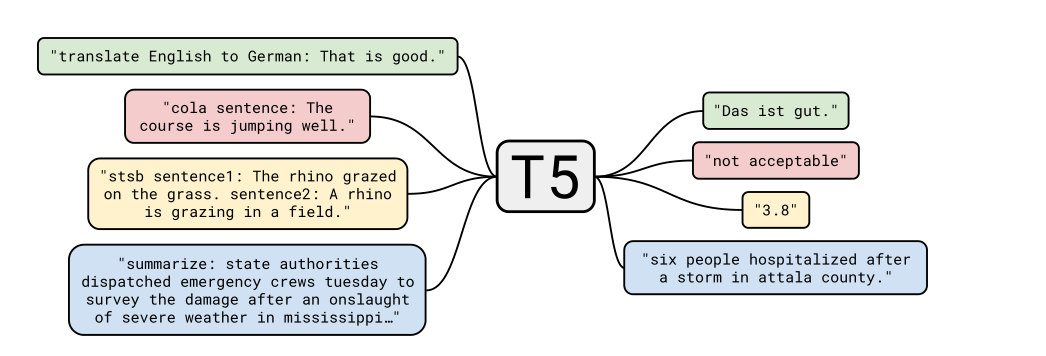
把所有的文本处理问题看成”text-to-text”问题,也即输入一段文本,输出一段文本。
2.2. Setup
2.2.1. Model
Transformer架构一开始用于机器翻译任务,自注意力可以看成将一段序列的每个词元替换成其他词元的加权平均。T5模型的架构和Transformer的encoder-decoder结构基本一致,区别在于T5模型去除了层归一偏差,将层归一化放在残差路径外,使用了一种不同的位置嵌入方案。
2.2.2. THE Colossai Clean Crawled Corpus(C4)
这一部分主要介绍了C4数据集的相关内容。Common Crawl是一个公开的数据集网站,它可以提供从网页爬取的文本,但是这些文本数据存在很多问题,论文提出了以下的几种方法来让数据集更clean:
- 只保留以终点符号(即句点,感叹号,问号或引号)结尾的行
- 丢弃少于五个句子的page,只保留超过3个单词的句子
- 删除任何包含有在List-of-Dirty网站中出现的单词的网页
- 删除包含Javascript的行
- 删除出现“lorem ipsum”短语的page
- 删除所有包含大括号的页面
- 对数据集进行重复数据删除,当连续的三句话重复出现时只保留一个
- 使用langdetect工具过滤掉非英文的页面
2.2.3. Downstream Tasks
T5模型为了测量总体的语言学习能力,在很多benchmark上测试性能,比如机器翻译、QA、摘要总结、文本分类。在GLUE和SuperGLUE上测试文本分类能力,在CNN/Daily Mail上测试摘要总结能力,在SQuAD上测试QA能力…
2.2.4. Input and Output Format
正如在introduction中提及的一样,论文将所有的task看成text-to-text格式。这种框架为预训练和微调提供了一致的训练目标。模型用极大似然目标训练(教师强制)。为了区分不同任务,给input前加上task-specific前缀。比如为英翻德加上前缀“translate English to German: ”,论文附录里有各种任务的前缀与相关处理方法。
2.3. Experiments
论文搭建模型的出发点是比较不同的预训练目标、模型架构、无标签数据集等方面,从中选择表现最好的部分组成T5模型。每次只改变baseline的一部分,其余部分保持不变。BERT不太好做生成任务,比如机器翻译和摘要总结
2.3.1. Baseline
也即基准
2.3.1.1. Model
模型选用Transformer的Encoder-Decoder架构,相比于只使用Encoder来说,该架构在分类和生成任务上取得更好的效果
2.3.1.2. Training
所有的任务都是text-to-text类型,这让作者能用极大似然法和交叉熵损失来训练模型,优化器选择AdaFactor。在测试阶段,选用概率最高的词元作为输出。在预训练阶段,采用逆平方根学习率策略,即学习率会随着迭代周期下降。预训练阶段,模型迭代524288步。在微调阶段,模型迭代262144步,同时使用固定的学习率。
2.3.1.3. Vocabulary
由于模型任务包含了翻译任务,所以词表不仅包含了英语词汇,还包括德语、法语和罗马尼亚语词汇。词表是预定义的,所以模型输出不会出现超出词表的词汇
2.3.1.4. Unsupervised Objective
模型预训练过程需要无标签的数据。过往的预训练模型训练过程都采用masked language modeling(denosing objectives)作为预训练目标,大家发现这种处理方式能取得很好的结果。对于去噪目标,模型需要预测被遮掩的词元。借鉴于BERT的经验,模型随机采样并选择丢弃了15%的词元(作为masked),并且连续的掩蔽词元只被一个sentinel词元替代。下面展示了一个掩蔽的例子

2.3.1.5. Baseline Performance
展示了baseline模型在不同benchmark上的表现,不同的benchmark使用不同的指标

2.3.2. Architectures
比较不同框架在benchmark上的表现
2.3.2.1. Model Structures
作者选择了三种不同的架构进行对比,第一种架构是传统的Transformer的encoder-decoder架构,第二种是language modeling(encoder)架构,BERT用的就是这个架构,下一步的输出依赖于前一步的预测,第三种是Prefix Language Model,为text-to-text任务提供任务的前缀,比如翻译任务就是加上前缀translate English to German:
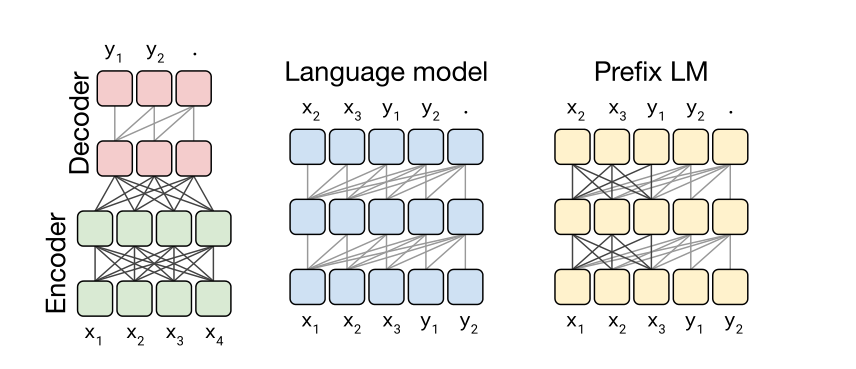
2.3.2.2. Comparing Different Model Structures
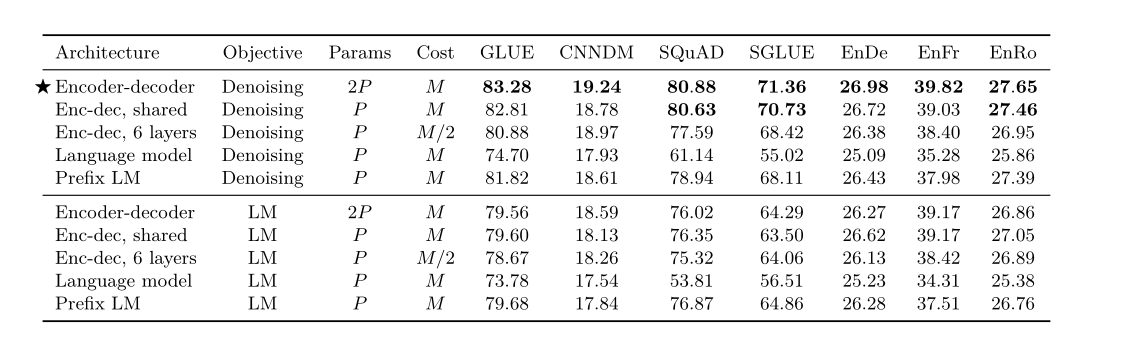
比较了不同模型的层数,参数和FLOPS
2.3.2.3. Objectives
除了架构的区别外,还比较了不同预训练目标带来的区别,比如使用Denosing Objectives时,LM架构需要把输入和输出连接起来进行连续的预测,使用LM目标时,LM架构需要从头预测到尾
2.3.2.4. Results
直接看表格,可以发现第一种encoder-decoder架构的表现最好
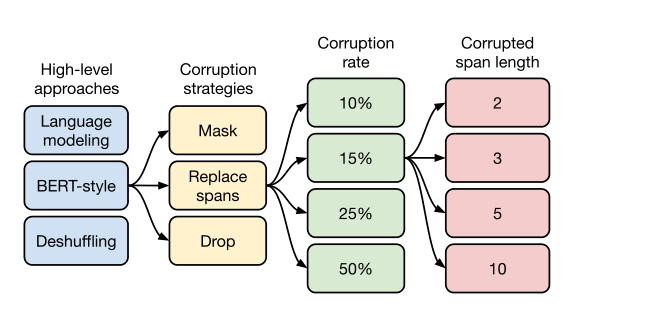
2.3.3. Unsupervised Objectives
本章从以下几个角度比较Unsupervised Objectives,实验得出结论,选取BERT-style,Corruption Strategies选择Replace spans,Corruption rate选择15%,Corrupted span length选择对每个词元都决定是否corrupted(独立),也即i.i.d.,这样得出的效果最好
2.3.4. Pre-training Data Set
最终选择了全size的C4数据集作为预训练数据集
2.3.5. Training Strategy
比较了微调的不同方案、比较了多任务同时训练和单任务训练的效果,最终发现baseline的效果最好,即预训练加下游任务微调
2.3.6. Scaling
尝试了扩大模型规模的几种方式,最后发现baseline选择的预训练规模是最合适的,使用较大的模型可能会使下游的微调和推断变得更加昂贵
2.3.7. Putting It All Together
这一部分介绍了模型最终的一些调整内容
- 预训练目标: 掩蔽片段平均长度为3,同时掩蔽比率为15%
- 更长的训练过程: C4数据集够大,让训练过程可以不用重复数据,因此增加批量大小、增加训练步数会更好
- 模型大小: 有好几个版本的T5模型,Base、Small、Large、3B and 11B
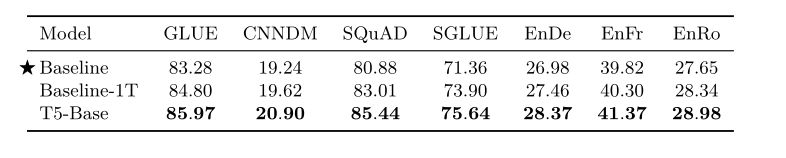
- 多任务预训练: 使用多任务预训练会为下游任务带来好处 展示一下最终的效果
2.4. Reflection
这一部分总结了模型的创新部分,同时提出了模型的缺点以及展望
3. 个人总结
T5模型是google继bert之后推出的一个大型预训练模型,先说说T5模型的特点,T5模型的架构是transformer的encoder-decoder架构,预训练数据集选用google自制的C4数据集,数据集也相当大,作者希望做出一个大统一的预训练模型,所以采用text-to-text任务类型也是它的一大特点,具体来说就是把所有的NLP任务变成输入一段文本,模型输出一段文本的形式,模型的预训练目标也很有特色,采用了类似bert的掩蔽预训练目标。论文做了很多很多很贵的实验,对比了很多方面,最后得到了这个模型,论文里的实验都说明的很详细,同时它也刷了很多榜,比如GLUE等,效果是比之前的预训练模型都好,是google财大气粗的表现。
模型在github上开源,在tensorflow上可以直接实现

Comments