1. ViT简介
ViT的全称是Vision Transformer,模型最大的特点就是把NLP领域的Transformer迁移到CV领域,模型在图像识别等多个CV任务上表现超越了卷积神经网络,相关链接:
2. Introduction
限制Transformer在CV领域发挥的一个要素就是序列长度的问题,如果把图像的每个像素点看成token,那么对于一张中分辨率的图片224*224而言,序列长度为50k,Bert模型处理的序列长度只有512,所以将Transformer应用到CV领域的一个难点就是序列长度过长。ViT于是提出了将图片分割成16*16的patch的做法,这样就可以大大减少序列的长度,不改变Transformer架构的情况下直接应用,取得了很好的结果,说明了transformer确实能在CV领域能取得很好的效果。
3. 模型
模型预览图:
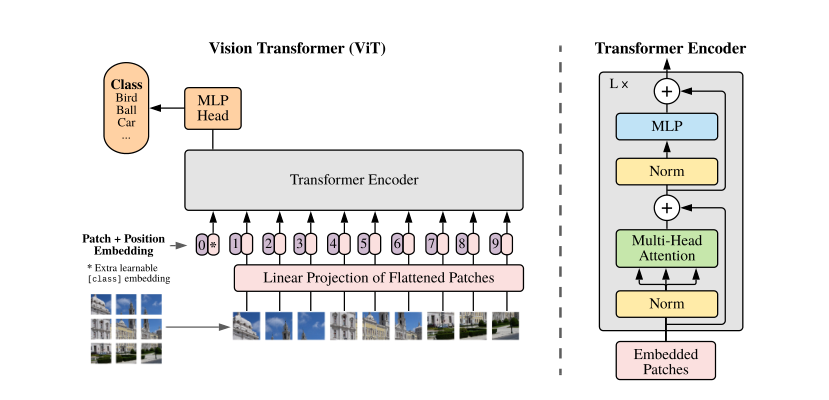
为了缩短序列的长度,作者将图片分为了很多个patch,patch的大小可以是16*16,每个patch的表示为每个像素点的灰度值排列,那么一张图片patch的形状为num_patchs*768,其中768=16*16*3。得到patch的表示后,输入线性投影层(就是一个线性层,形状可以是768*768)。为了和transformer保持一致,ViT也采用了位置编码和特殊编码<cls>的使用,位置编码采用的是1D位置编码,位置编码和特殊编码都可学习,patch的线性投影表示和位置编码是直接加在一起,这样便得到了图像的token,其余步骤和Bert类似,ViT的训练是有监督训练,用特殊编码<cls>来做预测
4.实验和数据集
数据集使用了ImageNet-1k、ImageNet-21k和Google自家的JFT数据集
和BERT一样,ViT也根据模型使用的参数和patch的大小不同,分为了以下几种:
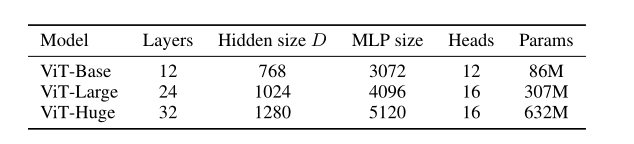
比如ViT-L/16代表Large ViT with patch size 16*16
实验结果
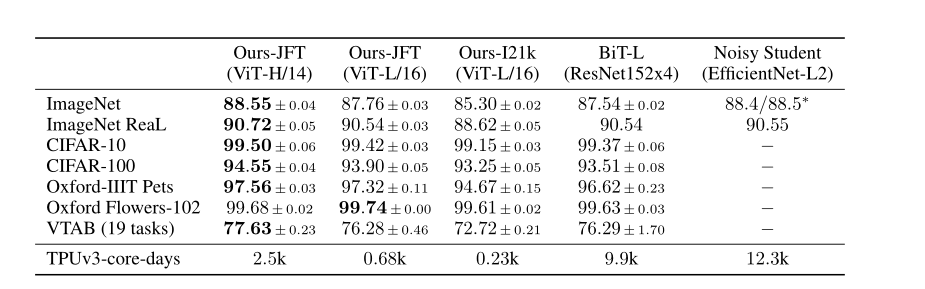
实验的metrics是预训练模型微调后的accuracy
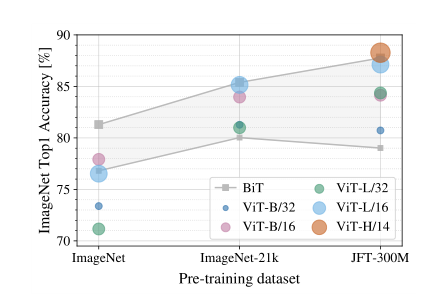
这张图表明ViT在数据集大的情况下会表现更好
read more
Comments