数据挖掘
- 总体情况
总体情况
- 书籍:Python数据挖掘入门与实践
- github_url:https://github.com/LinXueyuanStdio/PythonDataMining
- 配套代码和笔记,很适合迅速上手
- 这篇博客主要记录一些比较重要的算法
第一章 开始数据挖掘之旅
1.1 亲和性分析
- 亲和性分析根据样本个体(物体)之间的相似度,确定它们关系的亲疏。
- 例子:商品推荐。
- 我们要找出“如果顾客购买了商品X,那么他们可能愿意购买商品Y”这样的规则。简单粗暴的做法是,找出数据集中所有同时购买的两件商品。找出规则后,还需要判断其优劣,我们挑好的规则用。
- 规则的优劣有多种判断标准,常用的有支持度(support)和置信度(confidence)
- 支持度:数据集中规则应验的次数,统计起来很简单。有时候,还需要对支持度进行规范化,即再除以规则有效前提下的总数量。
- 置信度是衡量规则的准确性如何。
1.2 分类
- 根据特征分出类别
- 例子:Iris植物分类数据集,通过四个特征分出三个类别
- 特征连续值变成离散值
- OneR算法:它根据已有数据中,具有相同特征值的个体最可能属于哪个类别进行分类。比如对于某一个特征值来说,属于A的类别有80个,属于B的类别有20个,那么对于这个特征值来说,取值为1代表为A类别,错误率有20%。给出所有特征值,找出错误率最小的特征值作为判断标准。
第二章 用scikit-learn估计器分类
2.1 scikit-learn
scikit-learn里面已经封装好很多数据挖掘的算法
现介绍数据挖掘框架的搭建方法:
- 转换器(Transformer)用于数据预处理,数据转换
- 流水线(Pipeline)组合数据挖掘流程,方便再次使用(封装)
- 估计器(Estimator)用于分类,聚类,回归分析(各种算法对象)
- 所有的估计器都有下面2个函数
- fit() 训练
- 用法:estimator.fit(X_train, y_train),
- estimator = KNeighborsClassifier() 是scikit-learn算法对象
- X_train = dataset.data 是numpy数组
- y_train = dataset.target 是numpy数组
- predict() 预测
- 用法:estimator.predict(X_test)
- estimator = KNeighborsClassifier() 是scikit-learn算法对象
- X_test = dataset.data 是numpy数组
- fit() 训练
- 所有的估计器都有下面2个函数
2.2 邻近算法KNN
邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法。
例子:分类,Ionosphere数据集
第三章 用决策树预测获胜球队
3.1 决策树
例子:预测NBA球队获胜情况
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
scikit-learn库实现了分类回归树(Classification and Regression Trees,CART)算法并将其作为生成决策树的默认算法,它支持连续型特征和类别型特征。
3.2 随机森林
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
第四章 用亲和性分析方法推荐电影
4.1 亲和性分析
亲和性分析就是分析两个样本之间的疏密关系,常用的算法有Apriori,Apriori算法的一大特点是根据最小支持度生成频繁项集(frequent itemest),它只从数据集中频繁出现的商品中选取共同出现的商品组成频繁项集。其他亲和性分析算法有Eclat和频繁项集挖掘算法(FP-growth)。
4.2 Apriori算法
Apriori算法主要有两个阶段,第一个阶段是根据最小支持度生成频繁项集,第二个阶段是根据最小置信度选择规则,返回规则。
本章的例子是电影推荐。
第一个阶段,算法会先生成长度较小的项集,再将这个项集作为超集寻找长度较大的项集。
第二个阶段是从频繁项集中抽取关联规则。把其中几部电影作为前提,另一部电影作为结论。组成如下形式的规则:如果用户喜欢前提中的所有电影,那么他们也会喜欢结论中的电影。
第五章 用转换器抽取特征
5.1 抽取特征
抽取数据集的特征是重要的一步,在之前的学习中我们都获得了数据集的特征,但很多没有处理的文本特征并不是很明显,比如一段文本等等。特征值可以分为连续特征,序数特征,类别型特征。
5.2 特征选择
通常特征有很多,但我们只想选择其中一部分。选用干净的数据,选取更具描述性的特征。判断特征相关性:书中列举的例子是判断一个人的收入能不能超过五万,利用单变量卡方检验(或者皮尔逊相关系数)判断各个特征的相关性,然后给出了三个最好的特征,分别是年龄,资本收入和资本损失。
5.3 创建特征
主成分分析算法(Principal Component Analysis,PCA)的目的是找到能用较少信息描述数据集的特征组合。
第六章 使用朴素贝叶斯进行社会媒体挖掘
6.1 消歧
本章我们将处理文本,文本通常被称为无结构格式。文本挖掘的一个难点来自于歧义,比如bank一词多义。本章将探讨区别Twitter消息中Python的意思。
6.2 文本转换器
Python中处理文本的库NLTK(Natural Language Toolkit)。据作者说很好用,可以作自然语言处理。N元语法是指由连续的词组成的子序列。
6.3 朴素贝叶斯
朴素贝叶斯概率模型是以对贝叶斯统计方法的朴素解释为基础。
贝叶斯定理公式如下:
$ P(A|B) = \frac {P(B|A)P(A)}{P(B)} $
贝叶斯公式可以用它来计算个体属于给定类别的概率。朴素贝叶斯算法假定了各个特征之间相互独立,那么我们计算文档D属于类别C的概率为P(D|C)=P(D1|C)*P(D2|C)…P(Dn|C)。贝叶斯分类器是输入数据来更新贝叶斯的先验概率和后验概率,输入贝叶斯模型后,返回不同类别中概率的最大值。
示例:
举例说明下计算过程,假如数据集中有以下一条用二值特征表示的数据:[1, 0, 0, 1]。
训练集中有75%的数据属于类别0,25%属于类别1,且每个特征属于每个类别的似然度如下。
类别0:[0.3, 0.4, 0.4, 0.7]
类别1:[0.7, 0.3, 0.4, 0.9]
拿类别0中特征1的似然度举例子,上面这两行数据可以这样理解:类别0中有30%的数据,特征1的值为1。
我们来计算一下这条数据属于类别0的概率。类别为0时,P(C=0) = 0.75。
朴素贝叶斯算法用不到P(D),因此我们不用计算它。我们来看下计算过程。
P(D|C=0) = P(D1|C=0) x P(D2|C=0) x P(D3|C=0) x P(D4|C=0)
= 0.3 x 0.6 x 0.6 x 0.7
= 0.0756
现在,我们就可以计算该条数据从属于每个类别的概率。需要提醒的是,我们没有计算P(D),因此,计算结果不是实际的概率。由于两次都不计算P(D),结果具有可比较性,能够区分出大小就足够了。来看下计算结果。
P(C=0|D) = P(C=0) P(D|C=0)
= 0.75 * 0.0756
= 0.0567
6.4 F1值
F1值是一种评价指标。F1值是以每个类别为基础进行定义的,包括两大概念:准确率(precision)和召回率(recall)。准确率是指预测结果属于某一类的个体,实际属于该类的比例。召回率是指被正确预测为某个类别的个体数量与数据集中该类别个体总量的比例。F1值是准确率和召回率的调和平均数。
第九章 作者归属问题
9.1 作者归属
作者归属(authorship attribution)是作者分析的一个细分领域,研究目标是从一组可能的作者中找到文档真正的主人。利用功能词进行分类,功能词是指本身含义很少,但是是组成句子必不可少的部分。
9.2 支持向量机
支持向量机(SVM)分类算法背后的思想很简单,它是一种二类分类器(扩展后可用来对多个类别进行分类)。假如我们有两个类别的数据,而这两个类别恰好能被一条线分开,线上所有点为一类,线下所有点属于另一类。SVM要做的就是找到这条线,用它来做预测,跟线性回归原理很像。
下图中有三条线,那么哪一条线的分类效果最好呢?直觉告诉我们从左下到右上的这一条线效果最好,因为每一个点到这条线的距离最远,那么寻找这条线就变成了最优化问题。
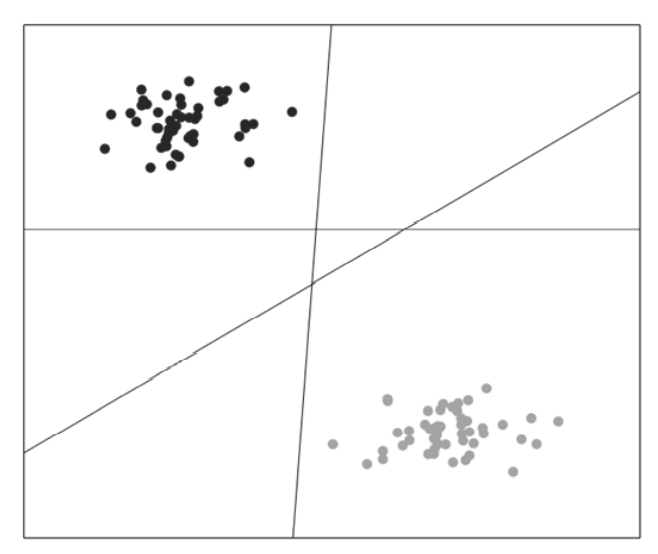
对于多种类别的分类问题,我们创建多个SVM分类器,其中每个SVM分类器还是二分类。连接多个分类器的方法有很多,比如说我们可以将每个类别创建一对多分类器。把训练数据分为两个类别——属于特定类别的数据和其他所有类别数据。对新数据进行分类时,从这些类别中找出最匹配的。
9.3 基础SVM的局限性
最基础的SVM只能区分线性可分的两种类别,如果数据线性不可分,就需要将其置入更高维的空间中,加入更多伪特征直到数据线性可分。寻找最佳分隔线时往往需要计算个体之间的内积。我们把内核函数定义为数据集中两个个体函数的点积。
常用的内核函数有几种。线性内核最简单,它无外乎两个个体的特征向量的点积、带权重的特征和偏置项。多项式内核提高点积的阶数(比如2)。此外,还有高斯内核(rbf)、Sigmoind内核。
第十章 新闻语料分类
10.1 新闻语料聚类
之前我们研究的都是监督学习,在已经知道类别的情况下进行分类。本章着眼于无监督学习,聚类。
10.2 K-means算法
k-means聚类算法迭代寻找最能够代表数据的聚类质心点。算法开始时使用从训练数据中随机选取的几个数据点作为质心点。k-means中的k表示寻找多少个质心点,同时也是算法将会找到的簇的数量。例如,把k设置为3,数据集所有数据将会被分成3个簇。
k-means算法分为两个步骤:为每一个数据点分配簇标签,更新各簇的质心点。k-means算法会重复上述两个步骤;每次更新质心点时,所有质心点将会小范围移动。这会 轻微改变每个数据点在簇内的位置,从而引发下一次迭代时质心点的变动。这个过程会重复执行直到条件不再满足时为止。通常是在迭代一定次数后,或者当质心点的整体移动量很小时,就可以终止算法的运行。有时可以等算法自行终止运行,这表明簇已经相当稳定——数据点所属的簇不再变动,质心点也不再改变时。


Comments