2017年Google团队提出的完全基于attention机制的神经网络结构,是一种全新的网络架构,影响力十分大,后续的BERT, ViT等多个熟知的预训练模型都是由Transformer变体而来,相关链接:
2. Introduction
最开始Transformer是为了解决机器翻译的任务,Transformer没出来前,解决机器翻译主要的手段是RNN和Encoder-Decoder架构,比如说Seq2Seq。RNN的缺点是依赖时间顺序,第一个方面是并行度比较低,第二个方面是如果时序比较长,那么前期的时序信息在后期可能会丢掉。Transformer的特点有: 自注意力、多头注意力。
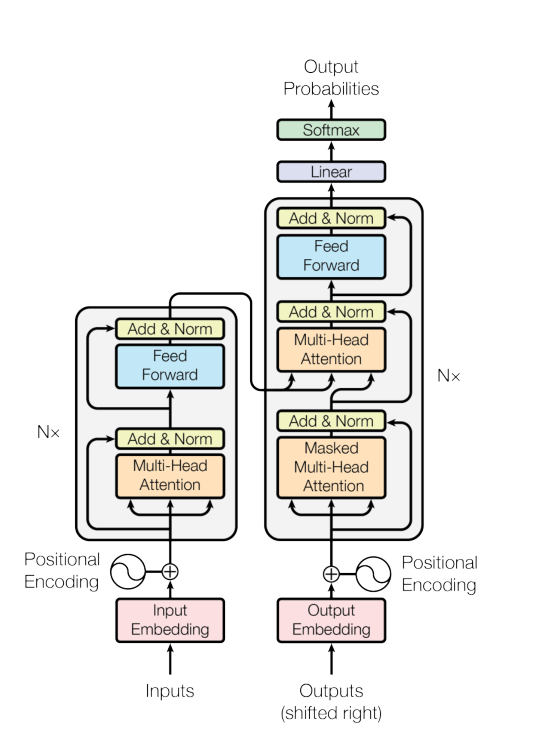
3. 模型架构
模型预览图:
Transformer时序维度始终是512,BatchNorm和LayerNorm的区别: BN是针对一个batch的特征来做平均和方差,LN是针对batch中一个样本的所有特征做均值和方差。一般的Transformer能接受的序列长度最好不超过512,超过这个长度可能会导致硬件算不动
3.1. 注意力
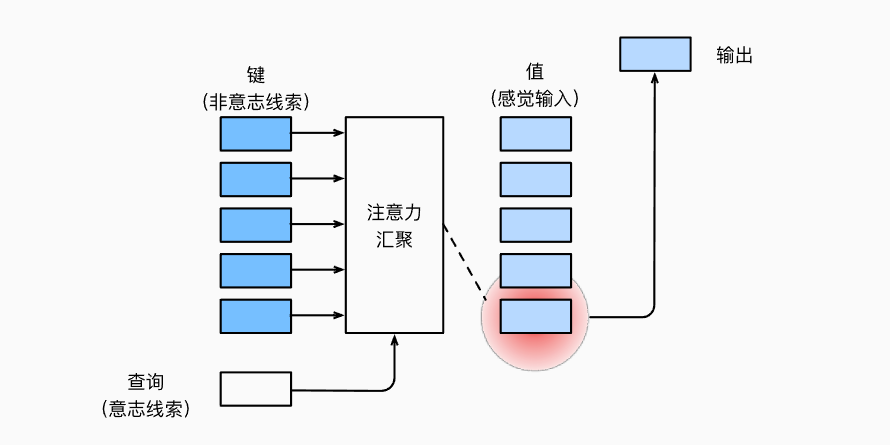
注意力有三要素,query、key、value。对于每个query,计算与其他所有key的compatibility作为value的权重。Transformer使用的计算compatibility的方式是Scaled Dot-Product Attention,也是应用最多的计算方式:
\begin{equation} \text{Attention}(Q,K,V)=softmax(\frac{QK^T}{d_k})V \end{equation}
结合图片理解:
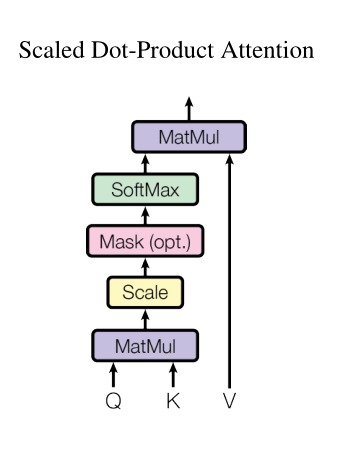
讲道理来说,对于时间步t的查询$q_t$而言,它不应该能看到时间步t后的序列,但是在计算attention的时候却可以看到所有的序列,所以需要有mask来保证序列在预测过程中看不见时间步t之后的序列
3.2. 多头注意力
多头注意力的出发点是让高维的序列能有h次学习机会,这样有机会能学习到更多的信息,假设有h个头,那么维度就需要投影到512/h,然后再做注意力,然后将h个头concatenate,这样就可以实现多头注意力
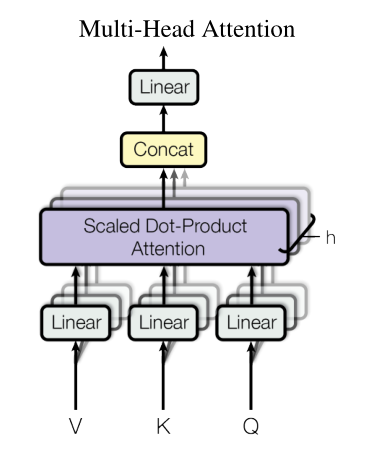
在decoder里,query是当前的输入,k和v都是encoder的输出
3.3. Position-wise Feed-Forward Networks
位置前馈神经网络,其实就是一个基于每个时间步的MLP,由于Transformer里每个时间步都做了attention,所以它包含了序列的信息,所以可以直接针对每个时间步做MLP
3.4. Embedding and softmax
encoder的embedding层和decoder的embedding以及decoder中softmax前的线性层是共享权重的,其中embedding层的权重需要乘以$\sqrt{d_{model}}$(为了保证数值相似)。embedding层最大的作用就是将vocab_size映射到模型的维度
3.5. Positional Encoding
位置编码,因为注意力机制其实是没有考虑序列的位置信息的,它计算的是query和key的距离,所以在输入模型前需要加上位置编码来保证序列的每一步都包含其位置信息,pos表示第几个单词,2i表示对于偶数列,2i+1表示奇数列
\begin{equation} \begin{aligned} \text{PE}_{(pos,2i)} & = sin(pos/10000^{2i/d_{model}}) \\ \text{PE}_{(pos,2i+1)} & = cos(pos/10000^{2i/d_{model}}) \end{aligned} \end{equation}
Transformer的位置编码的做法是利用sin和cos对不同的时间步进行编码,也就是说Transformer的做法是不训练位置编码,作者的解释是相较于训练的位置编码,两者结果相似。
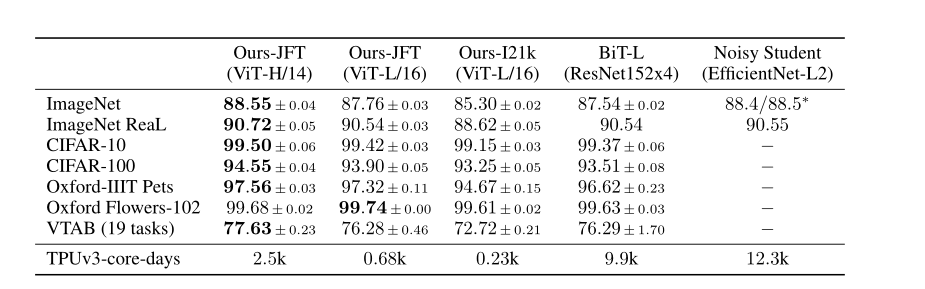
4. 数据集和实验
Transformer解决的是机器翻译任务,数据集为WMT 2014 English-German dataset,分词的时候采取BPE,并且英语和德语共用一个词库,这样保证了encoder和decoer的embedding层一致
...
read more
























 Tandy Color Computer TRS80 III
Tandy Color Computer TRS80 III